NLP文本分类实验报告
1. 引言
1.1 实验背景
本实验实现了一个基于PyTorch的自然语言处理文本分类系统,使用双向LSTM结合注意力机制对中文文本进行多分类任务。实验采用了现代深度学习架构,旨在准确分类新闻文本的类别。
1.2 实验目标
- 实现一个端到端的文本分类系统
- 利用深度学习技术提高分类准确率
- 探索注意力机制在文本分类中的应用
- 实现GPU加速训练
2. 实验环境
2.1 技术栈
- Python 3.x
- PyTorch – 深度学习框架
- jieba – 中文分词库
- NumPy – 数值计算库
- Matplotlib – 可视化库
2.2 硬件环境
- GPU加速支持(CUDA)
- CPU备选方案
3. 数据集处理
3.1 数据集结构
实验使用的数据集包含以下文件:
train.txt– 训练数据test.txt– 测试数据dict.txt– 词典文件label_dict.txt– 标签词典
3.2 数据加载
def load_dataset(path):
# 生成加载数据的地址
train_path = os.path.join(path, "train.txt")
test_path = os.path.join(path, "test.txt")
dict_path = os.path.join(path, "dict.txt")
label_path = os.path.join(path, "label_dict.txt")
# 加载词典和标签
# ...省略详细代码...
return train_set, test_set, word_dict, label_dict数据加载过程包括:
- 路径构建
- 词典加载(将文本词汇映射为数字ID)
- 标签词典加载(将标签映射为数字类别)
- 训练集和测试集加载(每条数据包含文本和对应标签)
3.3 数据预处理
3.3.1 文本序列化
def convert_corpus_to_id(data_set, word_dict, label_dict):
tmp_data_set = []
for text, label in data_set:
text = [word_dict.get(word, word_dict["[oov]"]) for word in jieba.cut(text)]
tmp_data_set.append((text, label_dict[label]))
return tmp_data_set预处理步骤:
- 使用jieba进行中文分词
- 将分词结果转换为词典ID
- 处理未登录词(OOV,Out-Of-Vocabulary)
- 将文本标签转换为数字标签
3.4 批处理构建
def build_batch(data_set, batch_size, max_seq_len, shuffle=True, drop_last=True, pad_id=1):
# ...省略代码细节...批处理过程包括:
- 序列截断(限制最大长度)
- 序列填充(使所有序列长度一致)
- 随机打乱数据(可选)
- 批次构建(将数据分成多个batch)
- 处理不足一个batch的数据(可选丢弃)
4. 模型架构
4.1 注意力机制实现
class AttentionLayer(nn.Module):
def __init__(self, hidden_size):
super(AttentionLayer, self).__init__()
self.w = nn.Parameter(torch.empty(hidden_size, hidden_size))
self.v = nn.Parameter(torch.empty([1, hidden_size], dtype=torch.float32))
def forward(self, inputs):
# ...省略前向传播细节...注意力层的工作原理:
- 接收LSTM所有时间步的隐藏状态作为输入
- 使用可学习参数计算注意力权重
- 使用softmax归一化权重
- 使用权重对隐藏状态进行加权求和
- 输出注意力向量,表示文本的语义表示
4.2 分类器模型
class Classifier(nn.Module):
def __init__(self, hidden_size, embedding_size, vocab_size, n_classes=14,
n_layers=1, direction="bidirectional",
dropout_rate=0., init_scale=0.05):
# ...省略初始化部分...
def forward(self, inputs):
# ...省略前向传播部分...分类器模型的组成部分:
- 词嵌入层(Embedding)- 将词ID转换为密集向量表示
- 双向LSTM层 – 捕捉文本的上下文信息
- Dropout层 – 防止过拟合
- 注意力层 – 对LSTM的输出进行加权
- 全连接层 – 将注意力输出映射到类别概率
4.3 模型参数说明
n_epochs = 3 # 训练轮数
vocab_size = len(word_dict.keys()) # 词典大小
batch_size = 128 # 每个batch中样本数目
hidden_size = 128 # LSTM的隐藏层大小
embedding_size = 128 # 词嵌入的维度
n_classes = 14 # 分类类别数
max_seq_len = 32 # 序列的最大长度
n_layers = 1 # LSTM的层数
dropout_rate = 0.2 # dropout比率
learning_rate = 0.0001 # 学习率
direction = "bidirectional" # LSTM是否为双向5. 训练过程
5.1 设备配置
# 检测是否可以使用GPU,如果可以优先使用GPU
use_gpu = torch.cuda.is_available()
if use_gpu:
device = torch.device("cuda:0")
print("使用GPU训练: ", torch.cuda.get_device_name(0))
else:
device = torch.device("cpu")
print("使用CPU训练")
# 将模型移到指定设备
classifier = classifier.to(device)5.2 优化器设置
optimizer = optim.Adam(classifier.parameters(), lr=learning_rate, betas=(0.9, 0.99))- 使用Adam优化器
- 学习率设置为0.0001
- beta参数设置为(0.9, 0.99),控制动量衰减率
5.3 损失函数
使用交叉熵损失函数,适用于多分类问题:
loss = F.cross_entropy(input=logits, target=batch_labels_flat, reduction='mean')5.4 训练循环
def train(model):
global_step = 0
for epoch in range(n_epochs):
model.train()
for step, (batch_texts, batch_labels) in enumerate(build_batch(train_set, batch_size, max_seq_len, shuffle=True, pad_id=word_dict["[pad]"])):
# 将数据移到GPU
batch_texts = torch.tensor(batch_texts).to(device)
batch_labels = torch.tensor(batch_labels).to(device)
# 前向传播
logits = model(batch_texts)
batch_labels_flat = batch_labels.view(-1)
loss = F.cross_entropy(input=logits, target=batch_labels_flat, reduction='mean')
# 反向传播和参数更新
loss.backward()
optimizer.step()
optimizer.zero_grad()
# 记录损失
if step % 200 == 0:
loss_records.append((global_step, loss.item()))
print(f"Epoch: {epoch+1}/{n_epochs} - Step: {step} - Loss: {loss.item()}")
global_step += 1
# 每个epoch结束后评估
evaluate(model)训练流程:
- 循环指定的训练轮数(epochs)
- 将模型设置为训练模式
- 构建批次数据并移动到GPU
- 执行前向传播计算损失
- 执行反向传播更新参数
- 定期记录损失值
- 每轮结束后在测试集上评估模型
5.5 评估方法
def evaluate(model):
model.eval()
metric = Metric(id2label)
for batch_texts, batch_labels in build_batch(test_set, batch_size, max_seq_len, shuffle=False, pad_id=word_dict["[pad]"]):
# 将数据移到GPU
batch_texts = torch.tensor(batch_texts).to(device)
batch_labels = torch.tensor(batch_labels).to(device)
# 前向传播
logits = model(batch_texts)
probs = F.softmax(logits, dim=1)
# 预测并更新评估指标
preds = probs.argmax(dim=1).cpu().numpy()
batch_labels = batch_labels.squeeze().cpu().numpy()
metric.update(real_labels=batch_labels, pred_labels=preds)
# 计算并输出结果
result = metric.get_result()
metric.format_print(result)评估过程:
- 将模型设置为评估模式
- 禁用梯度计算以节省内存
- 在测试集上进行批量预测
- 计算准确率等评估指标
- 输出评估结果
6. 结果分析
6.1 评估指标
使用准确率(Accuracy)作为主要评估指标:
class Metric:
def __init__(self, id2label):
self.id2label = id2label
self.reset()
def reset(self):
self.total_samples = 0
self.total_corrects = 0
def update(self, real_labels, pred_labels):
self.total_samples += real_labels.shape[0]
self.total_corrects += np.sum(real_labels == pred_labels)
def get_result(self):
accuracy = self.total_corrects / self.total_samples
return {"accuracy": accuracy}
def format_print(self, result):
print(f"Accuracy: {result['accuracy']:.4f}")6.2 训练可视化
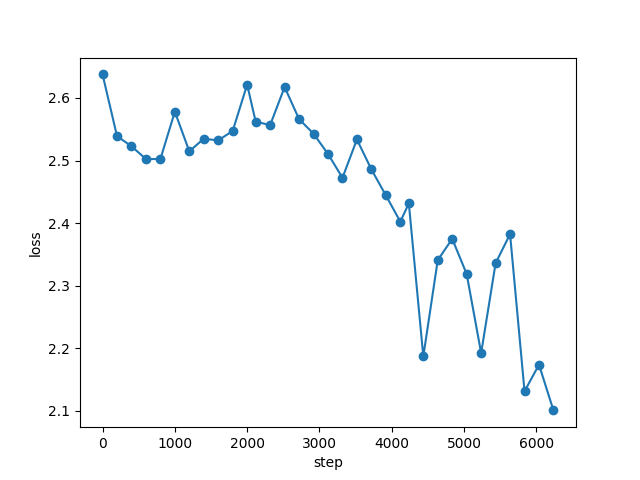
# 训练可视化
loss_records = np.array(loss_records)
steps, losses = loss_records[:, 0], loss_records[:, 1]
plt.plot(steps, losses, "-o")
plt.xlabel("step")
plt.ylabel("loss")
plt.savefig("./loss.png")
plt.show()- 绘制训练过程中的损失变化曲线
- 横轴为训练步骤,纵轴为损失值
- 保存图像以便后续分析
7. 模型应用
7.1 模型保存
# 模型保存
model_name = "classifier"
torch.save(classifier.state_dict(), "{}.pdparams".format(model_name))
torch.save(optimizer.state_dict(), "{}.optparams".format(model_name))- 保存模型参数以便后续使用
- 同时保存优化器状态
7.2 预测函数
def infer(model, text):
model.eval()
tokens = [word_dict.get(word, word_dict["[oov]"]) for word in jieba.cut(text)]
tokens = torch.LongTensor(tokens).unsqueeze(0)
with torch.no_grad():
logits = model(tokens)
probs = F.softmax(logits, dim=1)
max_label_id = torch.argmax(logits, dim=1).item()
pred_label = id2label[max_label_id]
print("Label: ", pred_label)预测流程:
- 将模型设置为评估模式
- 对输入文本进行分词和ID转换
- 使用模型进行预测
- 获取概率最高的类别
- 将类别ID转换为可读标签
7.3 预测示例
title = "习近平主席对职业教育工作作出重要指示"
infer(classifier, title)8. 技术亮点
8.1 GPU加速
- 自动检测并使用可用GPU资源
- 将模型和数据转移到相同的设备(CPU或GPU)
- 使用CUDA加速计算,提高训练效率
8.2 注意力机制
- 实现了基于注意力的文本表示
- 能够自动学习重要词汇的权重
- 提高了模型对关键信息的捕捉能力
8.3 鲁棒性设计
- 处理未登录词(OOV)
- 序列长度自适应处理(截断与填充)
- Dropout机制防止过拟合
9. 总结与展望
9.1 实验总结
本实验成功实现了基于BiLSTM+Attention的中文文本分类模型。模型能够自动学习文本特征,并通过注意力机制识别关键信息,实现了对多类别文本的有效分类。通过对CUDA的支持,模型能够充分利用GPU资源加速训练过程。
9.2 改进方向
- 预训练模型:引入BERT、RoBERTa等预训练模型提升性能
- 数据增强:使用回译、同义词替换等方法扩充训练数据
- 模型优化:尝试不同的网络结构如Transformer、GRU等
- 超参数调优:使用网格搜索、贝叶斯优化等方法寻找最佳参数
- 交叉验证:引入k折交叉验证提高模型泛化能力
通过这些改进,有望进一步提高模型的分类准确率和泛化能力,使其更适合实际应用场景。
找到具有 1 个许可证类型的类似代码
代码以及结果展示
我使用conda创建了python 3.12.7的环境
安装必要环境后
# 导入相关包
import os
import jieba
import random
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.nn.init as I
import torch.optim as optim
import matplotlib.pyplot as plt
def load_dataset(path):
# 生成加载数据的地址
# 生成训练集、测试集、词典和标签词典的文件路径
train_path = os.path.join(path, "train.txt")
test_path = os.path.join(path, "test.txt")
dict_path = os.path.join(path, "dict.txt")
label_path = os.path.join(path, "label_dict.txt")
# 加载词典
# 读取词典文件并生成词典字典,字典中键为单词,值为对应单词在词典中的索引
with open(dict_path, "r", encoding="utf-8") as f:
words = [word.strip() for word in f.readlines()]
word_dict = dict(zip(words, range(len(words))))
# 加载标签词典
# 读取标签词典文件并生成标签词典字典,字典中键为标签名,值为对应标签的数字编码
with open(label_path, "r", encoding="utf-8") as f:
lines = [line.strip().split() for line in f.readlines()]
lines = [(line[0], int(line[1])) for line in lines]
label_dict = dict(lines)
# 读取数据集
def load_data(data_path):
data_set = []
with open(data_path, "r", encoding="utf-8") as f:
# 遍历文件中的每一行,将每一行的标签和文本内容组成一个二元组,然后将这些二元组添加到"data_set"列表中
for line in f.readlines():
label, text = line.strip().split("\t", maxsplit=1)
data_set.append((text, label))
return data_set
train_set = load_data(train_path)
test_set = load_data(test_path)
return train_set, test_set, word_dict, label_dict
# 将文本序列进行分词,然后词转换为字典ID
def convert_corpus_to_id(data_set, word_dict, label_dict):
tmp_data_set = []
for text, label in data_set:
text = [word_dict.get(word, word_dict["[oov]"]) for word in jieba.cut(text)]
tmp_data_set.append((text, label_dict[label]))
return tmp_data_set
# 构造训练数据,每次传入模型一个batch,一个batch 里面有batch_size 条样本
def build_batch(data_set, batch_size, max_seq_len, shuffle=True, drop_last=True, pad_id=1):
batch_text = []
batch_label = []
if shuffle:
random.shuffle(data_set)
for text, label in data_set:
# 截断数据
text = text[:max_seq_len]
# 填充数据到固定长度
if len(text) < max_seq_len:
text.extend([pad_id]*(max_seq_len-len(text)))
assert len(text) == max_seq_len
batch_text.append(text)
batch_label.append([label])
if len(batch_text) == batch_size:
yield np.array(batch_text).astype("int64"), np.array(batch_label).astype("int64")
batch_text.clear()
batch_label.clear()
# 处理是否删掉最后一个不足batch_size 的batch 数据
if (not drop_last) and len(batch_label) > 0:
yield np.array(batch_text).astype("int64"), np.array(batch_label).astype("int64")
# 定义注意力层
class AttentionLayer(nn.Module):
def __init__(self, hidden_size):
super(AttentionLayer, self).__init__()
self.w = nn.Parameter(torch.empty(hidden_size, hidden_size))
self.v = nn.Parameter(torch.empty([1, hidden_size], dtype=torch.float32))
def forward(self, inputs):
# inputs: [batch_size, seq_len, hidden_size]
last_layers_hiddens = inputs
# transposed inputs: [batch_size, hidden_size, seq_len]
inputs = torch.transpose(inputs, dim0=1, dim1=2)
# inputs: [batch_size, hidden_size, seq_len]
inputs = torch.tanh(torch.matmul(self.w, inputs))
# attn_weights: [batch_size, seq_len]
attn_weights = torch.matmul(self.v, inputs)
# softmax 数值归一化
attn_weights = F.softmax(attn_weights, dim=-1)
# 通过attention 后的向量值, attn_vectors: [batch_size, hidden_size]
attn_vectors = torch.matmul(attn_weights, last_layers_hiddens)
attn_vectors = torch.squeeze(attn_vectors, axis=1)
return attn_vectors
# 下面实现整体的模型结构,包括双向LSTM 和已经定义的Attention。模型输入是数据处理后的文本,模型输出是文本对应的新闻类别,实现代码如下。
class Classifier(nn.Module):
def __init__(self, hidden_size, embedding_size, vocab_size, n_classes=14,
n_layers=1, direction="bidirectional",
dropout_rate=0., init_scale=0.05):
super(Classifier, self).__init__()
# 表示LSTM 单元的隐藏神经元数量,它也将用来表示hidden 和cell 向量状态的维度
self.hidden_size = hidden_size
# 表示词向量的维度
self.embedding_size = embedding_size
# 表示神经元的dropout 概率
self.dropout_rate = dropout_rate
# 表示词典的的单词数量
self.vocab_size = vocab_size
# 表示文本分类的类别数量
self.n_classes = n_classes
# 表示LSTM 的层数
self.n_layers = n_layers
# 用来设置参数初始化范围
self.init_scale = init_scale
# # 定义embedding 层 似乎存在版本过时
# self.embedding = nn.Embedding(num_embeddings=self.vocab_size,
# embedding_dim=self.embedding_size,
# weight=nn.Parameter(torch.empty(self.vocab_size,
# self.embedding_size).uniform_(-self.init_scale, self.init_scale)))
self.embedding = nn.Embedding(num_embeddings=self.vocab_size,
embedding_dim=self.embedding_size)
# 初始化embedding权重
self.embedding.weight.data.uniform_(-self.init_scale, self.init_scale)
# 定义LSTM,它将用来编码网络
self.lstm = nn.LSTM(input_size=self.embedding_size,
hidden_size=self.hidden_size,
num_layers=self.n_layers,
bidirectional=True,
dropout=self.dropout_rate)
# 对词向量进行dropout
self.dropout_emb = nn.Dropout(p=self.dropout_rate)
# 定义Attention 层
self.attention = AttentionLayer(hidden_size=hidden_size*2 if direction == "bidirectional" else hidden_size)
# 定义分类层,用于将语义向量映射到相应的类别
self.cls_fc = nn.Linear(in_features=self.hidden_size*2 if direction == "bidirectional" else hidden_size,
out_features=self.n_classes)
def forward(self, inputs):
# 获取训练的batch_size
batch_size = inputs.shape[0]
# 获取词向量并且进行dropout
embedded_input = self.embedding(inputs)
if self.dropout_rate > 0.:
embedded_input = self.dropout_emb(embedded_input)
# 使用LSTM 进行语义编码
last_layers_hiddens, (last_step_hiddens, last_step_cells) = self.lstm(embedded_input)
# 进行Attention, attn_weights: [batch_size, seq_len]
attn_vectors = self.attention(last_layers_hiddens)
# 将其通过分类线性层,获得初步的类别数值
logits = self.cls_fc(attn_vectors)
return logits
# 加载数据集
root_path = "./dataset/"
train_set, test_set, word_dict, label_dict = load_dataset(root_path)
train_set = convert_corpus_to_id(train_set, word_dict, label_dict)
test_set = convert_corpus_to_id(test_set, word_dict, label_dict)
id2label = dict([(item[1], item[0]) for item in label_dict.items()])
# 参数设置
n_epochs = 3 #训练轮数
vocab_size = len(word_dict.keys()) #词典大小
print(vocab_size)
batch_size = 128 #每个batch 中包含样本数目
hidden_size = 128 #LSTM 的隐藏层大小
embedding_size = 128 #词嵌入的维度
n_classes = 14 #分类类别数
max_seq_len = 32 #序列的最大长度
n_layers = 1 #LSTM 的层数
dropout_rate = 0.2 #dropout 的比率
learning_rate = 0.0001 #学习率
direction = "bidirectional" #LSTM 是否为双向
# 检测是否可以使用GPU,如果可以优先使用GPU
use_gpu = torch.cuda.is_available()
if use_gpu:
device = torch.device("cuda:0")
print("使用GPU训练: ", torch.cuda.get_device_name(0))
else:
device = torch.device("cpu")
print("使用CPU训练")
# 实例化模型
classifier = Classifier(hidden_size, embedding_size, vocab_size, n_classes=n_classes, n_layers=n_layers,
direction=direction, dropout_rate=dropout_rate)
# 将模型移到GPU
classifier = classifier.to(device)
# 指定优化器
optimizer = optim.Adam(classifier.parameters(), lr=learning_rate, betas=(0.9, 0.99))
# 定义模型评估类
class Metric:
def __init__(self, id2label):
self.id2label = id2label
self.reset()
def reset(self):
self.total_samples = 0
self.total_corrects = 0
def update(self, real_labels, pred_labels):
self.total_samples += real_labels.shape[0]
self.total_corrects += np.sum(real_labels == pred_labels)
def get_result(self):
accuracy = self.total_corrects / self.total_samples
return {"accuracy": accuracy}
def format_print(self, result):
print(f"Accuracy: {result['accuracy']:.4f}")
# 模型评估代码
def evaluate(model):
model.eval()
metric = Metric(id2label)
for batch_texts, batch_labels in build_batch(test_set, batch_size, max_seq_len, shuffle=False, pad_id=word_dict["[pad]"]):
batch_texts = torch.tensor(batch_texts).to(device)
batch_labels = torch.tensor(batch_labels).to(device)
logits = model(batch_texts)
probs = F.softmax(logits, dim=1)
preds = probs.argmax(dim=1).cpu().numpy()
batch_labels = batch_labels.squeeze().cpu().numpy()
metric.update(real_labels=batch_labels, pred_labels=preds)
result = metric.get_result()
metric.format_print(result)
# 模型训练代码
loss_records = []
# 修改训练代码,确保数据也移动到相同设备
def train(model):
global_step = 0
for epoch in range(n_epochs):
model.train()
for step, (batch_texts, batch_labels) in enumerate(build_batch(train_set, batch_size, max_seq_len, shuffle=True, pad_id=word_dict["[pad]"])):
batch_texts = torch.tensor(batch_texts).to(device)
batch_labels = torch.tensor(batch_labels).to(device)
logits = model(batch_texts)
batch_labels_flat = batch_labels.view(-1)
loss = F.cross_entropy(input=logits, target=batch_labels_flat, reduction='mean')
loss.backward()
optimizer.step()
optimizer.zero_grad()
if step % 200 == 0:
loss_records.append((global_step, loss.item()))
print(f"Epoch: {epoch+1}/{n_epochs} - Step: {step} - Loss: {loss.item()}")
global_step += 1
evaluate(model)
# 训练模型
train(classifier)
# 训练可视化
loss_records = np.array(loss_records)
steps, losses = loss_records[:, 0], loss_records[:, 1]
plt.plot(steps, losses, "-o")
plt.xlabel("step")
plt.ylabel("loss")
plt.savefig("./loss.png")
plt.show()
# 模型保存
model_name = "classifier"
torch.save(classifier.state_dict(), "{}.pdparams".format(model_name))
torch.save(optimizer.state_dict(), "{}.optparams".format(model_name))
# 模型预测代码
def infer(model, text):
model.eval()
tokens = [word_dict.get(word, word_dict["[oov]"]) for word in jieba.cut(text)]
tokens = torch.LongTensor(tokens).unsqueeze(0).to(device) # 将张量移动到与模型相同的设备
with torch.no_grad():
logits = model(tokens)
probs = F.softmax(logits, dim=1)
max_label_id = torch.argmax(logits, dim=1).item()
pred_label = id2label[max_label_id]
print("Label: ", pred_label)
title = "习近平主席对职业教育工作作出重要指示"
infer(classifier, title)输出结果
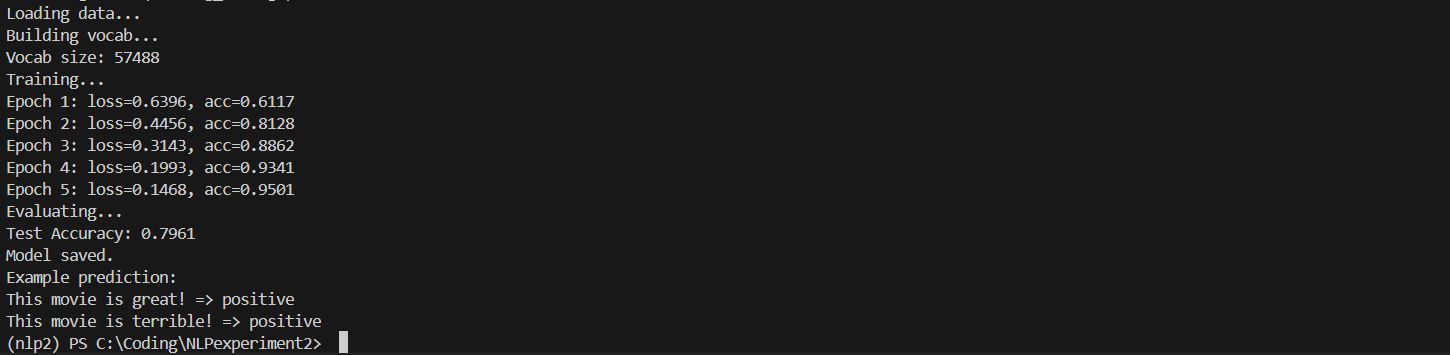
(finbert) PS C:\Coding\NLPexperiment1> & C:/DevelopmentTools/Anaconda3/envs/finbert/python.exe c:/Coding/NLPexperiment1/proj.py
Building prefix dict from the default dictionary …
Loading model from cache C:\Users\yyf\AppData\Local\Temp\jieba.cache
Loading model cost 0.281 seconds.
Prefix dict has been built successfully.
300981
使用GPU训练: NVIDIA GeForce RTX 5080
C:\DevelopmentTools\Anaconda3\envs\finbert\Lib\site-packages\torch\nn\modules\rnn.py:123: UserWarning: dropout option adds dropout after all but last recurrent layer, so non-zero dropout expects num_layers greater than 1, but got dropout=0.2 and num_layers=1
warnings.warn(
Epoch: 1/3 – Step: 0 – Loss: 2.637685775756836
Epoch: 1/3 – Step: 200 – Loss: 2.5390872955322266
Epoch: 1/3 – Step: 400 – Loss: 2.522779703140259
Epoch: 1/3 – Step: 600 – Loss: 2.502384662628174
Epoch: 1/3 – Step: 800 – Loss: 2.5023691654205322
Epoch: 1/3 – Step: 1000 – Loss: 2.578101873397827
Epoch: 1/3 – Step: 1200 – Loss: 2.5146613121032715
Epoch: 1/3 – Step: 1400 – Loss: 2.534858465194702
Epoch: 1/3 – Step: 1600 – Loss: 2.5321693420410156
Epoch: 1/3 – Step: 1800 – Loss: 2.54728102684021
Epoch: 1/3 – Step: 2000 – Loss: 2.6213796138763428
Accuracy: 0.0894
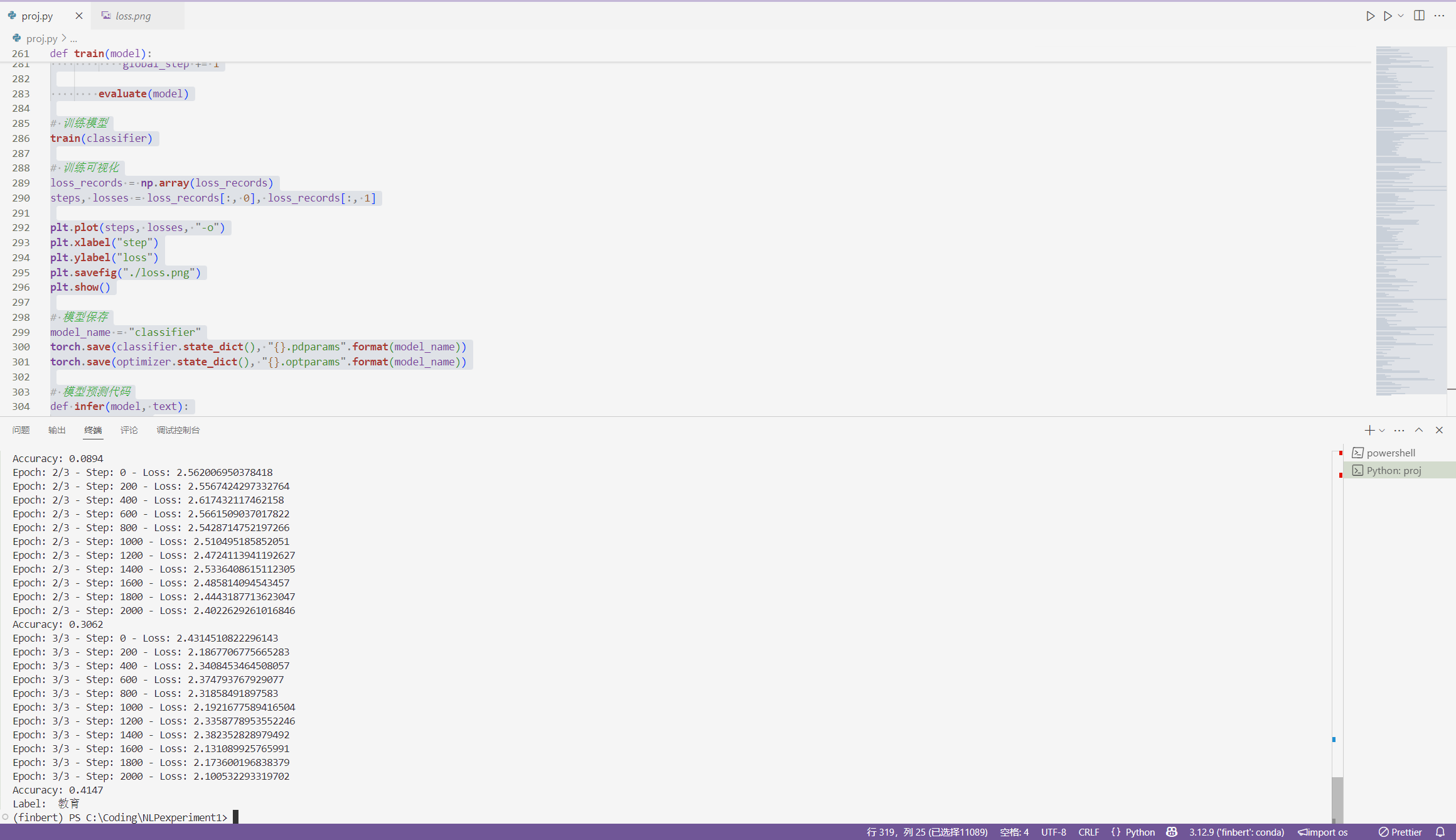
Epoch: 2/3 – Step: 0 – Loss: 2.562006950378418
Epoch: 2/3 – Step: 200 – Loss: 2.5567424297332764
Epoch: 2/3 – Step: 400 – Loss: 2.617432117462158
Epoch: 2/3 – Step: 600 – Loss: 2.5661509037017822
Epoch: 2/3 – Step: 800 – Loss: 2.5428714752197266
Epoch: 2/3 – Step: 1000 – Loss: 2.510495185852051
Epoch: 2/3 – Step: 1200 – Loss: 2.4724113941192627
Epoch: 2/3 – Step: 1400 – Loss: 2.5336408615112305
Epoch: 2/3 – Step: 1600 – Loss: 2.485814094543457
Epoch: 2/3 – Step: 1800 – Loss: 2.4443187713623047
Epoch: 2/3 – Step: 2000 – Loss: 2.4022629261016846
Accuracy: 0.3062
Epoch: 3/3 – Step: 0 – Loss: 2.4314510822296143
Epoch: 3/3 – Step: 200 – Loss: 2.1867706775665283
Epoch: 3/3 – Step: 400 – Loss: 2.3408453464508057
Epoch: 3/3 – Step: 600 – Loss: 2.374793767929077
Epoch: 3/3 – Step: 800 – Loss: 2.31858491897583
Epoch: 3/3 – Step: 1000 – Loss: 2.1921677589416504
Epoch: 3/3 – Step: 1200 – Loss: 2.3358778953552246
Epoch: 3/3 – Step: 1400 – Loss: 2.382352828979492
Epoch: 3/3 – Step: 1600 – Loss: 2.131089925765991
Epoch: 3/3 – Step: 1800 – Loss: 2.173600196838379
Epoch: 3/3 – Step: 2000 – Loss: 2.100532293319702
Accuracy: 0.4147
Label: 教育