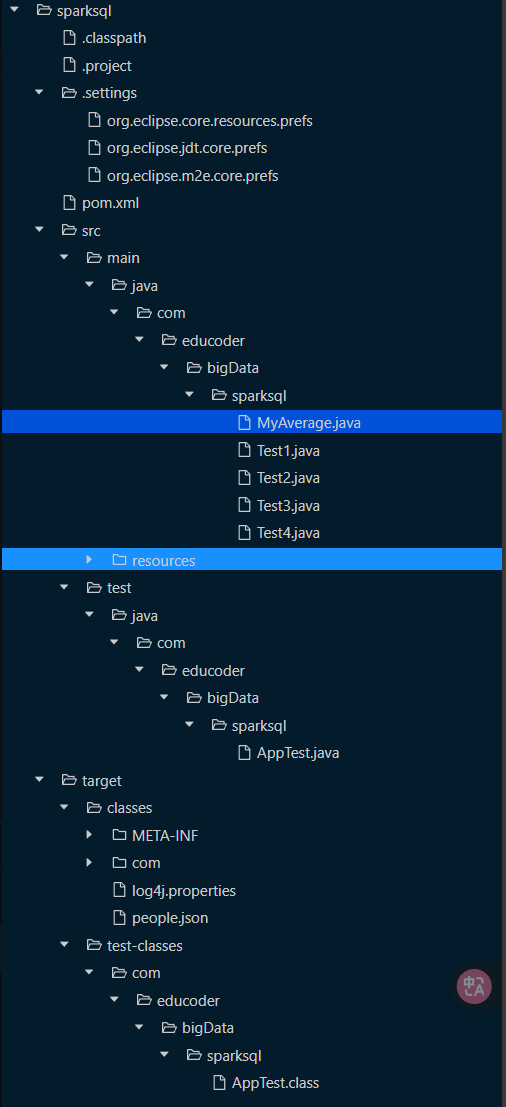
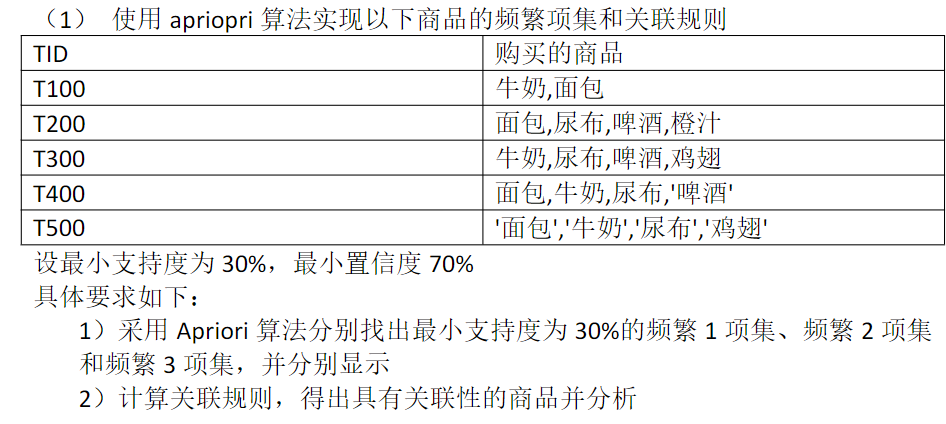
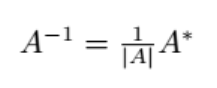1 数据
1. 数据概述
- 1.1 数据的概念:定义、分类(定性/定量、静态/动态、在线/离线等)P3P4
- 1.2 数据的分类:根据性质、时间、网络、位置、来源、范围、格式等进行分类P4
2. 数据内容
- 2.1 实时数据与历史数据:定义、特点、应用P5
- 2.2 时态数据与事务数据:定义、特点、区别P6P7
- 2.3 图形数据与图像数据:定义、特点、应用P8P9
- 2.4 主题数据与全部数据:定义、区别P10
- 2.5 空间数据:定义、分类(矢量/栅格)P11
- 2.6 序列数据和数据流:定义、特点P12
- 2.7 元数据和数据字典:定义、作用P13
3. 数据属性及数据集
- 3.1 数据属性:定义、分类(标称、序数、区间、比率)P14
- 3.2 数据集:定义、特性(维度、稀疏性、分辨率)P14
4. 数据特征的统计描述
- 4.1 集中趋势:定义、测度(众数、中位数、均值)P16
- 4.2 离散程度:定义、测度(异众比率、四分位差、方差、标准差、标准分数、离散系数)P17
- 4.3 分布的形状:定义、测度(偏态、峰态)P18P19
5. 数据可视化
- 5.1 分类数据与顺序数据:可视化方法(条形图、饼图、环形图)P21P22
6. 数据相似与相异性度量
- 6.1 数据的相似度度量:定义、变换方法、常用度量方法(简单匹配系数、Jaccard系数、闵式距离、欧氏距离、余弦度量、广义Jaccard度量、皮尔森相关系数)P23P24P25
7. 数据质量
- 7.1 数据的质量:定义、评价指标、常见问题P28
8. 数据预处理
- 8.1 被污染的数据:定义、分类、来源P30P31
- 8.2 数据清理:原理、步骤、算法P32
- 8.3 数据集成:定义、问题P33
- 8.4 数据交换- 标准化数据:定义、方法(离差标准化、标准差标准化、小数定标标准化)P34P35
- 8.5 数据规约:定义、原因、策略
9. 课堂练习:
- 提供了几个与数据预处理、数据相似性度量、多模态信息处理等相关的练习题。
2 数据中心概述
1. 概述
- 数据仓库和数据挖掘的企业级应用发展历程:
- 传统数据仓库时代P2
- 动态数据仓库时代P2
- 数据中心时代(关系型、非关系型、混合型)P2
- 数据中心概述课程主要围绕数据中心时代展开。
2. 企业与数据分析
- 企业面临的问题和挑战,以及数据分析/挖掘技术的作用。P3
- 数据分析应用场景:
- 银行:信贷风险识别、交叉销售、提升销售P3
- 电信公司:市场分析、竞争环境分析、营销活动提升P3
- 保险公司:理赔客户风险评估、高价值客户群识别P3
- 企业数据分析人才需求:既要懂技术,又要懂业务。
3. 数据仓库和数据挖掘的目标
- 数据治理P5
- 数据共享体系P5
- 多维数据分析P5
- 企业模式挖掘P5
- 企业级数据仓库P5
- IT安全管理P5
- 企业信息单一视图P5
- 数据挖掘和预测分析P5
4. 面临的挑战
5. 发展历程
- 报表查询系统:缺点和局限性P7
- 传统数据仓库技术:ETL工具、ODS、数据集市/仓库、多维分析工具、数据挖掘工具P8
- 传统数据仓库技术优点P9
- 动态数据仓库技术:事件驱动、主动推送、数据模型P10
- 数据中心:差分系统、记录系统、创新系统P11
6. 数据中心
- 关系型数据中心:与动态数据仓库的区别,以业务分析为中心P14
- 非关系型数据中心:管理非结构化数据,企业内容管理,Hadoop平台P15P16
- 混合型数据中心:结合关系型和非关系型数据,大数据平台P18
- 混合型数据中心的重要性:元数据管理和数据治理P19
7. 混合型数据中心参考架构
- 以银行新一代数据中心为例,介绍混合型数据中心的十层架构:
- 用户终端层
- 应用层
- 数据层
- 交换服务体系层
- 数据存储区
- 基础服务层
- 数据治理
- 元数据管理层
- IT安全运维管理
- IT综合监控
- 企业资产管理
- 详细介绍每一层的功能和作用,包括:
- 基础设施层
- 数据源层
- 交换服务体系层
- 数据层
- 应用层
- 数据存储区
8. 数据治理
- 数据治理的概念和作用P38
- 解决信息冗余、冲突、不一致性P38
- 解决信息缺失、错误P38
9. 元数据管理
- 元数据管理的概念和作用P39
- 元数据分析:数据世系分析、影响分析P39
- 元数据管理工具P39
10. IT安全运维管理
- IBM IT安全运维解决方案P42
- 用户管理、用户认证、用户操作日志审计P42
11. IT综合监控
- 信息系统复杂性,业务系统对IT系统的依赖P43
- 业务响应时间、故障处理时间、服务水平要求P43
- 综合监控管理体系P43
12. 企业资产管理
- 设备维护的战略意义P44
- 高水平生产运营管理系统的重要性P44
13. 课后问题
- 数据挖掘选择数据库和数据仓库的差异
- 数据中心的好处和不足
3 数据挖掘理论基础
1. 数据挖掘的起源
- 数据挖掘的兴起背景P3
- 数据挖掘与相关学科的关系P4
2. 数据挖掘的定义
- 广义和狭义的定义P5
- 知识发现的流程P6P7P8
- 角度分析(技术角度和商业角度)P9
3. 数据挖掘的任务
- 分类P11
- 定义和例子P11P12
- 分类与聚类的关系P19
- 回归分析P15
- 相关分析P16
- 聚类分析P17
- 定义和例子P17P18
- 分类与聚类的差别P19
- 关联规则P20
- 异常检测P21
4. 数据挖掘标准流程
- CRISP-DM 流程P22
- 商业理解P23
- 数据理解P24
- 数据准备P25
- 建立模型P26
- 模型评估P27
- 结果部署P28
5. 数据挖掘的十大挑战性问题
- 数据挖掘统一理论的探索P30
- 高维数据和高速数据流的研究与应用P31
- 时序数据的挖掘与降噪P32
- 从复杂数据中找寻复杂知识P33
- 网络环境中的数据挖掘P34
- 分布式数据挖掘P35
- 生物医学和环境科学数据挖掘P36
- 数据挖掘过程自动化与可视化P37
- 信息安全与隐私保护P38
- 动态、不平衡及成本敏感数据的挖掘
4 Python程序语言基础
1. Python 简介
- Python 语言特点:简洁易读、面向对象、多用途性、跨平台、强大的生态系统、可扩展性、入门门槛低P3
- 编译型语言和解释型语言的区别P4
- 安装 Python:官方网站下载、安装步骤、安装 IDEP5
- PyCharm 使用P7
2. 变量类型和运算符
- 变量的定义、命名规则、使用P9
- 变量的重新赋值、类型、删除P10
- 整数类型(int):定义、运算P11
- 浮点数类型(float):定义、运算、科学计数法P12
- 字符串(string):定义、索引、切片、处理方法、转义字符、原始字符串、格式化P13P14
- 布尔类型(bool):定义、运算、转换P15
- input() 函数:获取用户输入P16
- print() 函数:输出内容、重定向、格式化、可变参数P17
- 格式化字符串:占位符、f-string、.format() 方法P18
- 转义字符:常见转义字符示例P19
- 数据类型转换:int()、float()、str()、bool()P20
- 常见的算术运算符:加、减、乘、除、整除、求余、幂P21
- 赋值运算符:=、+=、-=、*=、/=、//=、%=、**=P22
- 位运算符:按位与、按位或、按位异或、按位取反、左移、右移P23
- 比较运算符:等于、不等于、大于、小于、大于等于、小于等于P24
- 逻辑运算符:与、或、非P25
- 运算符优先级和结合性P26
3. 列表、元组、字典和集合
- 序列:定义、常见序列类型(字符串、列表、元组、范围)P27
- 列表(list):创建、访问、修改、切片、添加、删除、拼接、重复、长度P28P29P30
- range() 函数:快速初始化数字列表P31
- 元组(tuple):定义、访问、切片、连接、重复、获取元素数量、查找元素、删除P32
- List 和 Tuple 的区别:可变性、语法表示、使用场景、性能P34
- 字典(dict):定义、访问、删除键-值对、获取键/值/键-值对、格式化字符串P36P37P38
- 集合(set):定义、创建、添加/删除元素、操作(并集、交集、差集、对称差)P39
4. 流程控制、函数、异常处理、调试
- 流程控制:条件语句(if-elif-else)、循环语句(for、while)、异常处理语句(try-except)P41
- if-else 条件语句:语法、注意事项、嵌套、pass 语句、assert 断言P41
- while 循环语句:语法、注意事项、break、continueP46
- for 循环语句:语法、注意事项、else 语句、break、continue
- 推导式(Comprehensions):列表推导式、字典推导式、集合推导式、生成器推导式P55P56
- zip() 函数:配对可迭代对象P58
- reversed() 函数:反转可迭代对象P60P61
- sorted() 函数:排序可迭代对象P62
- Python 函数:定义、调用、参数、返回值、None、局部变量和全局变量、局部函数P65P66
- map() 函数:应用函数到可迭代对象P79
- filter() 函数:过滤可迭代对象P81
- reduce() 函数:累积可迭代对象P83
- lambda 函数:匿名函数P84P85
- Python 异常处理:try-except 语句块、捕获异常、finally 块P86
- Python 程序调试:print()、assert、调试器P89
- Python 多线程:threading 模块、多线程流程P90
5. 基于 Selenium 的爬虫项目
- 爬虫常用的包:Requests、BeautifulSoup、Scrapy、Selenium、PyQuery、Gevent、PySpider、AiohttpP92
- 基于 Selenium 的爬虫:流程、安装、代码示例P93
- 爬虫任务:爬取 ASOS 网站上所有商品数据P94
- 任务分解:逐步分解任务,找到商品链接P95P96P97P98
- 作业:爬取 1000 条商品信息
5 ASOS爬虫
5.1理论
- 1 网络爬虫的概念
- 定义:自动抓取万维网信息的程序或脚本。
- 意义:数据搜集和处理能力是研究和项目必需的,对数据分析行业尤为重要。
- 2 网页结构
- HTML、CSS、JS 构建网页展示和交互。
- HTML:网页展示主体,使用标签定义元素。
- CSS:控制网页元素样式。
- JS:负责前端交互。
- 爬虫主要关注 HTML 数据。
- 3.1 Selenium 库介绍
- Selenium:完整的 web 应用程序测试系统,可模拟真实浏览器,支持多种浏览器。
- 优势:模拟真实浏览器,集成多个库功能,清洗数据方便。
- 定位方法:id、name、class name、tag name、link text、partial link text、xpath、css selector。
- 3.2 使用 Xpath 进行页面定位
- Xpath:快速标记语言,用于精准定位页面元素。
- 常用路径表达式和通配符介绍。
- 3.3 Selenium 库模拟浏览器操作
- 方法:设置浏览器大小、控制浏览器后退/前进/刷新、清除文本、单击元素、提交表单、获取元素属性值、设置元素可见性、返回元素尺寸、获取元素文本。
- 模拟鼠标操作:右击、双击、拖动、鼠标悬停。
- 模拟键盘操作:删除键、空格键、制表键、回退键、回车键、全选、F1-Fn 键。
5.2 实验
1. 实验内容
- 爬取首页的女装/男装类别对应的链接
- 爬取数页打折裙装商品链接
- 爬取商品的信息,包括商品标题、商品代码、品牌、价格、详情描述、图片、颜色等
2. 环境配置
- 最新版本 Selenium 需要 Python 3.8+,且无需下载浏览器驱动
- 环境配置方法
3. 部分代码实现
结果展示
以爬取商品代码为例,基本思路:
在网页中寻找到商品代码
在开发者工具中使用 ctrl+f 搜索其对应的网页源代码,并获取其 Xpath
问答示例:使用大语言模型如 ChatGPT 辅助编写代码
考虑到商品代码需要点击展开按钮后才可见,同时需要该按钮的 Xpath 以进行模拟点击操作
获取到的商品代码和按钮的 Xpath 分别为:
//*[@id='productDescriptionDetails']/div/p
//*[@id='productDescription']/ul/li[1]/div/h2/button
问答示例:商品代码爬取
询问 ChatGPT
最终代码实现(*此处加入对按钮的显式等待)
爬取商品详细信息部分,为 <ul> 列表的情况,基本思路:
在网页中寻找到商品详细信息
在开发者工具中使用 ctrl+f 搜索其对应的网页源代码,并获取该列表和任意一个元素的 Xpath
问答示例:爬取 <ul> 列表
ul 的 Xpath:
//*[@id="productDescriptionDetails"]/div/div/ul
其中一个 li 元素的 Xpath:
//*[@id="productDescriptionDetails"]/div/div/ul/li[2]/text()
问答示例:爬取 <ul> 列表
询问 ChatGPT
最终代码实现
结果展示
问答示例:爬取尺码选择器中的全部尺码
思路:
类似爬取 <ul> 列表,首先定位到尺码选择器
获取选择器和任意一个选项的 Xpath
问答示例:爬取尺码选择器中的全部尺码
询问 ChatGPT
最终代码实现
6 数据预处理
第一部分:Matplotlib使用教程
- Matplotlib 简介
- Matplotlib 是 Python 中最受欢迎的绘图库,由 John Hunter 创建。
- 与 Matlab 的绘图库在功能和语法上有许多相似之处。
- 提供了丰富的示例和画廊。
- Matplotlib 的优点
- 美观:提供多种绘图样式和定制选项,可以创建吸引人的图表。
- 花样多:支持多种绘图类型,如线图、散点图、直方图等。
- 简单易用:提供了大量的函数和参数,方便用户进行绘图。
- Matplotlib 的基本使用
- 导入必要的库:matplotlib.pyplot 和 numpy。
- 创建数据:使用 numpy 创建数据。
- 绘制图表:使用 plot 函数绘制线图。
- 显示图表:使用 show 函数显示图表。
- Matplotlib 的进阶使用
- plot 函数:绘制点或线,支持多种标记样式和线型。
- title 函数:设置图表标题。
- xlabel 和 ylabel 函数:设置横纵坐标标签。
- xlim 和 ylim 函数:设置坐标轴范围。
- xticks 和 yticks 函数:设置坐标轴刻度。
- legend 函数:添加图例。
- savefig 函数:保存图表。
- grid 函数:添加网格线。
- subplot 函数:创建多个图表。
- text 函数:添加文本。
- hist 函数:绘制直方图。
- bar 和 barh 函数:绘制条形图。
- errorbar 函数:绘制带误差线的图表。
- Matplotlib 的面向对象绘图
- 创建 Figure 对象。
- 创建 Axes 或 Subplot 对象。
- 使用 Axes 对象的方法创建各种类型的 Artists。
- Matplotlib 的快速绘图方法
- 使用 pylab 模块快速绘制图表。
第二部分:Pandas数据预处理
- Pandas 简介
- Pandas 是一个开源的数据分析工具,提供了丰富的数据结构和数据操作功能。
- 核心数据结构:DataFrame 和 Series。
- Pandas 数据的读写
- 读取数据:使用 read_csv 等函数读取数据。
- 写数据:使用 to_csv 等函数写入数据。
- 合并数据
- 横向堆叠:使用 concat 函数横向堆叠 DataFrame。
- 纵向堆叠:使用 concat 函数纵向堆叠 DataFrame。
- 数据清洗
- 缺失值处理:删除、替换、插值。
- 异常值处理:删除、替换、箱线图识别。
- 重复值处理:删除重复值。
- 数据标准化
- 离差标准化:将数据缩放到 [0, 1] 或 [-1, 1] 区间。
- 标准差标准化:将数据缩放到均值为 0、标准差为 1。
- 小数定标标准化:将数据缩放到 [-1, 1] 区间。
- 数据转换
- 哑变量:将类别数据转换为二元变量。
- 离散化:将连续型数据转换为离散型数据。
- 小结
- 数据预处理是数据挖掘的重要步骤。
- Pandas 提供了丰富的数据预处理功能。
- 选择合适的方法进行数据预处理。
第三部分:数据预处理-理论
- 为什么要预处理数据
- 数据质量的重要性。
- 数据错误的不可避免性和危害性。
- 数据预处理的形式
- 数据清洗:删除缺失值、平滑噪声、识别或删除离群点。
- 数据集成:合并多个数据源中的数据。
- 数据变换:规范化和聚集。
- 数据归约:简化数据。
- 描述性数据汇总
- 度量数据的中心趋势和离散程度。
- 描述数据汇总的图形显示。
- 数据清洗
- 缺失值处理:删除、替换、插值。
- 噪声数据:分箱、回归、聚类。
- 异常值处理:删除、替换、箱线图识别。
- 数据集成和变换
- 数据集成:实体识别、属性冗余。
- 数据变换:平滑、聚集、泛化、规范化、属性构造。
- 数据归约
- 数据归约策略:数据立方体聚集、属性子集选择、维度归约、数值归约、离散化和概念分层。
第四部分:数据预处理-实验
- 常见的数据预处理方法
- 数据清洗:缺失值处理、异常值处理、重复值处理。
- 数据集成和变换:实体识别、属性冗余、数据变换。
- 数据归约:属性规约、数值归约、离散化和概念分层。
- Python 常用数据预处理函数
- 数据查看相关方法:head、tail、info、describe。
- 数据选择相关方法:loc、map、apply。
- 数据合并相关方法:merge、concat。
- 数据分组相关方法:groupby。
- 数据转换相关方法:get_dummies。
- 上机实验
- 实验目的:熟悉数据预处理的流程和函数。
- 实验内容:缺失值处理、异常值检测、特征筛选、属性规约、数据转换。
- 实验案例:泰坦尼克号数据集、京东商城电热水器评论数据。
7 数据标注
第一章:数据标注概述
- 什么是数据标注?P3
- 数据标注的起源和发展P3P4
- 数据标注对象:语音、图像、文本、视频P7
- 数据标注工具:语音、图像、视频、文本P12P13P14
- 数据标注典型技术:语音转写、图像分割、人脸检测、关键点检测P21
- 数据标注工程:数据采集、数据处理、数据标注、数据质检、数据验收交付P26
第二章:数据采集与清洗
- 数据采集方法:系统日志、互联网数据、APP移动端数据、数据服务机构合作P35
- 数据采集流程P36
- 常见标注数据采集
- 数据清洗:数据预处理方法、数据清洗策略、数据清洗流程、MapReduce数据去重P38P39
第三章:3D点云标注
- 3D点云简介:点云的获取方法、点云的获取方法、点云的应用、点云典型数据集P43P44P47
- 3D点云标注工具:界面布局和操作
第四章:视频数据标注
- 视频数据标注简介:视频数据标注的意义、视频数据标注任务、视频源数据管理P58P60
- 视频数据标注工具:标注框标注、视频帧标注、属性标注、视频跨帧追踪P62
- 视频数据标注流程P65
- 典型视频数据标注方法:视频属性标注
- 标注准确率计算
第五章:图像数据标注
- 图像数据标注的目的与发展P69
- 图像数据标注规范:图像数据标注中的角色、图像数据标注流程、图像数据标注工具P70P71
- 图像数据标注场景:自动驾驶、智慧医疗、智能安防P72
- 图像数据标注形式分类:关键点标注、矩形框标注、图像分割、属性标注P73
- 关键点标注项目的应用及发展前景
- 关键点的标注内容
- 标注结果数据格式
- 关键点标注工具简介
- 关键点标注难点及分析
- 标注框标注:标注框标注、框标注适合的场景、框标注标注难点及分析
- 图像区域标注:图像区域标注、图像区域标注适合的场景、图像区域标注工具简介
- 图像区域标注工具简介
- 图像区域标注难点及分析
第六章:文本数据标注
- 文本数据标注发展与研究现状P94
- 文本数据标注类型:序列标注、关系标注、属性标注、类别标注
- 标注流程:预处理、标注、线上标注、线下标注、质检、验收、数据处理和数据交付
- 交付格式:文本标注质量标准
- 应用场景:新零售、客服行业、广告营销、金融行业、医疗行业P99
- 文本数据标注工具:Doccano、YEDDA、Chinese-Annotator、IEPY、DeepDive、BRAT
第七章:语音数据标注
- 语音数据标注发展现状
- 语音信号基础:认知语音信号、数字化语音信号
- 语音标注任务分类
- 常见的数据异常:丢帧、切音、吞音、喷麦、重音、空旷音、混响
- 基本标注规范:语音段落截取、有效语音判定、语音内容转写、说话人属性标注
- 典型语音标注工具:Praat语音学软件
- 语音数据标注平台:数加加语音数据标注平台的操作界面、语音数据标注平台的基本框架
- 语音数据标注整体流程:语音采集、数据预处理、语音数据标注、数据质检与数据交付
第八章:数据标注工程化管理和质量控制
- 工厂设计与管理架构:数据标注工厂的办公区域划分、数据加工从业务性质上可以划分为三个部分
- 项目管理与订单管理:数据标注项目、数据标注项目实施流程、数据标注订单管理流程图
- 安全控制与质量管理体系:数据存储安全管理要求、工厂人员行为管理、溯源体系建设、质量管理体系建设
- 质量检验方法与标准:数据质量影响算法效果、图像标注质量标准、语音标注质量标准、文本标注质量标准
- 数据标注质量检验方法:实时检验方法、全样检验方法、抽样检验、多重抽样检验
8 推荐系统
第一章:推荐系统概述
- 信息过载问题
- 互联网信息爆炸,用户难以找到感兴趣的信息。
- 推荐系统与搜索引擎的区别:推荐系统无需用户明确需求,主动推荐信息。
- 长尾效应:推荐系统发掘冷门物品,满足个性化需求。
- 推荐系统的发展史
- 探索性阶段:GroupLens系统提出“协同过滤”概念。
- 商业化阶段:Netflix百万美元竞赛推动推荐系统发展。
- 大爆发阶段:深度学习应用和基于上下文的推荐。
- 推荐系统的分类
- 基于用户/物品/模型
- 基于内容/协同过滤/混合推荐
- 其他推荐技术:深度学习、关联规则等
第二章:基于内容的推荐系统
- 原理和特点
- 分析用户喜好,推荐相似物品。
- 需要物品特征描述。
- 长尾效应,发掘冷门物品。
- 物品表示方法
- 布尔向量模型
- TF-IDF向量模型
- 数值特征的缩放变换
- 用户-物品评价模型
- 用户对物品的评分
- 用户-物品评价矩阵
- 稀疏矩阵问题
- 推荐算法
- 基于向量空间模型的推荐
- 最近邻方法
- 余弦相似度
- 评分预测:RMSE、MAE
第三章:基于协同过滤的推荐系统
- 原理和特点
- 基于用户/物品相似度
- 协同过滤的基本概念
- 用户-物品评价模型
- 稀疏矩阵问题
- 基于用户的协同过滤
- 近邻选择
- 推荐产生
- 基于物品的协同过滤
- 相似性度量
- 均值中心化
- 推荐产生
- 基于模型的协同过滤
- 简单评分模型
- 朴素贝叶斯分类
- 线性回归
- 马尔科夫决策过程
- 其他模型:Gibbs抽样、概率相关、极大熵
第四章:混合推荐算法
- 混合推荐的优势
- 结合多种推荐技术的优点
- 解决单一算法的局限性
- 其他推荐技术
- 基于关联规则
- 基于知识的推荐
第五章:基于图结构的推荐算法
- 图神经网络(GNN)
- 图神经网络原理
- GNN在推荐系统中的应用
- 基于GNN的推荐系统分类:一般推荐、序列化推荐
- 基于GNN的推荐系统的未来研究方向
第六章:推荐系统的评价方法
- 用户满意度
- 用户调查
- 用户对推荐结果的反馈
- 预测准确度
- 评分预测:RMSE、MAE
- 推荐列表准确度
- 覆盖率
- 推荐物品多样性
- 信息熵、基尼系数
- 多样性
- 推荐结果的多样性
- 用户对多样性的感知
- 信任度
- 提高推荐系统透明度
- 利用社交网络信息
- 实时性
- 推荐列表更新
- 新物品推荐
- 健壮性
- 抗击作弊能力
- 模拟攻击评测
第七章:推荐系统存在的问题
- 鲁棒性
- 托攻击检测
- 社会化攻击模型
- 冷启动问题
- 用户冷启动
- 物品冷启动
- 缓解方法:调查问卷、混合方法、基于标签、基于社区、基于关联规则或聚类
- 隐私问题
- 用户隐私保护
- 缓解方法:混合方法、模糊处理、分布式协同过滤
- 移动信息系统上的推荐
- 移动设备特点
- 推荐系统挑战:位置、时间、用户心情
- 隐私保护
- 大数据处理与算法可扩展性
- 大规模数据集处理
- 动态数据更新
- 推荐的多样性和新颖性
- 提高多样性方法
- 准确性与多样性关系
- 推荐解释性
- 跨领域推荐系统
- 整合不同系统数据
- 提高推荐准确性
- 融合用户的长期兴趣和短期兴趣
- 用户兴趣变化
- 满足短期兴趣,不伤害长期兴趣
- 社会推荐
- 社会关系对推荐的影响
- 整合社交网络数据
- 社会推荐挑战
9 CNN卷积神经网络
第一章:数据挖掘概述
- 深度学习前言
- 卷积神经网络,CNN
- CNN+Mnist数据集
- CNN+Cifar10数据集
- 人脸识别系统
第二章:卷积神经网络(CNN)
- 数据挖掘、人工智能、机器学习、深度学习的关系
- 人工智能
- 机器学习
- 深度学习
- 数据挖掘
- 神经网络兴衰史
- 第一次兴起:感知机
- 第二次兴起:BP神经网络
- 第三次兴起:深度学习
- 第四次兴起:ChatGPT等智能AI模型
- 人脑视觉机理
- 大脑神经元的信号传输
- 大脑识别物体过程
- 特征表示
- 特征表示的分层
- 深度学习
- 卷积神经网络
- CNN的应用
- CNN的模型演变
- CNN的基本单元:卷积
- CNN的基本单元:卷积核介绍
- CNN的基本单元:非线性(激活层)
- CNN的基本单元:池化层
- CNN的基本单元:全连接层
- 梯度下降
- 梯度下降-相关概念
- 梯度下降-梯度下降法
- 前向传播和反向传播
- 前向传播和反向传播的理解
- 反向传播过程(卷积核参数的优化)
- CNN模型的训练
- CNN模型的训练-方法
- CNN模型的训练—三种梯度下降法法的对比
第三章:CNN识别MNIST数据集
- Mnist数据集简介
- 数据的下载、保存、载入
- 数据示例
- CNN 识别mnist 数据集
- 准确率随epoch改变图
第四章:GoogLeNet识别CIFAR10数据集
- cifar10数据集简介
- cifar10样本示例
- GoogLeNet简介
- Inception模块
- GoogLeNet网络结构
- cifar10数据读取
- GoogLeNet 识别cifar10数据集
- 测试集准确率为:ACC= 93.320%
第五章:利用Facenet和Retinaface实现人脸识别
- 如何实现人脸识别
- Retinaface介绍
- Facenet介绍
- 进行人脸识别
- 运行encoding.py进行人脸数据集编码。
- 运行predict.py进行人脸图片的预测。
10 NLP典型应用
第一章:NLP的典型应用
- NLP的典型应用
- 用户的情感分析
- 信息抽取
- 问答系统
- 机器翻译
- 对话系统
- NLP深度学习任务流程
第二章:信息抽取
- 信息抽取
- 信息抽取应用广泛
- 什么是信息抽取
- 根据抽取结果在不在原文中对信息抽取分类
- 根据抽取结果结构对信息抽取分类
- 信息抽取的通用评测指标
- 抽取模型的关键要素:解码设计
- 实体抽取
- 关系抽取
- 事件抽取
第三章:问答系统
- 问答系统
- 问答系统的定义
- 问答系统的广泛应用
- 搜索场景下的问答系统
- 机器阅读理解
- 阅读理解模型存在的问题
- 检索模型
- 结构化数据问答
第四章:机器翻译
- 机器翻译
- 机器翻译做什么?
- 机器翻译质量的自动评价
- 神经网络机器翻译
- 神器出现 Transformer
- Self Attention计算示例
- 多语言翻译
- 多领域翻译
- 多模态翻译
第五章:对话系统
- 对话系统
- 常见的对话系统
- 任务型对话的应用——智能家居
- 任务型对话的应用——车载出行
- 开放域对话系统
第六章:NLP深度学习任务流程
- 深度学习任务流程
- 数据集准备 – 数据处理 – 组网 – 模型训练&评估 – 模型预测&部署
第七章:用户情感分析
- 用户情感分析
- 用户情感分析
时间序列预测(空调负荷预测
第一章:实验简介
- 实验目的
- 探索空调用电负荷预测的方法
- 学习并应用随机森林、XGBoost、LSTM等预测模型
- 理解指标评价体系
- 进行实验对比、可视化及结果分析
- 数据挖掘需求
- 历史数据分析
- 特征工程
- 模型选择
- 模型训练与评估
- 实时预测
- 优化控制
第二章:数据预处理
- 数据预处理的重要性
- 数据决定了机器学习的上限,而算法只是尽可能逼近这个上限
- 特征工程
- 特征构建
- 特征提取
- 特征选择
第三章:预测模型
- 随机森林 (Random Forest)
- 算法原理
- 构造方法
- 优点
- 应用
- XGBoost
- 分类回归树 (CART)
- 集成学习树
- 算法思想
- 优点
- 应用
- LSTM (Long Short-Term Memory)
- 循环神经网络 (RNN)
- LSTM 的特点
- 优缺点
第四章:指标评价体系
- 评价指标 (Metrics)
- 均方误差 (MSE)
- 平均绝对误差 (MAE)
- R2 分数
- 可视化预测结果
- 时间序列特定指标
第五章:实验对比、可视化及结果分析
- 数据集
- 个人家庭用电数据集
- 数据探索分析
- 时间范围的分析
- 功率变化
- 变量相关性
- 模型结果视图
- XGBoost 结果视图
- Arima 结果视图
- LSTM 结果视图
第六章:数据挖掘实验-逐时负荷预测
- 实验内容
- 数据预处理
- 模型选择与训练
- 模型评估
第七章:周作业提交形式
- 实验报告+代码
- 实验方案
- 代码实现
第八章:总结
- 数据挖掘在空调用电负荷预测中的应用
- 模型选择
- 模型训练
- 模型评估
- 实时预测
第九章:展望
- 未来研究方向
- 更先进的预测模型
- 多源数据融合
- 优化控制策略
社交媒体热点挖掘
第一章:实验简介
- 实验名称: 实时发现微博中的热点实验
- 实验时间: 2024年秋季
- 主讲教师: 周魏
- 联系方式: zhouwei@cqu.edu.cn
第二章:实验背景及方案
- 实验背景
- 社交媒体时代,微博成为重要信息来源
- 研究社交媒体热点挖掘的重要性
- 实验目标
- 获取微博热搜榜单实时数据
- 可视化展示热点话题
- 保存不同时期的舆论热点
- 实验方案
- 爬取微博热搜榜前20热搜事件、排名与热度
- 使用Python程序实现
- 数据清洗、可视化操作
第三章:网络爬虫
- 网络爬虫原理
- 爬虫定义及工作流程
- 种子页面、链接抓取、内容分析、链接跟踪
- 网络爬虫实现
- 编程语言选择 (Python)
- 常用库:requests、BeautifulSoup、lxml
- 代码示例
- 网络爬虫困难及解决办法
- 反爬虫机制 (IP代理、模拟浏览器行为)
- 性能问题 (异步请求、分布式爬虫)
- 法律风险 (了解法律法规、获取授权)
第四章:数据清洗
- 数据清洗定义
- 数据处理和加工,提高数据准确性和可靠性
- 数据清洗技术
- 数据去重、缺失值处理、异常值处理、数据标准化、数据转换、数据验证
- 常用工具: numpy、pandas
第五章:中文分词及停用词处理
- 中文分词
- 中文分词定义及重要性
- 常用库:jieba
- jieba库功能:分词模式、自定义词典、关键词提取、词性标注、并行分词
- 停用词处理
- 停用词定义及处理方法
第六章:数据可视化
- 数据可视化定义
- 数据图形化表示,帮助理解数据
- 数据可视化流程
- 数据收集、数据清洗、数据分析、图表设计、图表优化、图表展示
第七章:实时发现微博热点实验
- 实验内容
- 数据预处理
- 模型选择与训练
- 模型评估