1 数据 1. 数据概述 1.1 数据的概念:定义、分类(定性/定量、静态/动态、在线/离线等)P3P4 1.2 数据的分类:根据性质、时间、网络、位置、来源、范围、格式等进行分类P4 2. 数据内容 2.1 实时数据与历史数据:定义、特点、应用P5 2.2 时态数据与事务数据:定义、特点、区别P6P7 2.3 图形数据与图像数据:定义、特点、应用P8P9 2.4 主题数据与全部数据:定义、区别P10 2.5 空间数据:定义、分类(矢量/栅格)P11 2.6 序列数据和数据流:定义、特点P12 2.7 元数据和数据字典:定义、作用P13 3. 数据属性及数据集 3.1 数据属性:定义、分类(标…
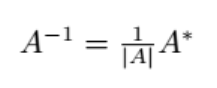
多元统计分析二轮复习 基于ppt

主成分分析 聚类分析 判别分析 H0 多元正态总体的统计推断 T方检验 1 矩阵代数 1.1定义 1.2矩阵运算 1.3行列式 1.4矩阵的逆 矩阵可逆便 行列式不为0 行列式不为0的矩阵叫非奇异矩阵 行列式为0的矩阵叫奇异矩阵 同时不可逆 用化最简行阶梯形也可以做 1.5矩阵的秩 1.6特征值,特征向量,矩阵的迹(这三个概念只有方阵才谈 矩阵的迹 1.7正定矩阵和非负定矩阵 顺序主子式 从矩阵左上角开始,按顺序取1阶、2阶...n阶的行列式 k阶顺序主子式是指:取矩阵左上角的k×k个元素构成的行列式 有趣的性质 主对角线的元素的绝对值 一定比该行 该列 所有其余元素绝对值之和还要大 第一章例…
搜索引擎(vue3+springboot3.4.1+Solr9.7.0+MySQL8.3.0);
https://github.com/mozhongzhou/vue-springboot-solr 写于2024-12-29 架构 前端vue3 后端springboot3.4.1 搜索引擎以及分词系统Solr9.7.0 原始数据库MySQL8.3.0 环境(环境变量等问题不解释) Solr9.7.0 MySQL8.3.0 Maven3.9.9 maven源该改就改,不然很慢 Java 操作系统为Windows11家庭版 配置MySQL(导入测试数据) 按理说生产环节这是最后的步骤,本次放在第一步 利用navicat先建表,然后导入sql,本次测试用sql十分复杂.建议测试时选取简单的数据 …

NLP实验 判断感情
实验目的 众所周知,人类自然语言中包含了丰富的情感色彩:表达人的情绪(如悲伤、快乐)、表达人的心情(如倦怠、忧郁)、表达人的喜好(如喜欢、讨厌)、表达人的个性特征和表达人的立场等等。 情感分析在商品喜好、消费决策、舆情分析等场景中均有应用。利用机器自动分析这些情感倾向,不但有助于帮助企业了解消费者对其产品的感受,为产品改进提供依据;同时还有助于企业分析商业伙伴们的态度,以便更好地进行商业决策。 学习对带有感情色彩的主观性文本进行分析、处理、归纳和推理的过程。 使用仪器、材料 环境:Python 3.12.4 (Anaconda3) 开发工具:Visual Studio Code 实验过程原始记…
机器学习二轮复习框架 基于(CQU复习ppt by gaomin)
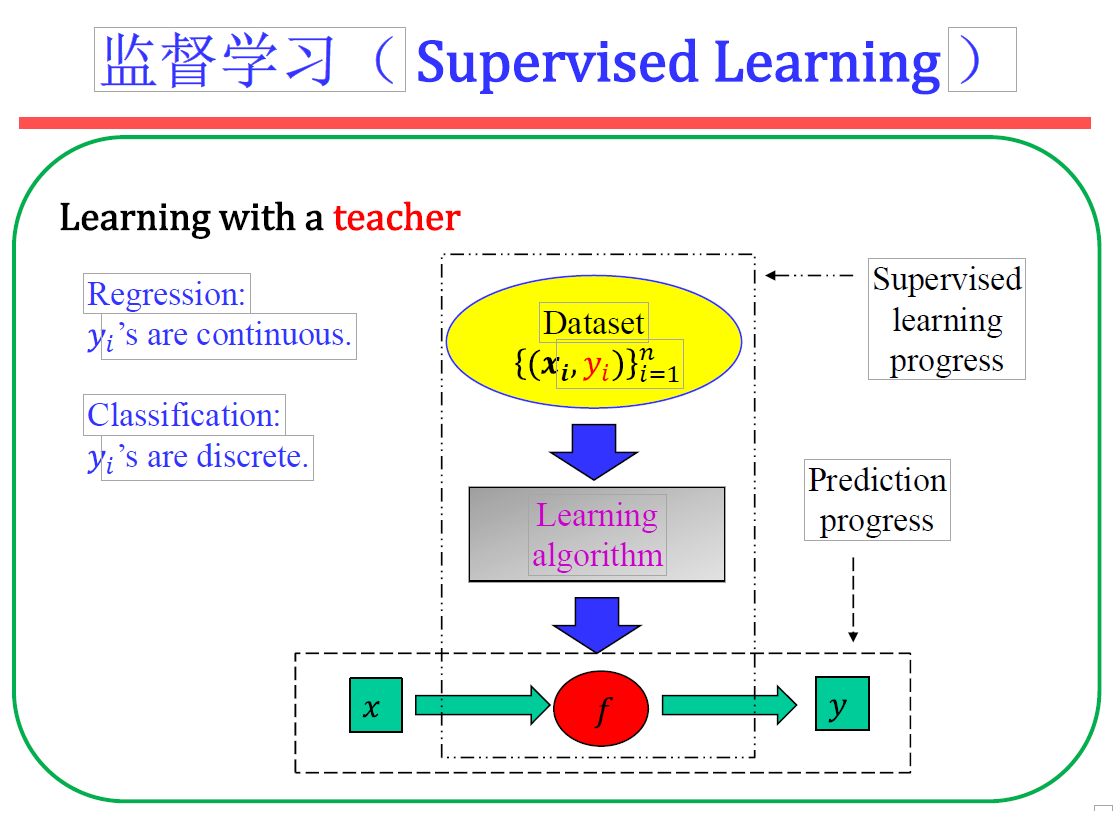
一个有趣的概念 1简要介绍xx模型的定义 给出简要例子说明,不用代码,手动模拟即可 注意在解释的过程中,要对公式的每个符号进行说明解释,要保证科学研究的严谨性 2为了求解这个模型的最优参数,有哪些方法? 给出简要例子说明,不用代码,手动模拟即可 注意在解释的过程中,要对公式的每个符号进行说明解释,要保证科学研究的严谨性 基础知识 要求1:基本概念要求2:数据集划分要求3:性能度量要求4:可以描述任务之间的关系要求5:可以描述各算法的特点,同类任务不同算法的特点及其之间的区别等 基本概念: 这是指你需要理解机器学习的基础知识和术语。例如,什么是监督学习和无监督学习,什么是特征和标签,什么是模型训…

机器学习3h
吴恩达机器学习
数据挖掘DataMining
机器学习简介 机器学习概括 机器学习模型 有监督模型(单模型 线性模型 kmeans 决策树 神经网络 支持向量机) 无监督模型(聚类 降维) 概率模型 (EM MCMC 贝叶斯 ) 机器学习分类 监督学习 分类 回归 无监督学习 聚类 降维 机器学习的方法和流程 模型机器学习首先考虑使用什么模型 模型分为概率模型和非概率模型 概率模型:决策树 朴素贝叶斯 非概率模型:感知机 支持向量机 Kmeans 神经网络 按判别函数的线性与否分为 线性模型 和 非线性模型 线性模型 :感知机 线性支持向量机 Kmeans 非线性模型 : 核支持向量机 神经网络 损失函数 模型预测出来的 和真实的 有差距…
这篇文章没有摘要
数据挖掘(Data Mining)主要讲述了以下内容: 数据预处理:包括数据清洗、数据集成、数据变换和数据归约等步骤,以确保数据质量和一致性。 模式发现:通过算法和技术从数据中提取有用的模式和知识,如关联规则、频繁模式、序列模式等。 分类和预测:使用分类算法(如决策树、支持向量机、神经网络等)对数据进行分类,并使用回归分析等方法进行预测。 聚类分析:将数据分组,使得同一组内的数据对象相似度高,不同组间的对象相似度低。常用算法有K-means、层次聚类等。 异常检测:识别数据中的异常或异常模式,这在欺诈检测、网络安全等领域非常重要。 数据可视化:通过图形和图表展示数据和挖掘结果,帮助理解和解释数…
Machine Learning Project1
0、前期准备 配置anaconda3的环境变量 使用anaconda3 作为python包管理器,把包都存在统一集成环境中,后续在IDE中使用anaconda3的python解释器即可 在创建项目时,使用已有conda的python解释器 1、实现线性回归算法 自己构造数据集 1.1、代码 import numpy as np import matplotlib.pyplot as plt # 设置中文字体,否则图片上的中文会显示成方框 plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体 plt.rcParams['a…

机器学习
有数据 整理数据 选择模型 跑模型 评价模型 优化模型 超参 预测 —————————————————————————— 推荐书目 机器学习-周志华 机器学习公式详解 统计学习方法 李航 机器学习理论导引 Main content 涉及 matlab python 回归模型 线性回归 对数几率回归 降维方法 主成分分析 线性判别分析 支持向量机 决策树 神经网络 K均值聚类 1模型评估与选择 第一章略讲,介绍了假设空间 1.2、基本术语 1.3、假设空间 2模型评估与选择 前三节较为重要 数据为王,数据量越大越好 2.1经验误差与过拟合 2.1.1留出法(划分为两部分) 留出法是一种简单的模型…