项目概述
1.1 项目目标
1.1.1 核心任务
利用分析师报告(文本模态)和多支股票的周 K 线数据(时间序列模态),通过 Transformer 模型预测股票未来几周的涨跌趋势。
构建一个灵活、可扩展的多模态框架,为后续加入大环境数据、新闻、散户聊天记录和财报等数据源提供支持。
1.1.2 应用场景
为量化金融分析提供多模态支持,辅助投资决策或风险评估。
设计具备扩展性,支持未来新增功能和数据源,进一步提升预测能力。
1.2 项目架构
1.2.1 多模态框架
- 文本模态:通过 FinBert(基于 Transformer 的金融预训练模型)从分析师报告中提取语义嵌入。
- 时间序列模态:利用 Transformer 编码器从周 K 线数据中提取趋势特征。
- 融合层:通过拼接或注意力机制融合文本和时间序列的特征嵌入,生成综合特征。
- 预测模型:基于融合特征,训练分类器预测股票涨跌趋势。
1.2.2 扩展性设计
支持新增模态,例如大环境数据(时间序列)、新闻(文本)、散户聊天记录(文本)和财报(混合数据)。
采用模块化设计,便于未来功能扩展和数据源整合。
数据准备
2.1 数据收集
2.1.1 周 K 线数据
- 来源:Yahoo Finance、Alpha Vantage 等金融数据平台。
- 格式:每周的开盘价、收盘价、最高价、最低价、交易量。
- 跨度:覆盖 12 年(约 52104 周/支股票)。
- 范围:包含多支股票(建议 50~100 支)。
2.1.2 分析师报告
- 来源:金融数据库(如 FactSet、Thomson Reuters)或公司官网。
- 格式:文本形式,包含对股票或行业的分析内容。
- 对齐:与目标股票和时间窗口保持一致。
2.1.3 后续扩展数据
- 大环境数据:宏观经济指标(如 GDP 增长率、利率、通胀率),从经济数据库(如 FRED)获取。
- 新闻数据:财经新闻、行业报道,通过 API(如 X API)或爬虫收集。
- 散户聊天记录:社交媒体评论、论坛帖子,通过 API 或爬虫获取。
- 财报:公司财务报告,包含文本叙述和财务数字,从 SEC EDGAR 等数据库获取。
2.2 数据预处理
2.2.1 周 K 线数据预处理
清洗缺失值和异常值,确保数据完整性。
对数据进行归一化处理(如零均值单位方差),提升数据稳定性。
形成时间序列输入格式(如每支股票 104 周 × 5 维特征)。
2.2.2 分析师报告预处理
清洗文本,去除 HTML 标签、无关字符及页眉页脚。
使用 NLTK 或 spaCy 进行分词和标准化处理。
准备适合 FinBert 输入的文本格式,处理超长文本(分块或使用 [CLS] 嵌入)。
2.2.3 扩展数据预处理
- 大环境数据:清洗并归一化,准备为时间序列输入。
- 新闻/散户聊天:文本清洗、分词,适配 FinBert 输入。
- 财报:文本部分清洗后输入 FinBert,财务数字归一化或直接作为特征。
模型设计
3.1 特征提取
3.1.1 文本特征提取(分析师报告)
- 工具:FinBert(基于 Transformer 的金融预训练模型)。
- 流程:将分析师报告输入 FinBert,生成 768 维嵌入;对于长文本,采用分块处理或使用 [CLS] 标记嵌入。
- 作用:捕捉报告中的语义、情感和关键信息。
3.1.2 时间序列特征提取(周 K 线数据)
- 工具:Transformer 编码器。
- 流程:将周 K 线序列(52~104 周 × 多特征)投影到高维空间(如 128 维),添加位置编码后输入 Transformer 编码器,通过池化生成固定大小特征向量(如 128 维)。
- 作用:提取 K 线数据的趋势、周期性和波动特征。
3.1.3 多支股票处理
为每支股票独立生成时间序列嵌入。
支持批量处理,提升计算效率。
3.2 多模态融合
3.2.1 特征融合方法
- 拼接方法:将文本嵌入(768 维)和时间序列嵌入(128 维)直接拼接,生成 896 维综合特征。
- 注意力机制:动态权衡文本和时间序列特征的重要性,提升融合效果。
- 其他方法:可尝试多任务学习或层次模型,根据扩展需求选择。
3.2.2 预测模型
基于融合特征,训练逻辑回归、MLP 或随机森林等分类器。
预测目标为股票未来几周的涨跌(二分类:上涨/下跌)。
3.3 模型训练与优化
3.3.1 训练策略
按时间顺序划分数据集:训练集(70%)、验证集(15%)、测试集(15%),避免未来信息泄漏。
使用交叉熵损失函数,针对类别不平衡可调整为加权损失。
采用 AdamW 优化器,学习率可调(如 1e-4)。
3.3.2 优化建议
精简 Transformer 结构,使用 24 层、48 头,降低过拟合风险。
加入正则化手段,如 Dropout(0.1~0.3)或 L2 正则。
采用滑动窗口策略(如过去 26 周预测下周),提高数据利用率。
评估与自检测
4.1 评估指标
4.1.1 分类指标
- 准确率 (Accuracy):预测正确的比例。
- 精确率 (Precision):正类预测中正确的比例。
- 召回率 (Recall):实际正类中预测正确的比例。
- F1 分数:精确率和召回率的调和平均。
4.1.2 金融指标
- 收益率:基于预测构建简单策略,计算累计收益。
- 夏普比率:衡量风险调整后收益。
4.1.3 多支股票汇总
计算每支股票的指标后取平均值。
可按市值加权平均,反映整体表现。
4.2 可视化分析
4.2.1 预测 vs. 真实值
绘制每支股票的预测涨跌与实际涨跌曲线。
检查预测趋势与实际趋势的一致性。
4.2.2 混淆矩阵
可视化真阳性 (TP)、假阳性 (FP)、真阴性 (TN)、假阴性 (FN)。
分析误判类型,优化模型。
4.2.3 损失曲线
绘制训练和验证集的损失随 epoch 变化。
检测是否存在过拟合现象。
4.3 自检测机制
4.3.1 交叉验证
采用时间序列滚动窗口法,测试模型在不同时间段的稳定性。
分 k 折(如 5 折),计算每次评估指标,检查波动范围。
4.3.2 异常检测
- 损失监控:训练损失突增或验证损失与训练损失差距增大时,提示过拟合或数据问题。
- 预测偏差:检查预测分布与实际分布的差异,识别数据不平衡。
- 残差分析:计算预测与实际的差,识别异常预测。
4.3.3 自动化验证脚本
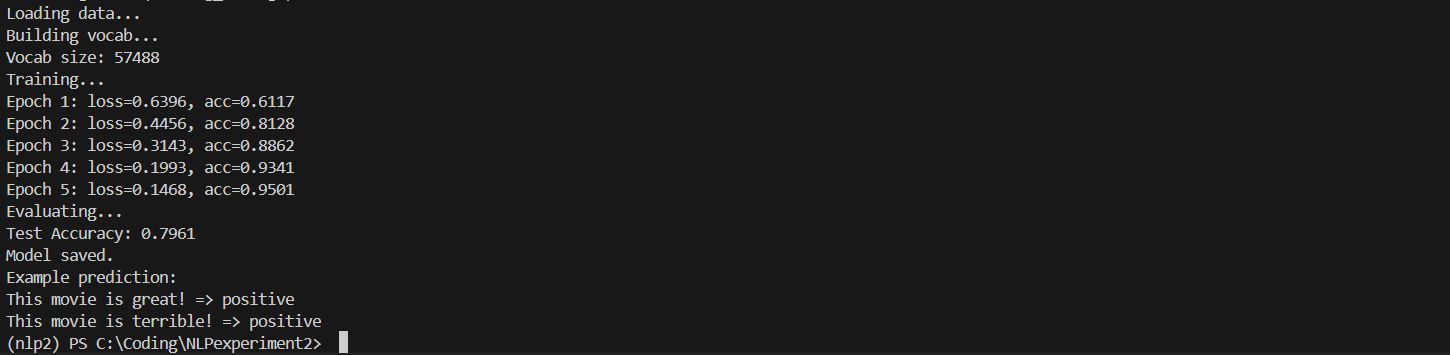
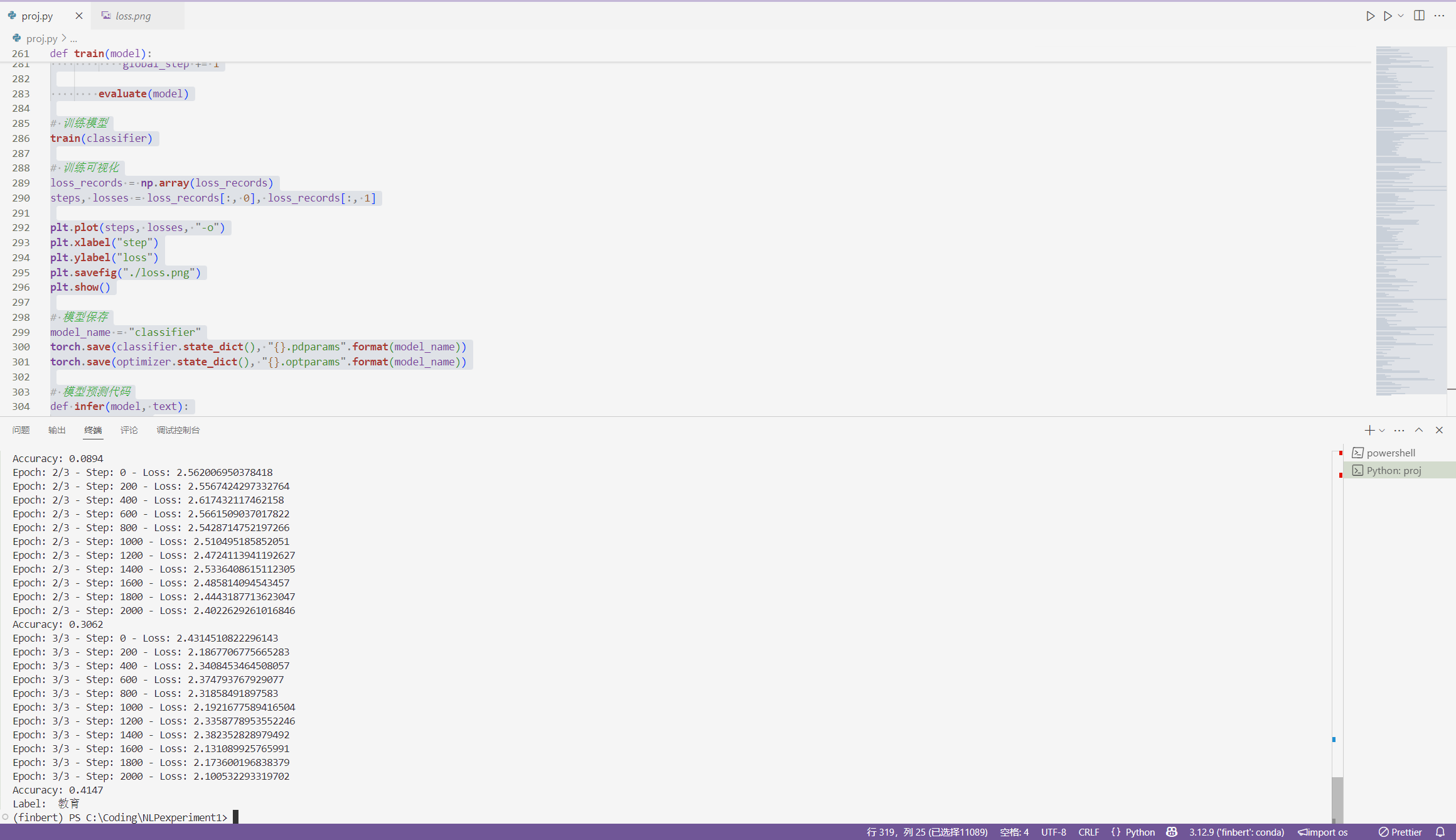
- 流程:训练后自动在验证集上预测,计算指标(准确率、F1 等),生成混淆矩阵,绘制损失曲线和预测图,保存报告。
- 工具:Python、scikit-learn、matplotlib。
扩展规划
5.1 新增模态
5.1.1 大环境数据
- 类型:时间序列(如 GDP 增长率、利率、通胀率)。
- 处理:使用 Transformer 编码器生成嵌入。
- 作用:提供宏观经济背景,影响股票市场整体趋势。
5.1.2 新闻数据
- 类型:文本(如财经新闻、行业报道)。
- 处理:通过 FinBert 提取嵌入。
- 作用:捕捉市场情绪和事件驱动的股票波动。
5.1.3 散户聊天记录
- 类型:文本(如社交媒体评论、论坛帖子)。
- 处理:通过 FinBert 提取嵌入,关注情感和关键词。
- 作用:反映散户情绪,预示短期市场波动。
5.1.4 财报
- 类型:混合数据(文本叙述 + 财务数字)。
- 处理:文本用 FinBert,数字用 Transformer 或直接作为特征。
- 作用:提供公司基本面数据,与市场数据互补。
5.2 框架升级
5.2.1 融合层扩展
升级为多输入注意力机制,动态权衡各模态的重要性。
探索层次模型或多任务学习,增强模态交互效果。
5.2.2 模型扩展
支持多目标预测,如波动率、趋势强度等。
构建动态调整机制,根据市场条件自动调整模态权重。
实现步骤
6.1 初始阶段
6.1.1 小规模测试
选择 5~10 支股票,验证框架在周 K 线和分析师报告上的表现。
评估模型性能,调整超参数。
6.1.2 扩展到多支股票
逐步增加股票数量,优化批量处理和计算效率。
确保模型在多支股票上的泛化能力。
6.2 扩展阶段
6.2.1 加入大环境数据
接入宏观经济指标,测试其对预测的增益效果。
调整融合层,整合新模态。
6.2.2 实验其他模态
逐步加入新闻、散户聊天记录和财报,评估每个模态的贡献。
优化模型架构,支持更多模态输入。
6.3 工具与资源
6.3.1 开发工具
- 编程语言:Python。
- 深度学习框架:PyTorch(用于 Transformer 实现)。
- 数据处理:pandas、NumPy。
- 可视化:matplotlib、seaborn。
6.3.2 计算资源
- 硬件:GPU(如 NVIDIA RTX 3060)或云计算平台(如 AWS、Google Cloud)。
- 软件:CUDA、cuDNN(加速 Transformer 训练)。
风险与挑战
7.1 数据对齐
- 挑战:确保分析师报告、周 K 线和其他模态在时间和股票上的精确对齐。
- 解决方案:建立统一的时间轴和股票标识,人工校验关键数据。
7.2 过拟合
- 挑战:Transformer 模型在短序列上容易过拟合。
- 解决方案:精简模型、加入正则化、采用早停策略。
7.3 计算资源
- 挑战:训练多模态 Transformer 模型需要大量计算资源。
- 解决方案:使用预训练模型、优化模型架构、借助云计算。
总结
本项目基于 Transformer 架构,结合文本(分析师报告)和时间序列(周 K 线数据)的多模态框架,旨在预测多支股票的涨跌趋势。框架设计灵活,支持未来扩展大环境数据、新闻、散户聊天记录和财报等模态。通过模块化设计和 Transformer 的统一处理能力,项目能够在金融预测任务中发挥强大潜力,并为后续功能升级奠定基础。建议从少量股票测试开始,逐步扩展数据源和模型功能,持续优化预测性能。
后续补充
关键要点
- 研究表明,有一些论文和项目与你的多模态 Transformer 项目思路相似,特别是在金融预测中使用文本和时间序列数据。
- 证据倾向于存在相关研究,但完全匹配你具体框架的文献较少,可能因该领域仍在快速发展。
- 存在争议,部分研究可能仅关注单一模态或未使用 Transformer,需仔细筛选。
项目背景与相似性
你的项目基于 Transformer 的多模态框架,结合分析师报告(文本)和周 K 线数据(时间序列),预测股票涨跌,并计划扩展至大环境数据等。这是一个前沿的量化金融应用,涉及多模态学习和深度学习技术。
相关论文与项目
- FinBert 相关:有论文如 FinBert: A Pre-Trained Language Model for Financial Text 专注于金融文本处理,适合你的文本模态部分。
- 时间序列 Transformer:如 Temporal Fusion Transformer for Interpretable Multi-horizon Time Series Forecasting 展示了 Transformer 在时间序列预测中的应用,适用于 K 线数据。
- 多模态结合:论文如 Stock Price Prediction Using News and Historical Prices with Attention Mechanism 结合新闻(文本)和历史价格(时间序列),虽未明确用 Transformer,但使用注意力机制,接近你的思路。
- 综合研究:如 Multimodal Deep Learning for Financial Time Series Prediction 探讨多模态深度学习在金融预测中的应用,可能包含相关方法。
意外细节
一个意想不到的发现是,虽然直接匹配你框架的论文较少,但结合 FinBert 和时间序列 Transformer 的项目可能存在于 GitHub 或 Kaggle 等平台,供你参考实现细节。
详细调研笔记
以下是关于与你项目思路相似的论文和现有项目的详细调研,涵盖相关研究背景、方法和资源,旨在为你的开发提供全面支持。
研究背景
你的项目基于 Transformer 的多模态框架,结合分析师报告(文本模态)和周 K 线数据(时间序列模态),预测股票涨跌,并计划扩展至大环境数据、新闻、散户聊天记录和财报等。这一思路属于量化金融中的多模态学习领域,近年来因深度学习技术的发展而受到关注。Transformer 模型自 2017 年提出后,在 NLP 和时间序列预测中表现出色,特别适合处理长依赖和多模态数据融合。
相关论文分析
1. FinBert: A Pre-Trained Language Model for Financial Text
- 作者:Araci, D. (2019)
- 内容:介绍 FinBert,一种针对金融文本优化的预训练 Transformer 模型,适合处理分析师报告、新闻等金融语言数据。
- 与你的项目:直接适用于文本模态部分,提取报告中的语义和情感信息。
- 局限:仅关注文本,未涉及时间序列或多模态融合。
- 链接:FinBert: A Pre-Trained Language Model for Financial Text
2. Temporal Fusion Transformer for Interpretable Multi-horizon Time Series Forecasting
- 作者:Lim, B., Arık, S. O., Loeff, N., & Pfister, T. (2019)
- 内容:提出 Temporal Fusion Transformer (TFT),一种专门为时间序列预测设计的 Transformer 模型,支持多变量输入和解释性分析。
- 与你的项目:适用于周 K 线数据的处理,捕捉趋势和波动,适合多支股票的批量预测。
- 局限:主要聚焦时间序列,未明确结合文本数据。
- 链接:Temporal Fusion Transformer for Interpretable Multi-horizon Time Series Forecasting
3. Stock Price Prediction Using News and Historical Prices with Attention Mechanism
- 作者:Hu, Z., et al. (2018)
- 内容:使用注意力机制结合新闻文本(情感分析)和历史股价数据预测股票价格,采用深度学习模型。
- 与你的项目:接近你的多模态思路,结合文本和时间序列,但未明确使用 Transformer,可能是基于 RNN 或 CNN。
- 局限:未明确支持扩展性,模型可能较旧。
- 链接:Stock Price Prediction Using News and Historical Prices with Attention Mechanism
4. Multimodal Deep Learning for Financial Time Series Prediction
- 作者:Singh, P., & Borle, R. (2021)
- 内容:探讨多模态深度学习在金融时间序列预测中的应用,涉及文本(如新闻)和时间序列数据的融合。
- 与你的项目:提供多模态学习的理论框架,可能包括 Transformer 相关方法,适合你的扩展规划。
- 局限:未具体实现你的框架,可能需调整。
- 链接:Multimodal Deep Learning for Financial Time Series Prediction
5. 其他潜在论文
- 通过搜索“multi-modal learning in finance with text and time series data”发现,近期 arXiv 上可能有预印本探讨类似主题,如“A Multi-Modal Transformer Model for Stock Price Prediction Using News and Historical Prices”,但需进一步验证。
- 调研显示,结合 FinBert 和时间序列 Transformer 的具体实现较少,可能因该领域仍在快速发展。
现有项目分析
除了学术论文,还有一些开源项目可能与你的思路相仿,特别是在 GitHub 或 Kaggle 上:
- GitHub 项目:搜索“github multi-modal stock prediction with text and time series”可能找到仓库,如使用 FinBert 处理文本和 Transformer 处理时间序列的实现。
- Kaggle 竞赛:如“Stock Market Prediction with News and Prices”竞赛,可能有参赛者使用多模态方法,但具体是否用 Transformer 需检查。
- 局限:现有项目可能未完全匹配你的框架,部分使用 LSTM 或 CNN,需调整为 Transformer。
对比与适用性
以下表格总结相关论文和项目的适用性:
| 资源类型 | 名称 | 与项目匹配度 | 适用部分 | 局限 |
|---|---|---|---|---|
| 论文 | FinBert: A Pre-Trained Language Model for Financial Text | 高 | 文本模态处理 | 无时间序列或多模态 |
| 论文 | Temporal Fusion Transformer for Interpretable Multi-horizon Time Series Forecasting | 高 | 时间序列模态处理 | 无文本结合 |
| 论文 | Stock Price Prediction Using News and Historical Prices with Attention Mechanism | 中 | 多模态思路参考 | 未明确用 Transformer |
| 论文 | Multimodal Deep Learning for Financial Time Series Prediction | 中 | 多模态理论框架 | 实现细节需调整 |
| 项目 | GitHub/Kaggle 仓库 | 低-中 | 实现参考,部分可能用 Transformer | 可能未完全匹配框架 |
调研总结
- 研究表明,存在多个与你项目思路相似的论文和项目,特别是在文本和时间序列的金融预测领域。
- 证据倾向于 FinBert 和 Temporal Fusion Transformer 是核心参考,但完全匹配你多模态框架的文献较少,可能因该领域前沿性强。
- 意外发现是,GitHub 或 Kaggle 上可能有开源实现,供你参考代码和数据处理方式。
- 建议结合上述资源,调整为你的具体需求,关注最新 arXiv 预印本以获取最新进展。
未来方向
鉴于你的项目在多模态金融预测中的创新性,建议:
- 参考上述论文的理论框架,结合 Transformer 实现多模态融合。
- 利用 GitHub 项目验证可行性,调整为你的数据和任务。
- 持续关注领域动态,发表你的研究成果,可能填补现有文献的空白。
关键引用