前置知识
pypi 清华镜像源使用
网址:https://mirrors.tuna.tsinghua.edu.cn/help/pypi/
临时使用:pip install -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple some-package将镜像源设为默认:
# 先升级pip, 然后进行配置
python -m pip install --upgrade pip
pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple配置多个镜像源:
pip config set global.extra-index-url "<url1> <url2>..."
pip config set global.extra-index-url "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple"CUDA相关知识
现在cuda已经不支持conda下载,需要pip下载。
去https://pytorch.org/找自己对应的版本
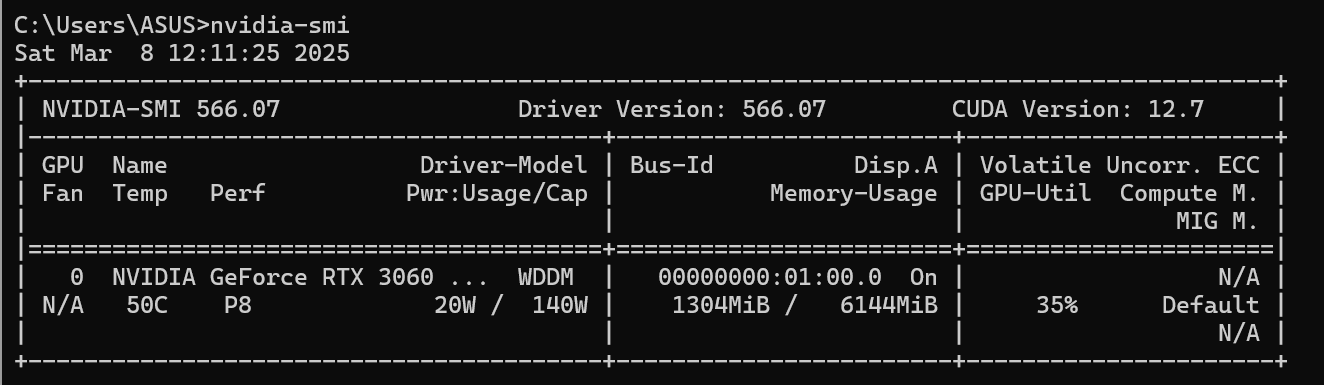
如何查看自己的cuda版本? 参考:https://blog.csdn.net/bruce_zhao1407/article/details/109580835
cmd 输入 nvidia-smi
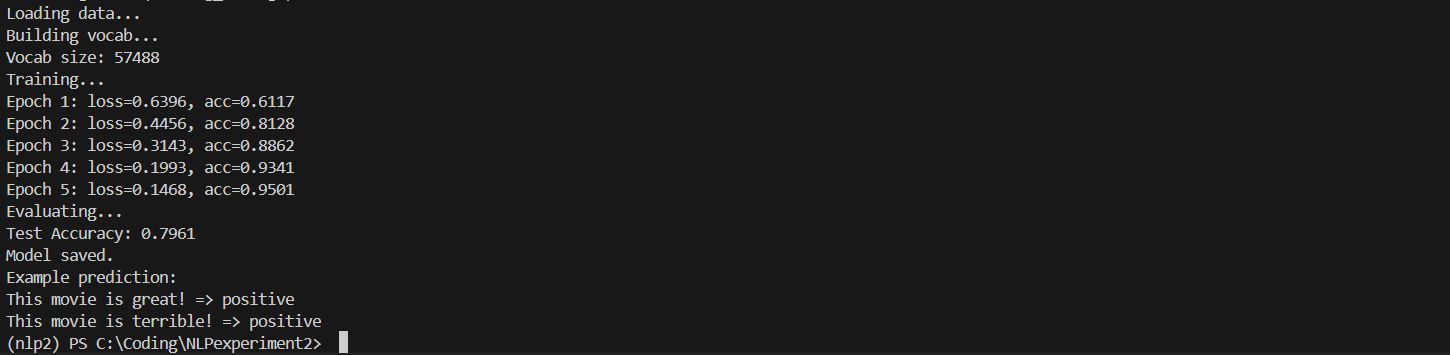
cuda 12.8 pip 下载torch命令
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu128下载完成后,检查torch版本
import torch
torch.__version__ # pytorch 版本
torch.cuda.is_available() # 检查CUDA是否可用
torch.version.cuda # 打印pytorch支持的CUDA版本
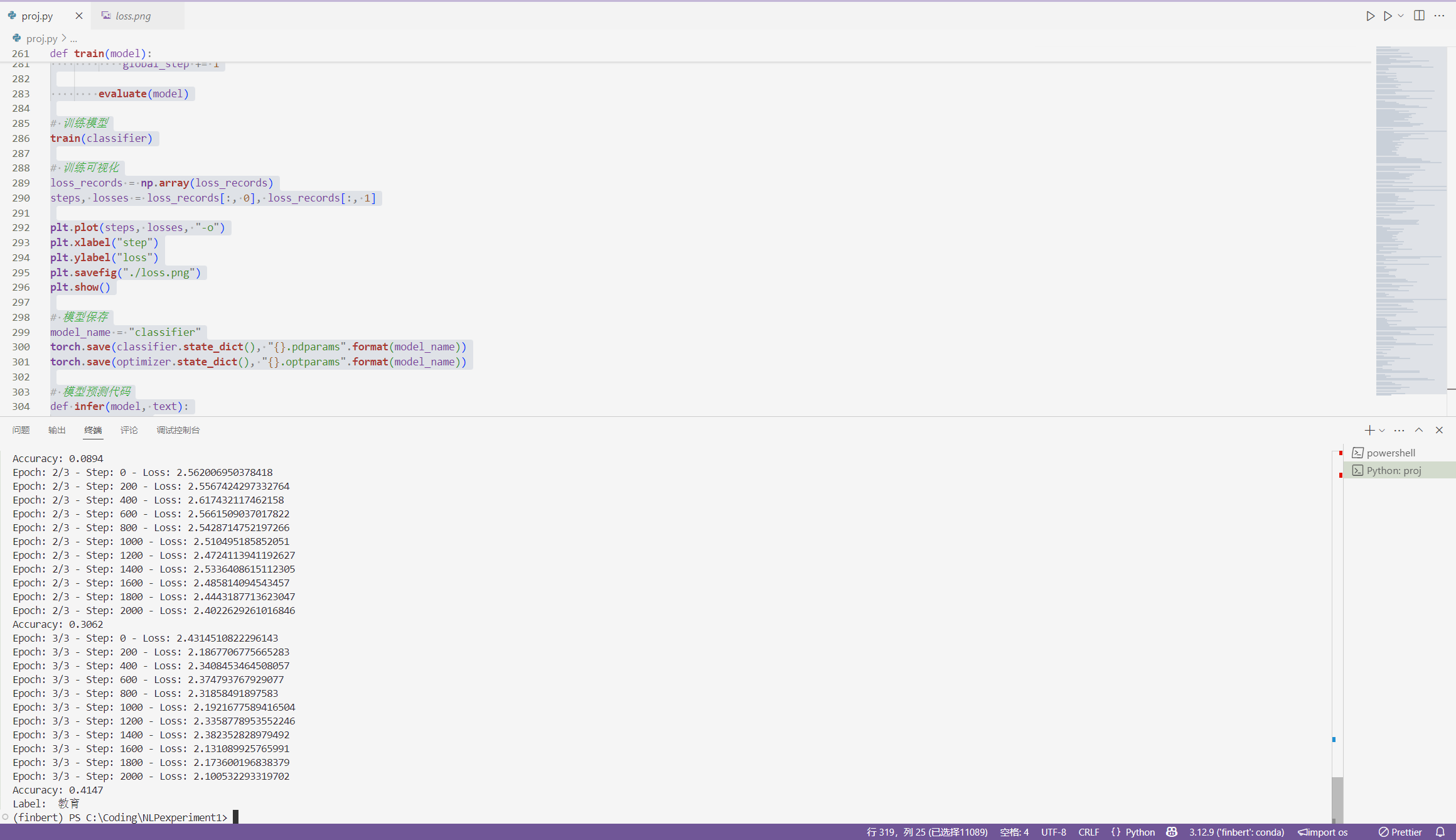
NLP 入门
词向量 Word2Vec, 参考https://blog.csdn.net/v_JULY_v/article/details/102708459
Word2Vec 简单来讲就是用Vector来表示一个单词。
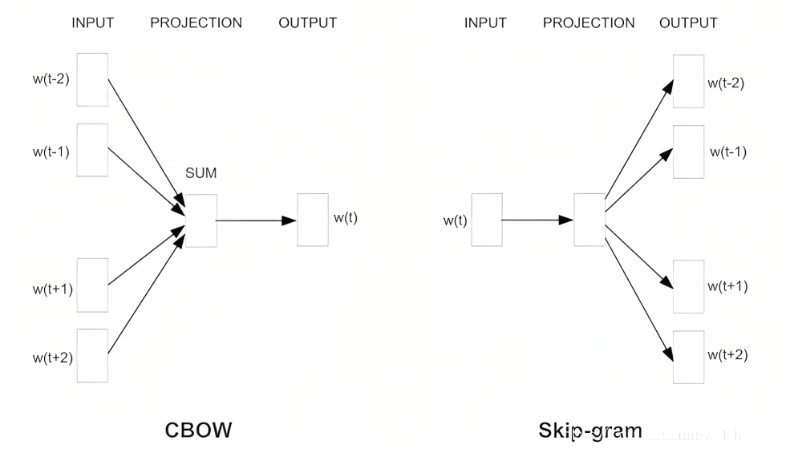
有两种模型CBOW和SkipGram
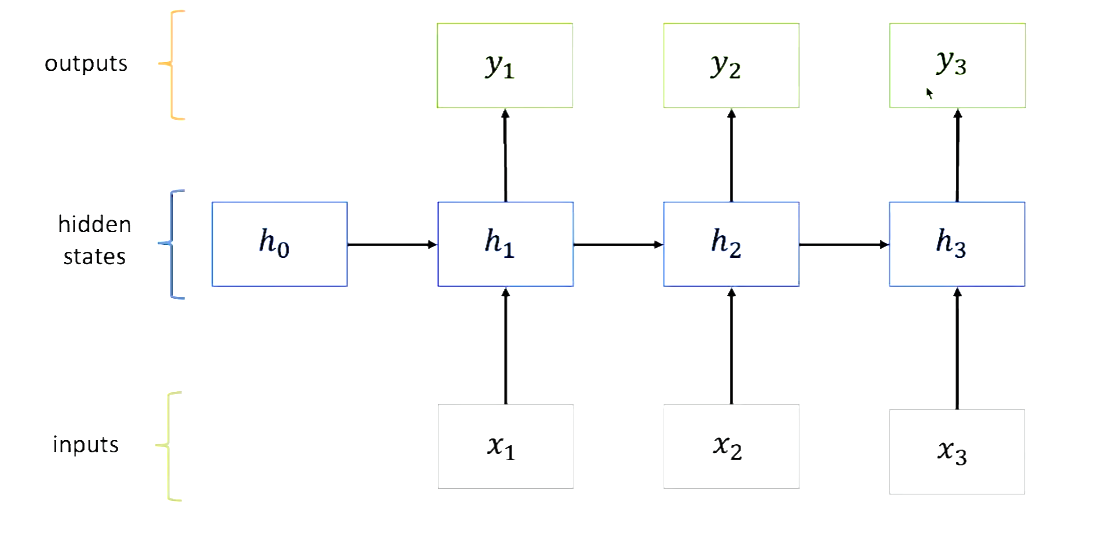
RNN(Recurrent Neural Network)
参考链接:https://blog.csdn.net/weixin_45591044/article/details/104659782
前向传播公式:
h: 激活函数一般是tanh,也可以是ReLU, U是inputs x的weight, W是hidden states h的weight. b是bias
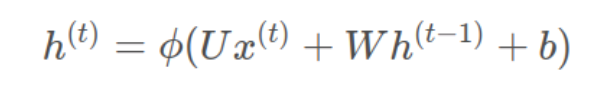
y:这里的激活函数一般是softmax
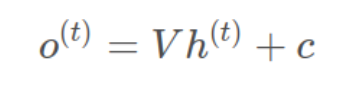
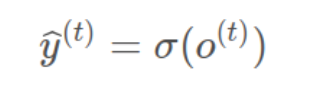
当hidden states变多了过后,会出现梯度爆炸,或者梯度消失的问题。这时需要GRU或者LSTM。
Transformer: Attention is all you need
Attention
Seq2Seq The Bottleneck Problem.
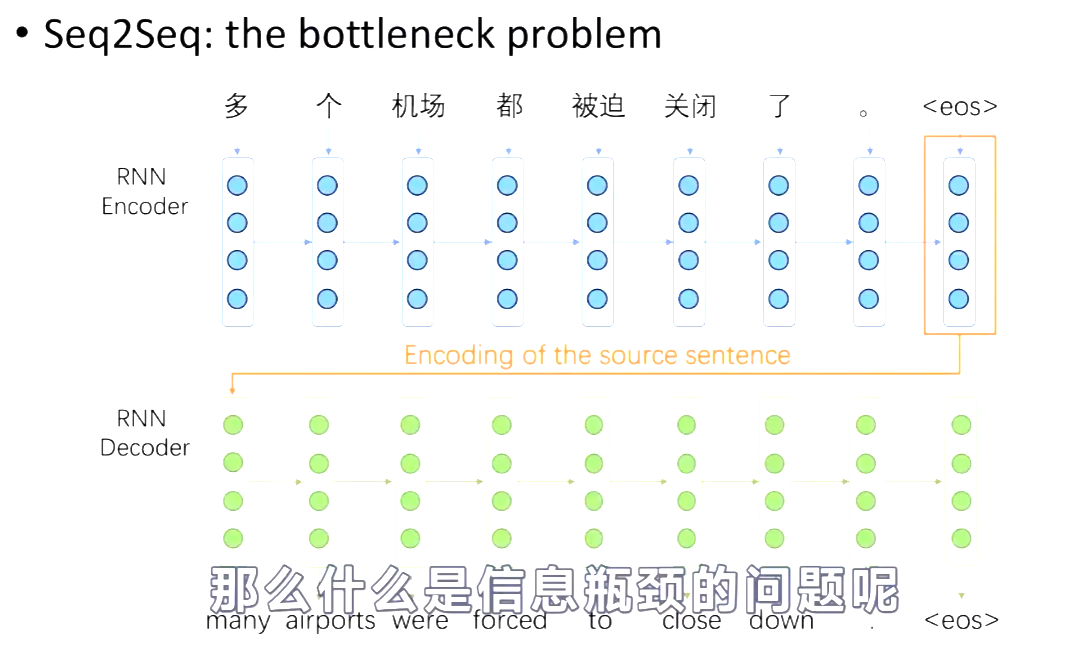
Decoder端需要从Encoder端最后一个输出得到输入,那么就要求Encoder端的最后一个输出需要包含前面所有的信息。但是这么一个Vector,不能完全表达。
Attention 就是可以解决 the bottleneck problem。核心思想就是在decoder的每一步,focus on a particular part of the source sequence.
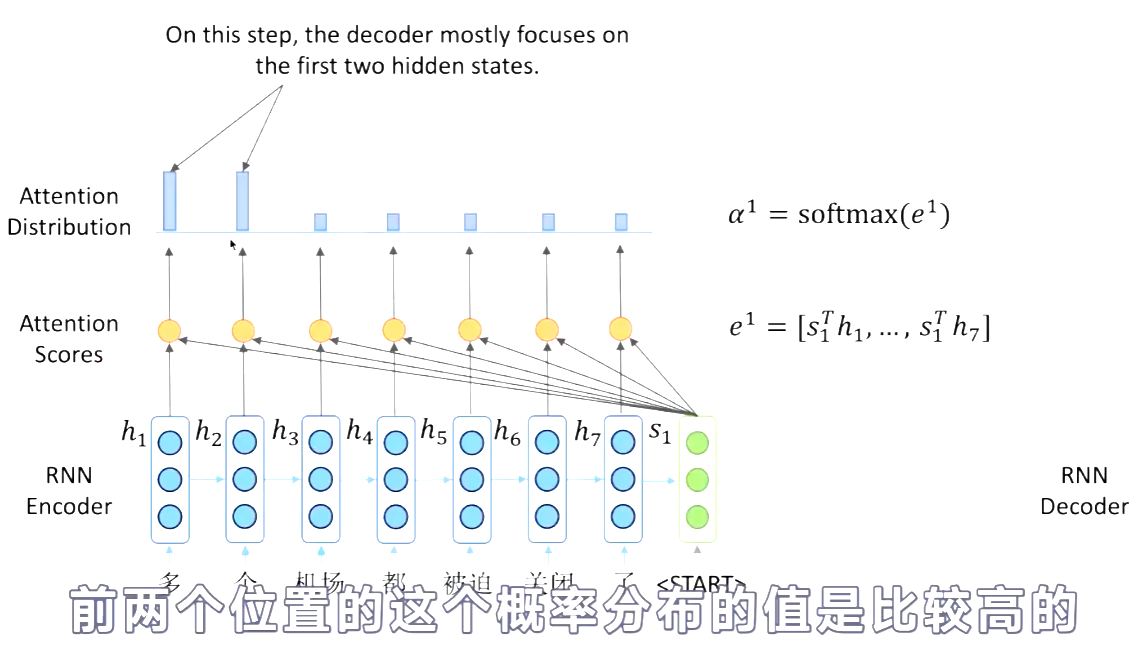
Attention Score 就表示decoder端的某一个位置与encoder的所有hi的一个相似程度。再对Attention Scores进行softmax,得到概率分布。概率值越大的hidden state,说明decoder更focus on 他。

将计算得到的o1与s1拼接,得到输出->many.
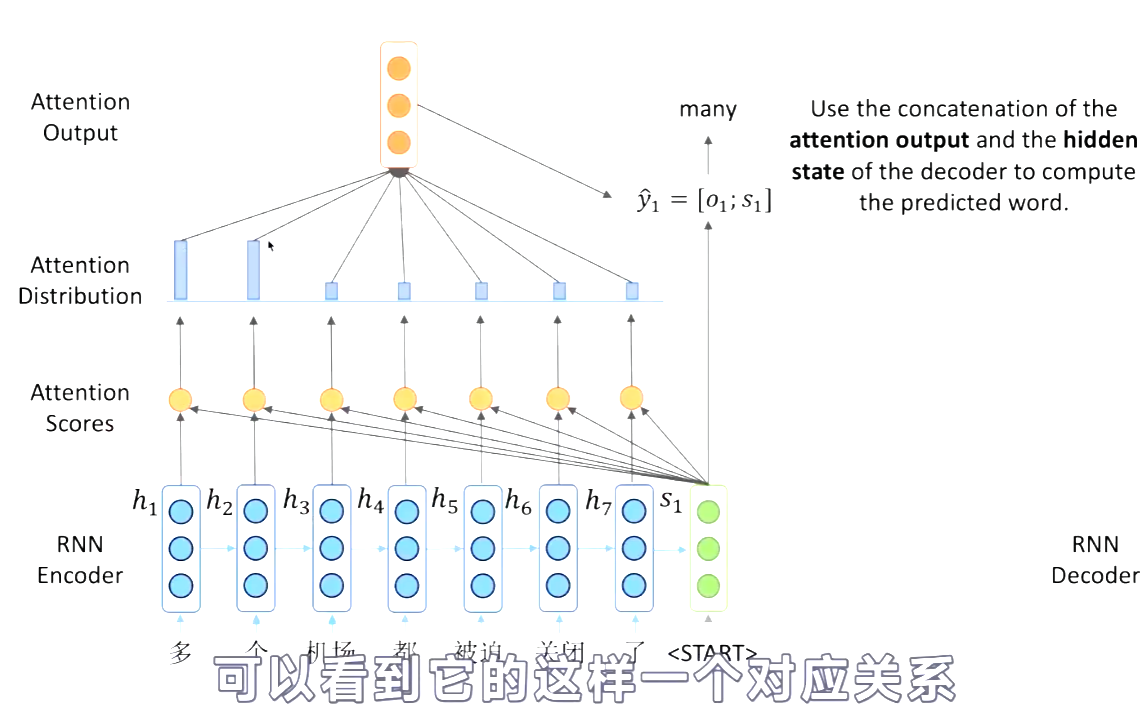
形式化总结:


Transformer Structure
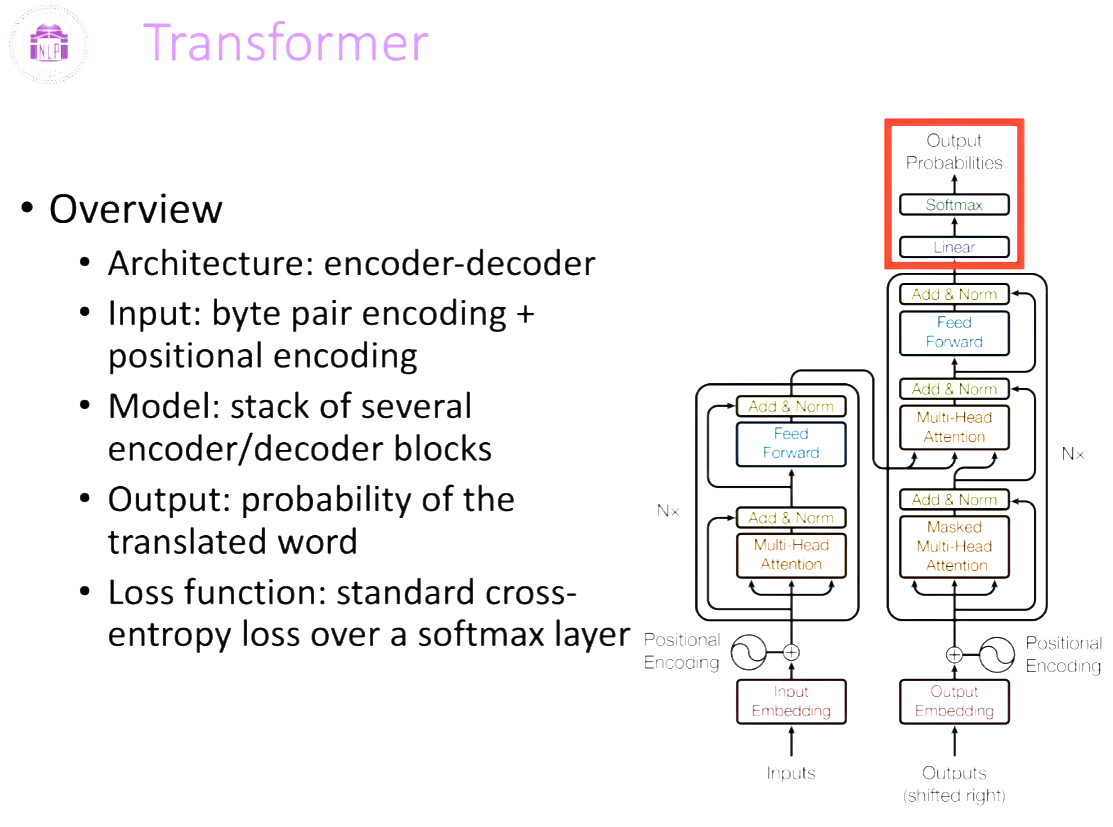
Architecture Overview: encoder-decoder
输入: byte pair encoding + positional encoding
模型: stack of several encoder/decoder blocks
输出:probability of the translated word
Loss function: standard cross-entropy loss over a softmax layer
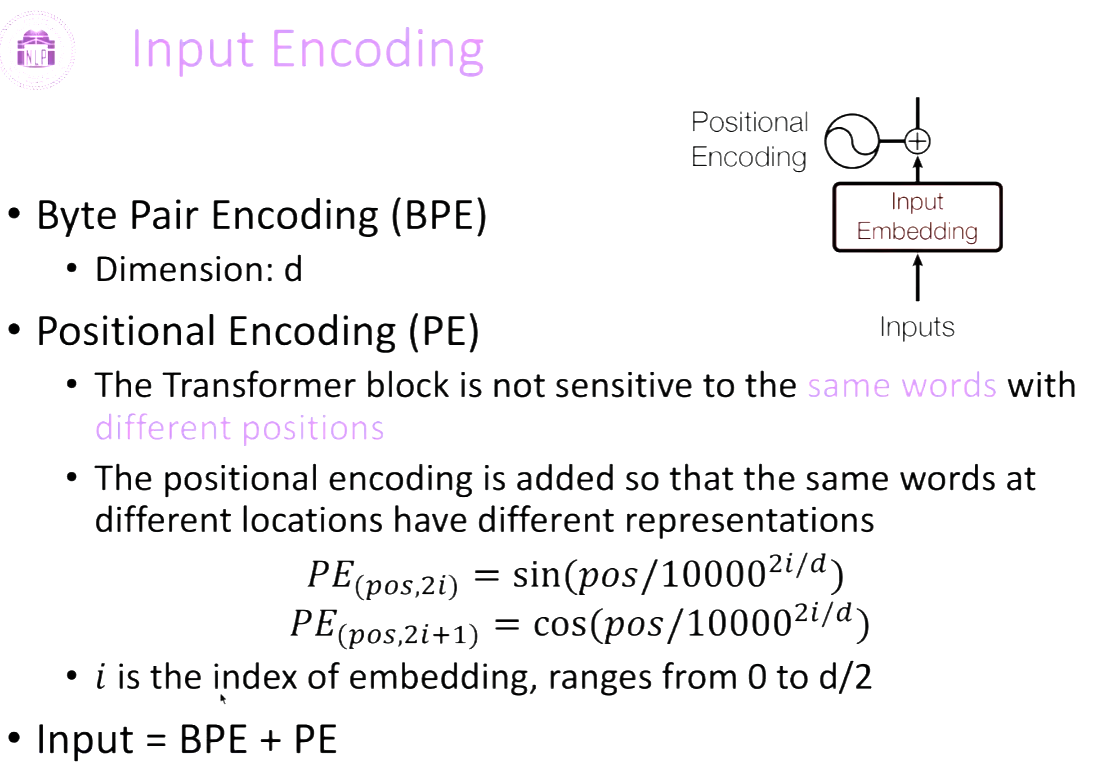
Byte Pair Encoding (BPE)
-用于词切分 word segmentation. 解决OOV out of vocabulary。表示更多的单词。
比如在如下Dictionary中,出现OOV word “lowest”。 它就会被segmented into “low est”。 The relation between “low” and “lowest” can be generalized to “smart” and “smartest”.


Positional Encoding (PE)

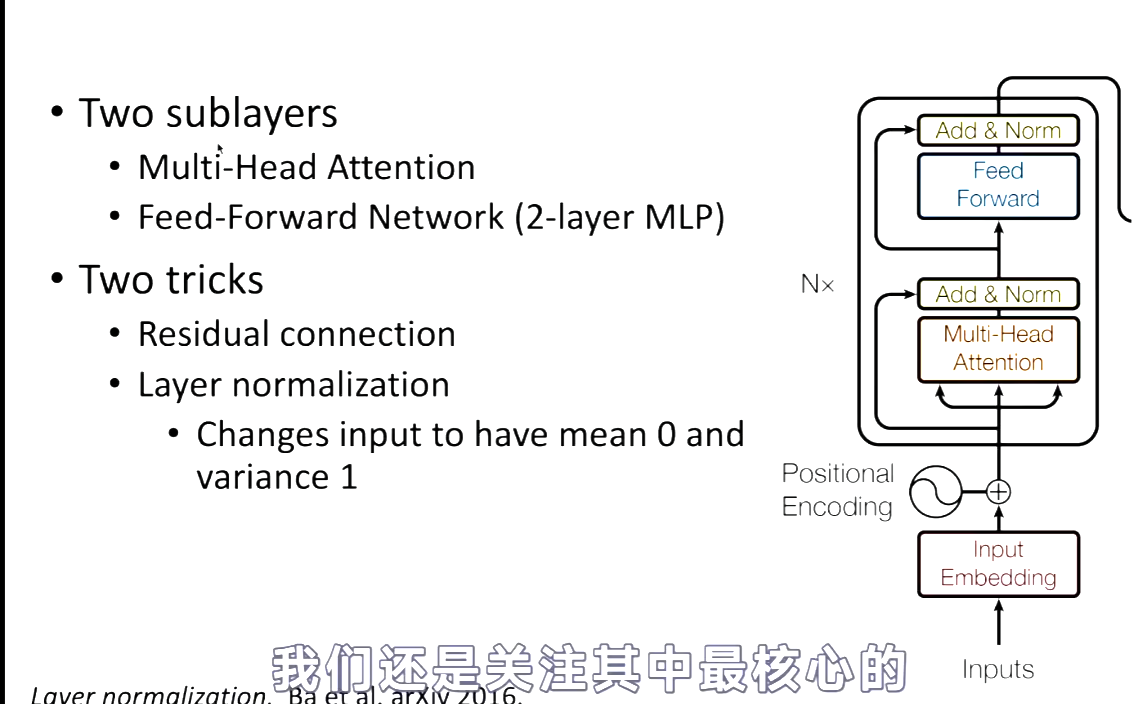
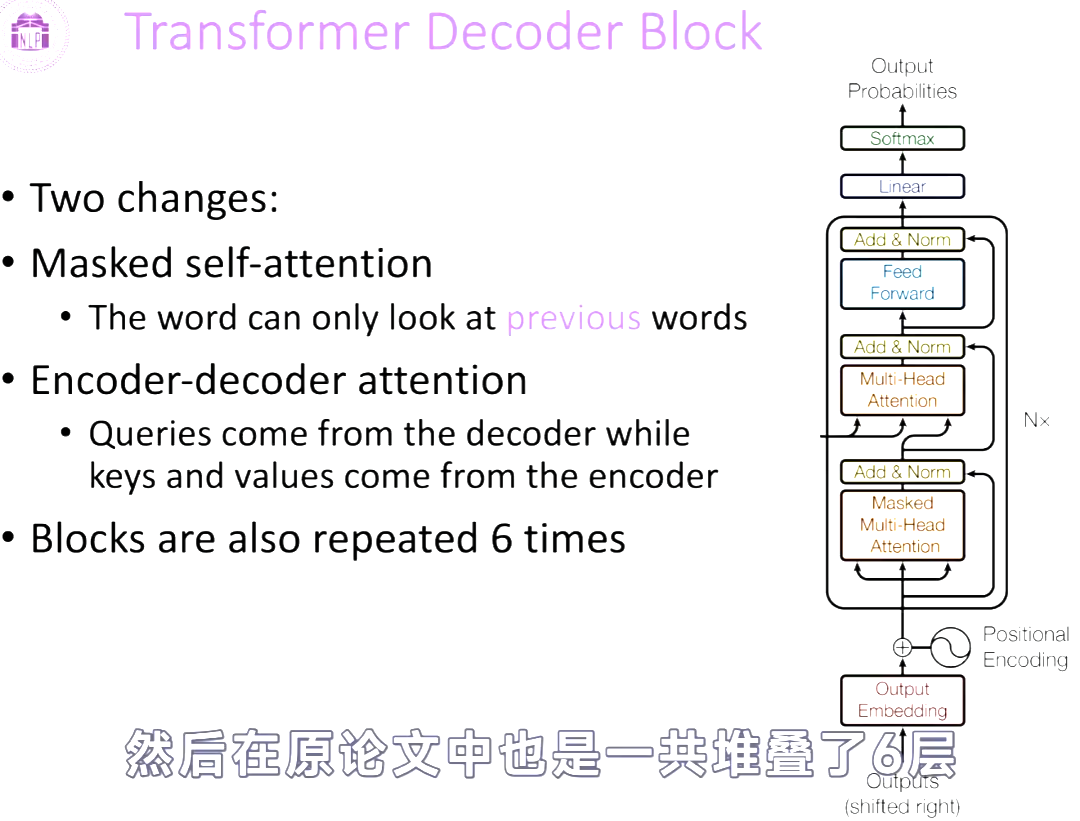
Transformer Block
Encoder Block. 其中Residual connection就是借鉴Kaiming He提出的残差网络ResNet的方法。Norm就是把数据normalization为N(0,1)。
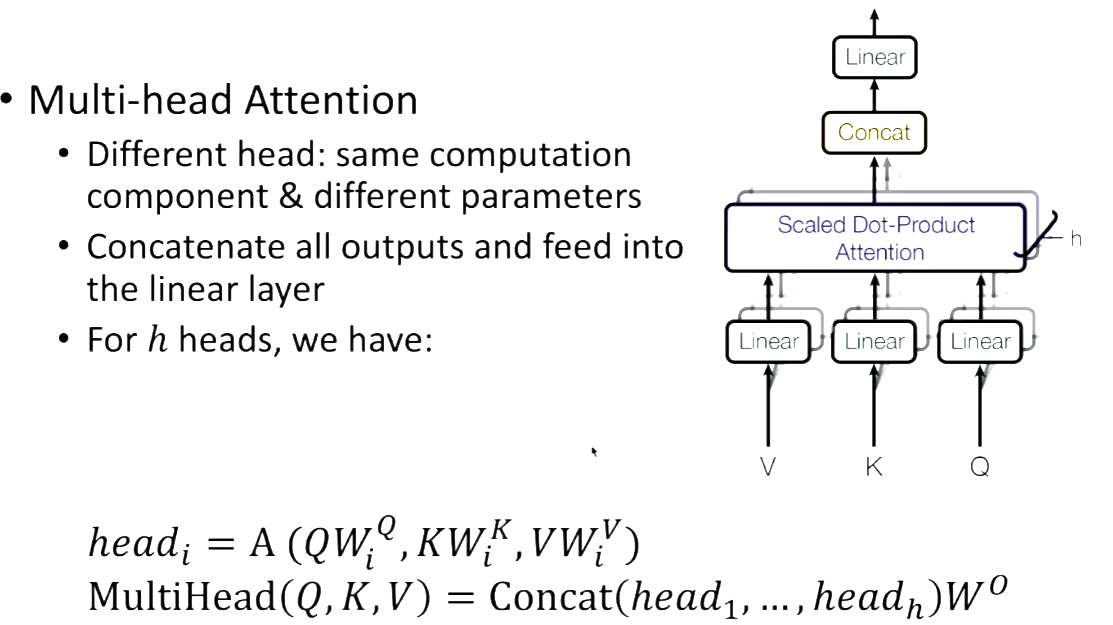
Multi-head Attention

图形理解:
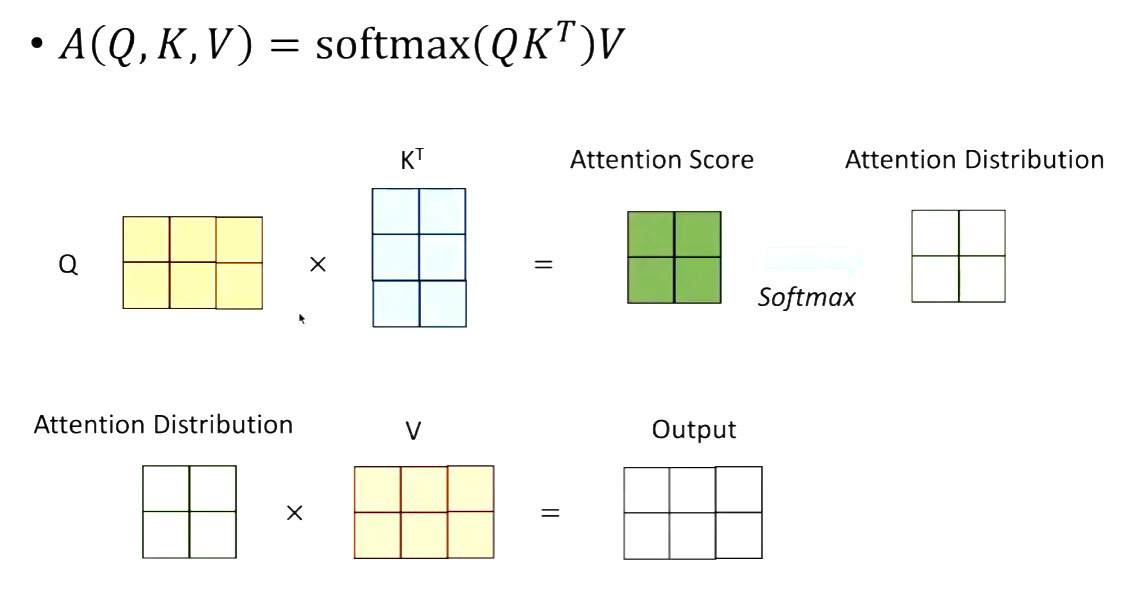
Scaled Dot-Product Attention 核心就是在softmax的时候除以一个sqrt(d_k). 防止梯度消失。

Self-attention 就是要让word vectors 自己选择。
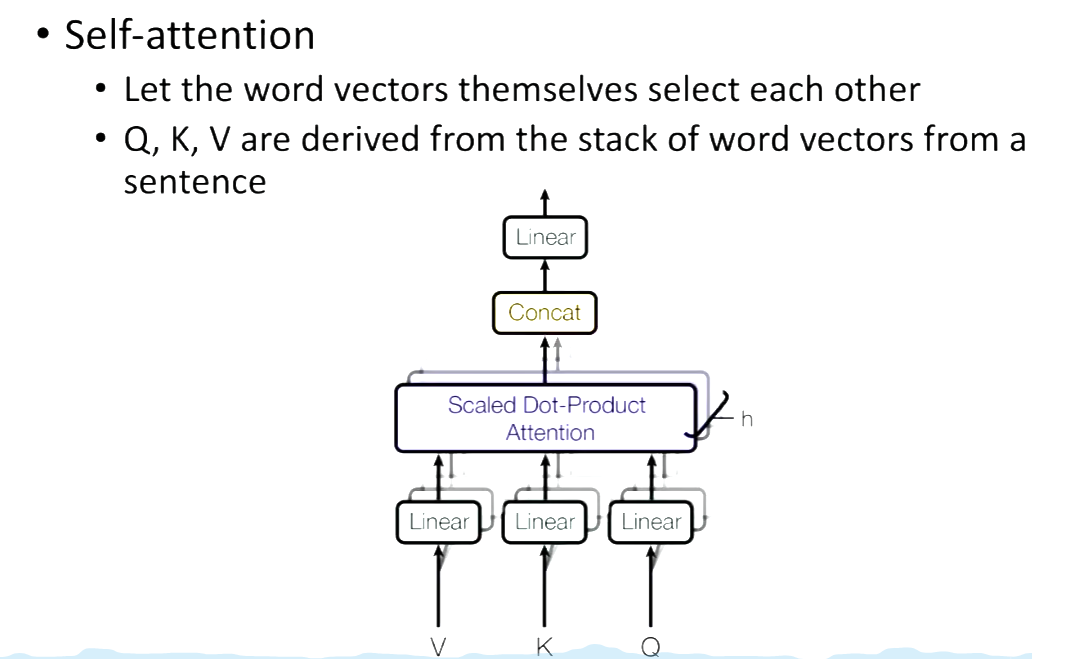
Multi-head Attention
Decoder Block
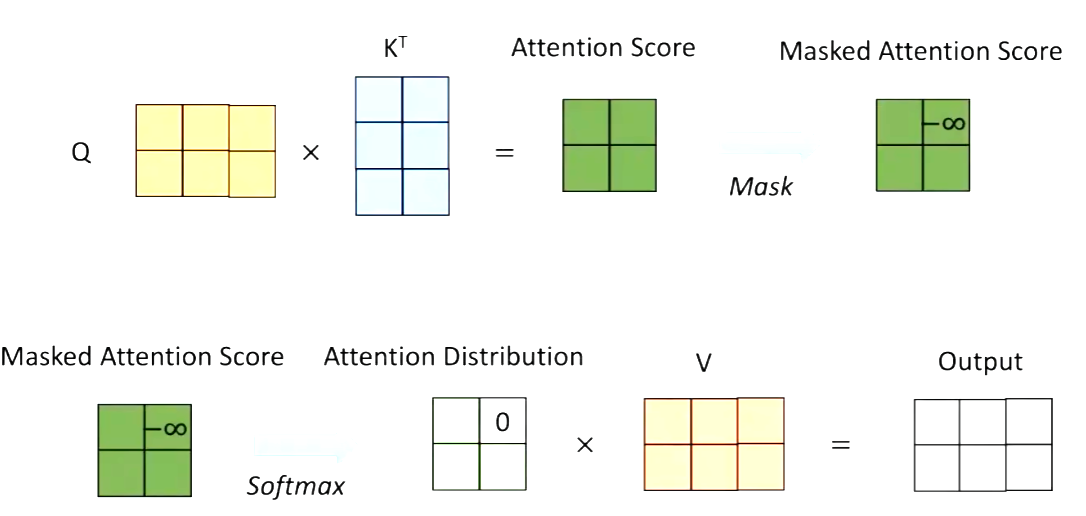
一些小技巧