摘要
本文旨在记录使用三款开源工具——Superset、Metabase 和 Redash——对 Anscombe 数据集进行数据可视化和最小二乘法回归直线分析的过程。通过这次实验,我希望展示数据可视化的重要性,并对比这些工具在部署、数据处理和分析中的表现。Superset 和 Metabase 将被用于完整分析,而 Redash 由于数据导入的不便被放弃测试。本文将详细介绍工具的部署、数据处理、可视化结果,并总结工具的适用场景。
1 引言
Anscombe 数据集(Anscombe’s Quartet)由统计学家 Francis Anscombe 于 1973 年提出,包含四组数据,每组的均值、方差和相关系数几乎相同,但通过可视化却呈现出截然不同的分布形态。这强调了单纯依赖统计指标的局限性,以及数据可视化的必要性。本文将使用 Superset 和 Metabase 两款工具对 Anscombe 数据集进行可视化和最小二乘法回归分析,同时记录尝试使用 Redash 的过程及其放弃原因。
2 工具介绍与部署
2.1 Superset
2.1.1 工具简介
Superset 是一个功能强大的开源数据探索和可视化平台,由 Apache 基金会维护。它支持连接多种数据库,提供丰富的图表类型和交互式仪表板,适合复杂的数据分析场景。
2.1.2 部署方式
- 通过 SSH 登录 QNAP NAS 后台。

- 在目标目录下克隆 GitHub 上的 Superset 仓库(git clone https://github.com/apache/superset.git)。

- 编辑 docker-compose-non-dev.yml 文件,调整配置(如端口、数据库连接等)。
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# -----------------------------------------------------------------------
# We don't support docker compose for production environments.
# If you choose to use this type of deployment make sure to
# create you own docker environment file (docker/.env) with your own
# unique random secure passwords and SECRET_KEY.
# -----------------------------------------------------------------------
x-superset-volumes:
&superset-volumes
- ./docker:/app/docker
- E:/Software/Foreign/superset/save/data:/app/superset_home
x-common-build: &common-build
context: .
target: dev
cache_from:
- apache/superset-cache:3.10-slim-bookworm
services:
redis:
image: redis:7
container_name: superset_cache
restart: unless-stopped
volumes:
- E:/Software/Foreign/superset/save/redis:/data
db:
env_file:
- path: docker/.env
required: true
- path: docker/.env-local
required: false
image: postgres:15
container_name: superset_db
restart: unless-stopped
volumes:
- E:/Software/Foreign/superset/save/db:/var/lib/postgresql/data
- ./docker/docker-entrypoint-initdb.d:/docker-entrypoint-initdb.d
superset:
env_file:
- path: docker/.env
required: true
- path: docker/.env-local
required: false
build:
<<: *common-build
container_name: superset_app
command: ["/app/docker/docker-bootstrap.sh", "app-gunicorn"]
user: "root"
restart: unless-stopped
ports:
- 10010:8088
depends_on:
superset-init:
condition: service_completed_successfully
volumes: *superset-volumes
environment:
SUPERSET_LOG_LEVEL: "${SUPERSET_LOG_LEVEL:-info}"
superset-init:
container_name: superset_init
build:
<<: *common-build
command: ["/app/docker/docker-init.sh"]
env_file:
- path: docker/.env
required: true
- path: docker/.env-local
required: false
depends_on:
db:
condition: service_started
redis:
condition: service_started
user: "root"
volumes: *superset-volumes
healthcheck:
disable: true
environment:
SUPERSET_LOAD_EXAMPLES: "${SUPERSET_LOAD_EXAMPLES:-yes}"
SUPERSET_LOG_LEVEL: "${SUPERSET_LOG_LEVEL:-info}"
superset-worker:
build:
<<: *common-build
container_name: superset_worker
command: ["/app/docker/docker-bootstrap.sh", "worker"]
env_file:
- path: docker/.env
required: true
- path: docker/.env-local
required: false
restart: unless-stopped
depends_on:
superset-init:
condition: service_completed_successfully
user: "root"
volumes: *superset-volumes
healthcheck:
test:
[
"CMD-SHELL",
"celery -A superset.tasks.celery_app:app inspect ping -d celery@$$HOSTNAME",
]
environment:
SUPERSET_LOG_LEVEL: "${SUPERSET_LOG_LEVEL:-info}"
superset-worker-beat:
build:
<<: *common-build
container_name: superset_worker_beat
command: ["/app/docker/docker-bootstrap.sh", "beat"]
env_file:
- path: docker/.env
required: true
- path: docker/.env-local
required: false
restart: unless-stopped
depends_on:
superset-init:
condition: service_completed_successfully
user: "root"
volumes: *superset-volumes
healthcheck:
disable: true
environment:
SUPERSET_LOG_LEVEL: "${SUPERSET_LOG_LEVEL:-info}"
导航到有docker-compose-non-dev.yml目录即可
docker compose -f docker-compose-non-dev.yml up
最后除了superset_init之外其余的容器是打开状态即可- 执行命令 docker compose -f docker-compose-non-dev.yml up 启动服务。
- 部署完成后,通过 NAS 的 IP 地址加端口号(例如 http://<NAS_IP>:8088)访问 Superset 的 Web 界面。
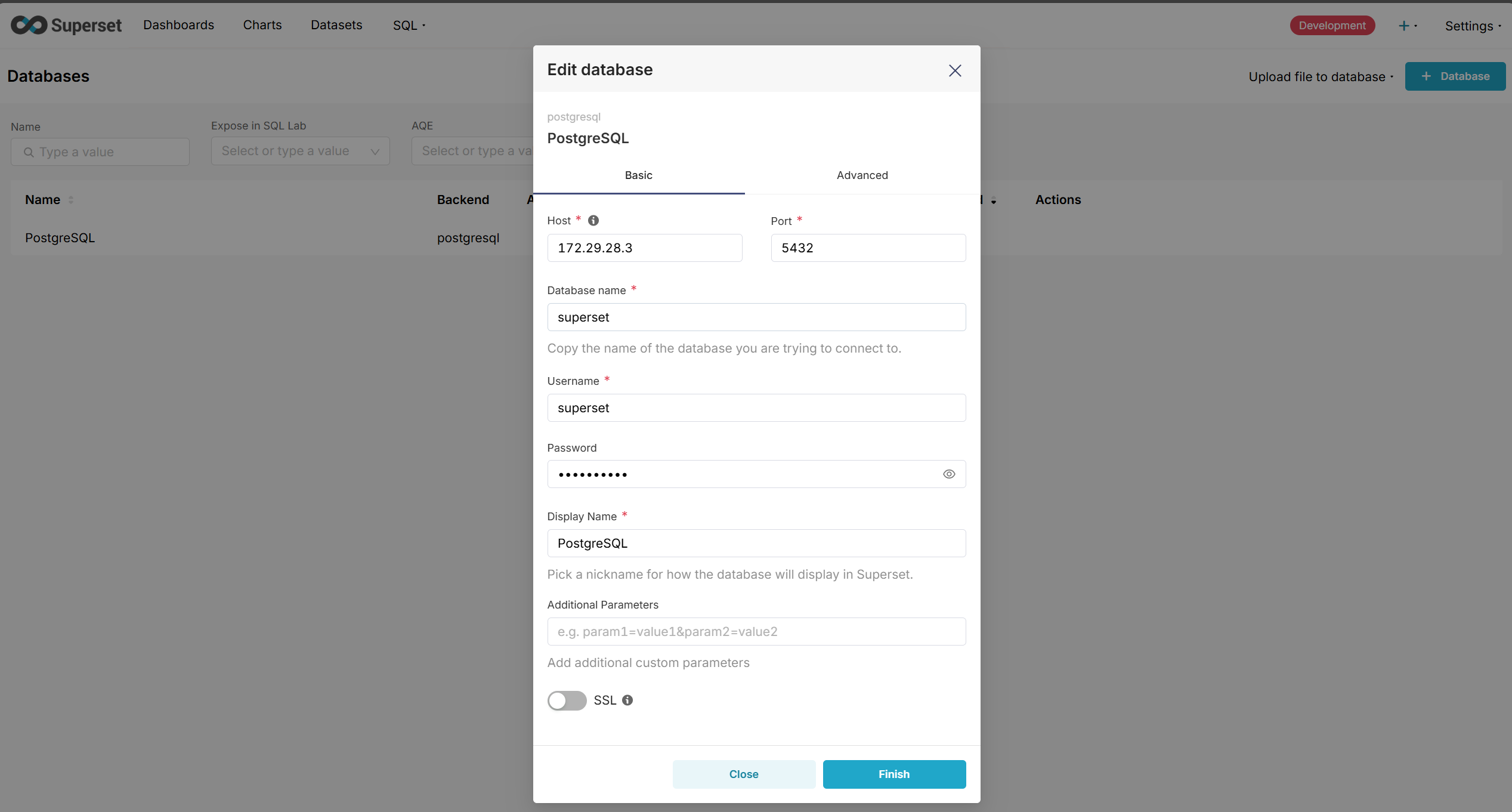
- 连接 PostgreSQL 数据库,为后续数据导入做准备。
- 后续步骤
将 Anscombe 数据集导入 PostgreSQL,进行可视化和回归分析(详见下文)。
2.2 Metabase
2.2.1 工具简介
Metabase 是一个简单易用的开源数据可视化工具,面向非技术用户,提供直观的界面和多种数据源支持。它适合快速构建图表和仪表板。
2.2.2 部署方式
- 使用 Docker Compose 创建一个最新版本的 MySQL 数据库容器(例如 docker-compose.yml 中定义 MySQL 服务)。
version: '3.8'
services:
mysql:
image: mysql:latest # 使用 MySQL 最新的稳定版镜像
container_name: mysql-container
environment:
MYSQL_ROOT_PASSWORD: 1231512315 # 设置 MySQL 根密码
MYSQL_DATABASE: your_database # 创建默认数据库(可选)
volumes:
- /share/Container/mysql:/var/lib/mysql # 映射本地目录到容器中的数据库数据存储目录
ports:
- "3306:3306" # 映射容器的 3306 端口到宿主机的 3306 端口,方便外部访问
networks:
- mysql # 配置容器网络(后续容器可以通过该网络连接 MySQL)
networks:
mysql: # 创建一个自定义网络,MySQL 和其他应用容器将连接到这个网络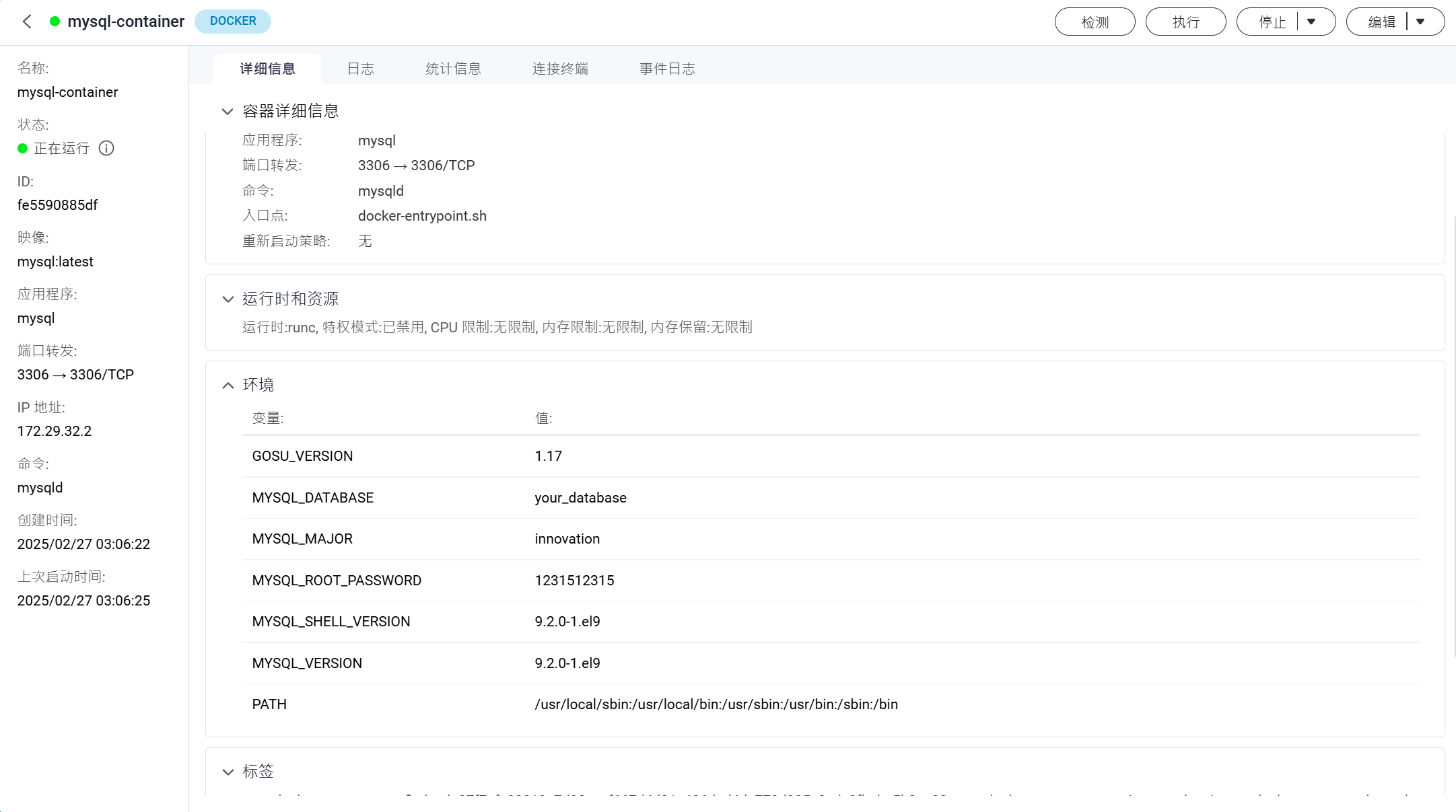
- 在另一 docker-compose.yml 文件中定义 Metabase 容器,并将其连接到 MySQL 的 Docker 网络。
version: "3.8"
services:
metabase:
image: metabase/metabase:latest
container_name: metabase
hostname: metabase
volumes:
- /share/Container/metabase/data:/metabase_data
ports:
- 10011:3000
networks:
- mysql_mysql
networks:
mysql_mysql:
external: true # 使用外部网络 mysql- 执行 docker compose up 启动服务。
- 部署成功后,通过浏览器访问 Metabase 的 Web 界面(默认端口 3000,例如 http://localhost:3000)。
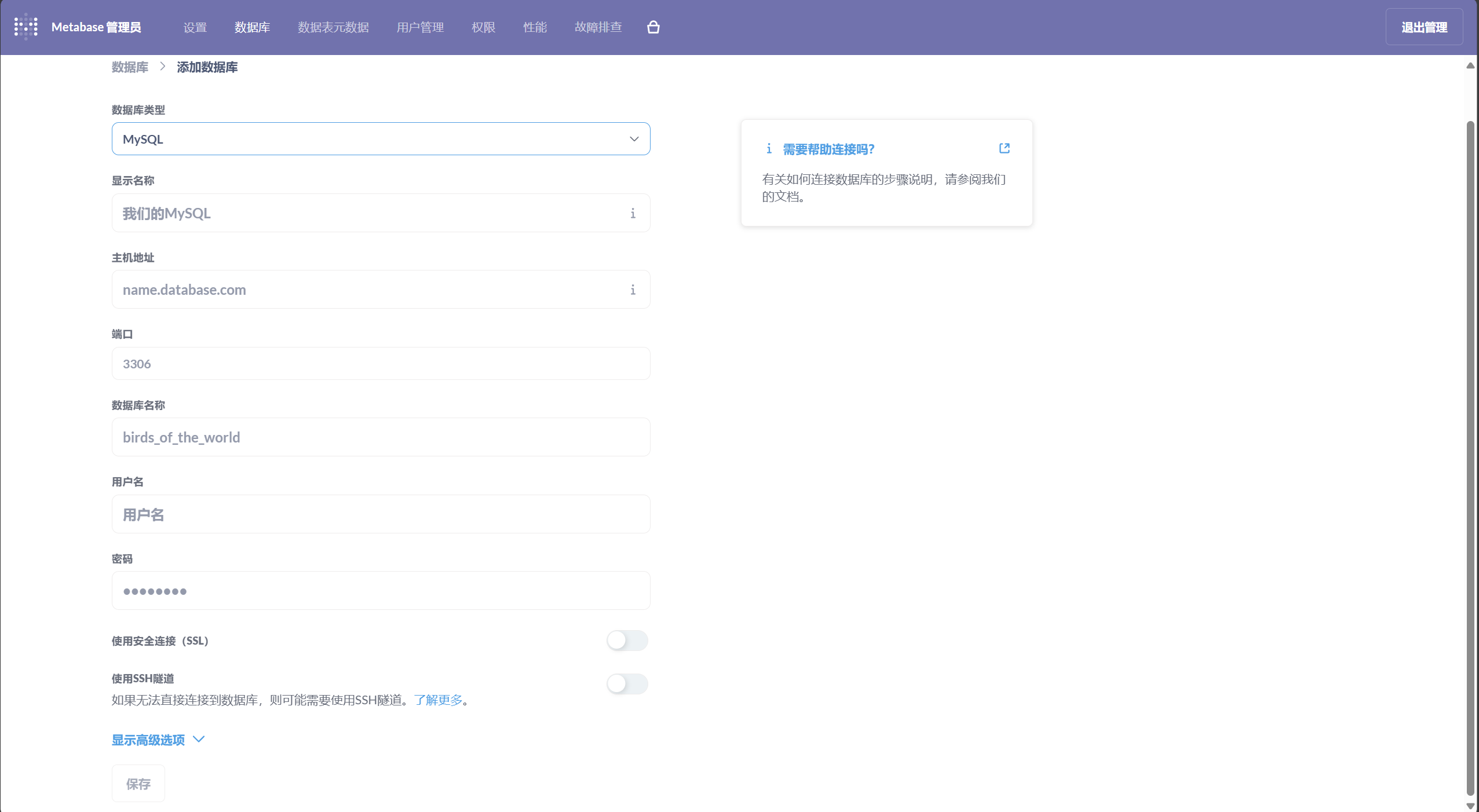
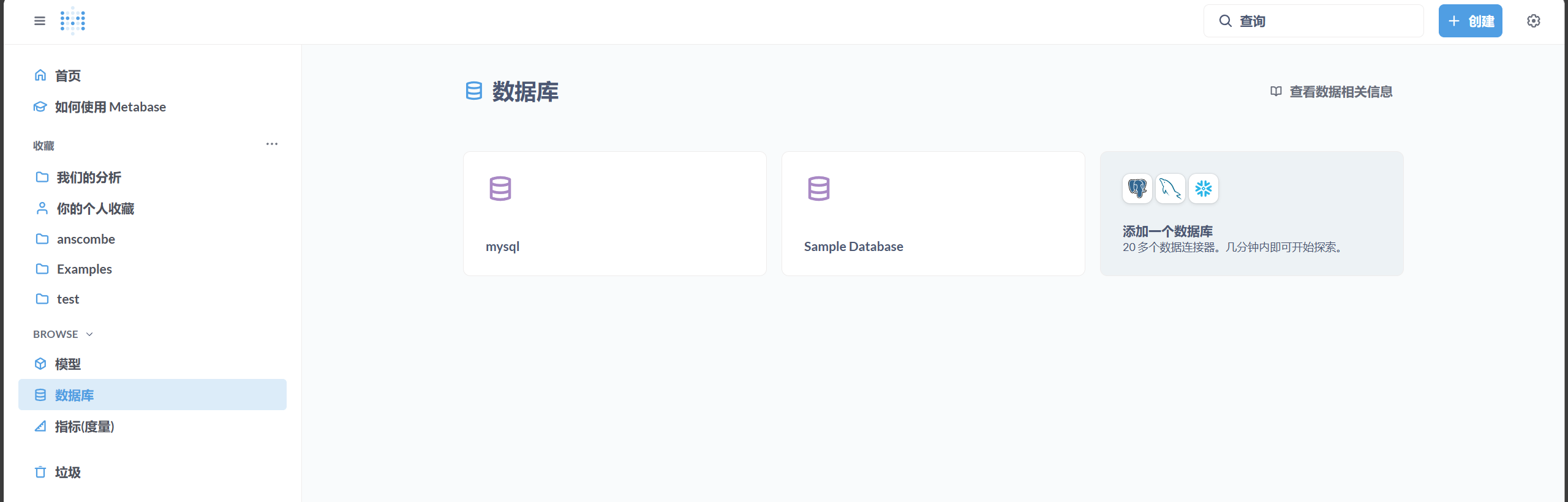
- 配置 MySQL 数据源,准备导入数据。
- 后续步骤
将 Anscombe 数据集导入 MySQL,进行可视化和回归分析(详见下文)。
2.3 Redash
2.3.1 工具简介
Redash 是一个开源的数据可视化工具,支持自定义 SQL 查询和仪表板创建,适合需要灵活查询的场景。
2.3.2 部署方式
- 使用 Docker Compose 部署,类似 Metabase 的流程(定义数据库和 Redash 服务)。
- 启动服务并访问 Web 界面。
2.3.3 问题与放弃
在配置数据库后,我查阅文档发现 Redash 不支持直接上传 CSV 文件导入数据。数据导入需通过 SQL 手动写入,或将文件上传至云端后使用 URL 加载。这对本次实验(直接使用本地 CSV 文件)极为不便,因此放弃测试 Redash。
3 数据准备
3.1 Anscombe 数据集简介
Anscombe 数据集包含四组数据(I、II、III、IV),每组有 11 对 (x, y) 数据点。四组数据的均值、方差和线性回归系数几乎相同,但散点图形态差异显著,分别是线性关系、曲线关系、离群点干扰的线性关系和垂直分布。
3.2 数据处理
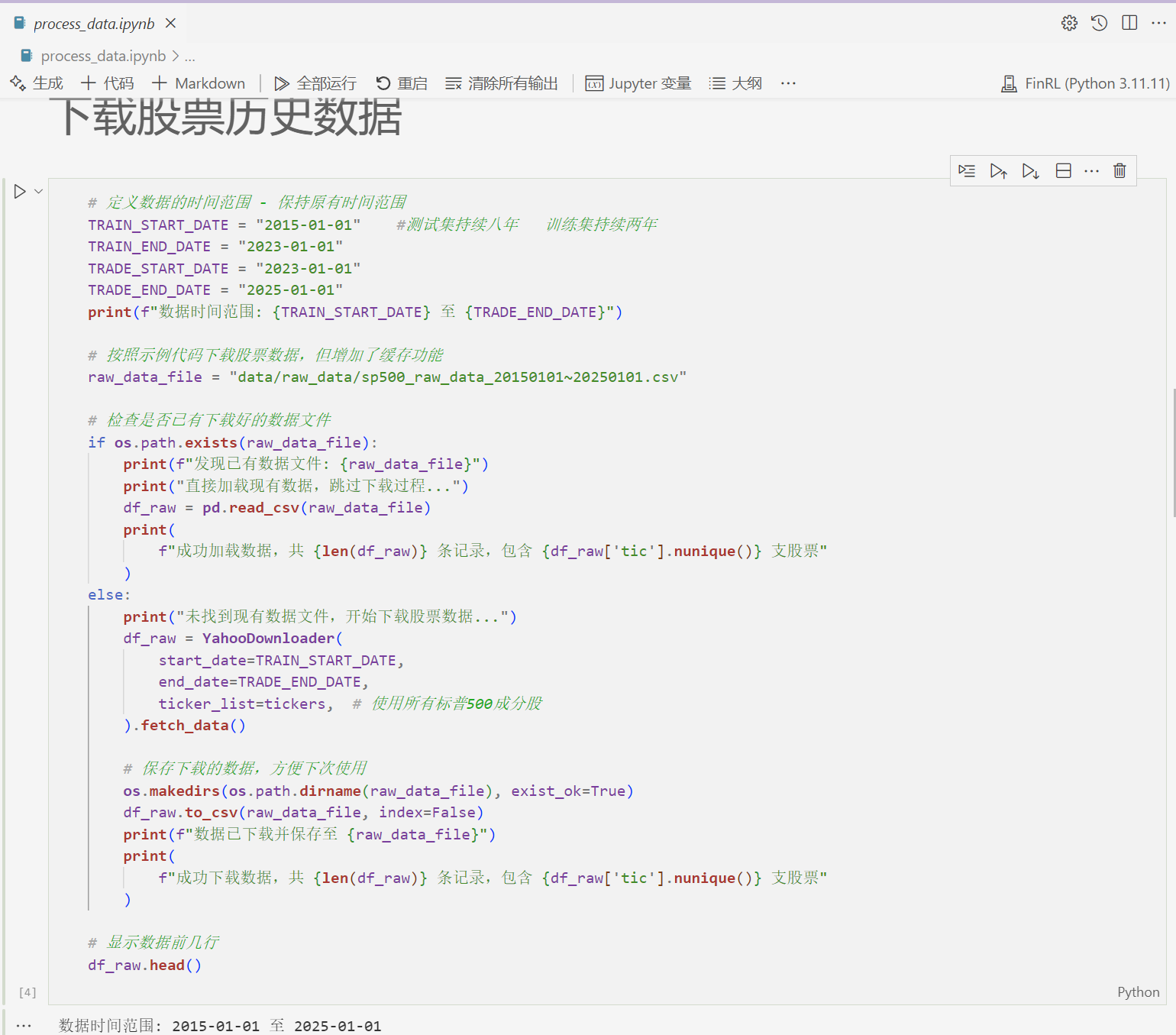
- 使用 Python 编写代码,将 Anscombe 数据集生成并保存为 CSV 文件。
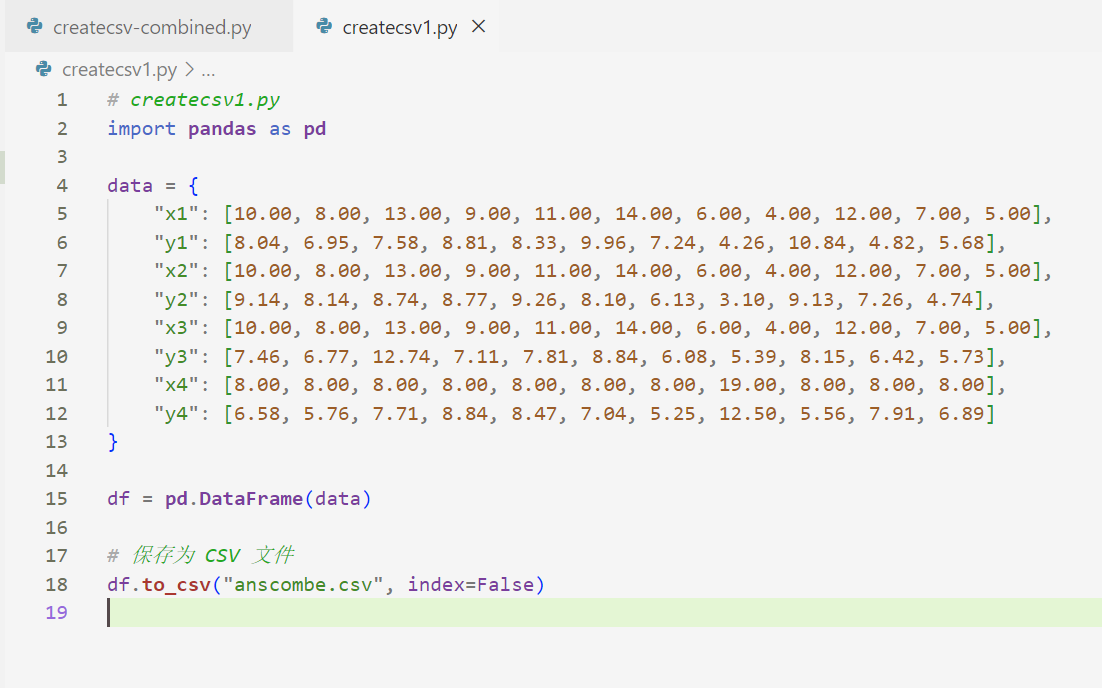
- python代码
# createcsv1.py
import pandas as pd
data = {
"x1": [10.00, 8.00, 13.00, 9.00, 11.00, 14.00, 6.00, 4.00, 12.00, 7.00, 5.00],
"y1": [8.04, 6.95, 7.58, 8.81, 8.33, 9.96, 7.24, 4.26, 10.84, 4.82, 5.68],
"x2": [10.00, 8.00, 13.00, 9.00, 11.00, 14.00, 6.00, 4.00, 12.00, 7.00, 5.00],
"y2": [9.14, 8.14, 8.74, 8.77, 9.26, 8.10, 6.13, 3.10, 9.13, 7.26, 4.74],
"x3": [10.00, 8.00, 13.00, 9.00, 11.00, 14.00, 6.00, 4.00, 12.00, 7.00, 5.00],
"y3": [7.46, 6.77, 12.74, 7.11, 7.81, 8.84, 6.08, 5.39, 8.15, 6.42, 5.73],
"x4": [8.00, 8.00, 8.00, 8.00, 8.00, 8.00, 8.00, 19.00, 8.00, 8.00, 8.00],
"y4": [6.58, 5.76, 7.71, 8.84, 8.47, 7.04, 5.25, 12.50, 5.56, 7.91, 6.89]
}
df = pd.DataFrame(data)
# 保存为 CSV 文件
df.to_csv("anscombe.csv", index=False)# createcsv-combined.py
import pandas as pd
# 原始数据
data = {
'x1': [10.00, 8.00, 13.00, 9.00, 11.00, 14.00, 6.00, 4.00, 12.00, 7.00, 5.00],
'y1': [8.04, 6.95, 7.58, 8.81, 8.33, 9.96, 7.24, 4.26, 10.84, 4.82, 5.68],
'x2': [10.00, 8.00, 13.00, 9.00, 11.00, 14.00, 6.00, 4.00, 12.00, 7.00, 5.00],
'y2': [9.14, 8.14, 8.74, 8.77, 9.26, 8.10, 6.13, 3.10, 9.13, 7.26, 4.74],
'x3': [10.00, 8.00, 13.00, 9.00, 11.00, 14.00, 6.00, 4.00, 12.00, 7.00, 5.00],
'y3': [7.46, 6.77, 12.74, 7.11, 7.81, 8.84, 6.08, 5.39, 8.15, 6.42, 5.73]
}
df = pd.DataFrame(data)
# 重塑为长格式
df_long = pd.concat([
df[['x1', 'y1']].rename(columns={'x1': 'x', 'y1': 'y'}).assign(dataset='D1'),
df[['x2', 'y2']].rename(columns={'x2': 'x', 'y2': 'y'}).assign(dataset='D2'),
df[['x3', 'y3']].rename(columns={'x3': 'x', 'y3': 'y'}).assign(dataset='D3')
])
# 保存为 CSV
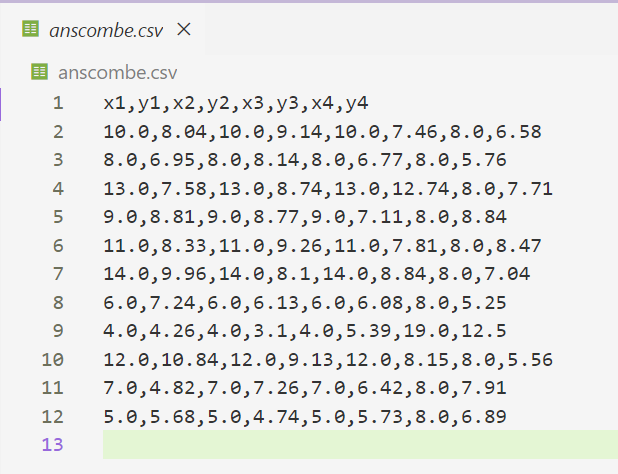
df_long.to_csv('anscombe_combined.csv', index=False)- 生成的 anscombe.csv 文件将用于导入 Superset 和 Metabase。
4 可视化与回归分析
4.1 Superset
4.1.1 数据导入
- 将 anscombe.csv 文件导入 PostgreSQL 数据库(可通过 psql 命令或 Superset 的上传功能)。
4.1.2 可视化
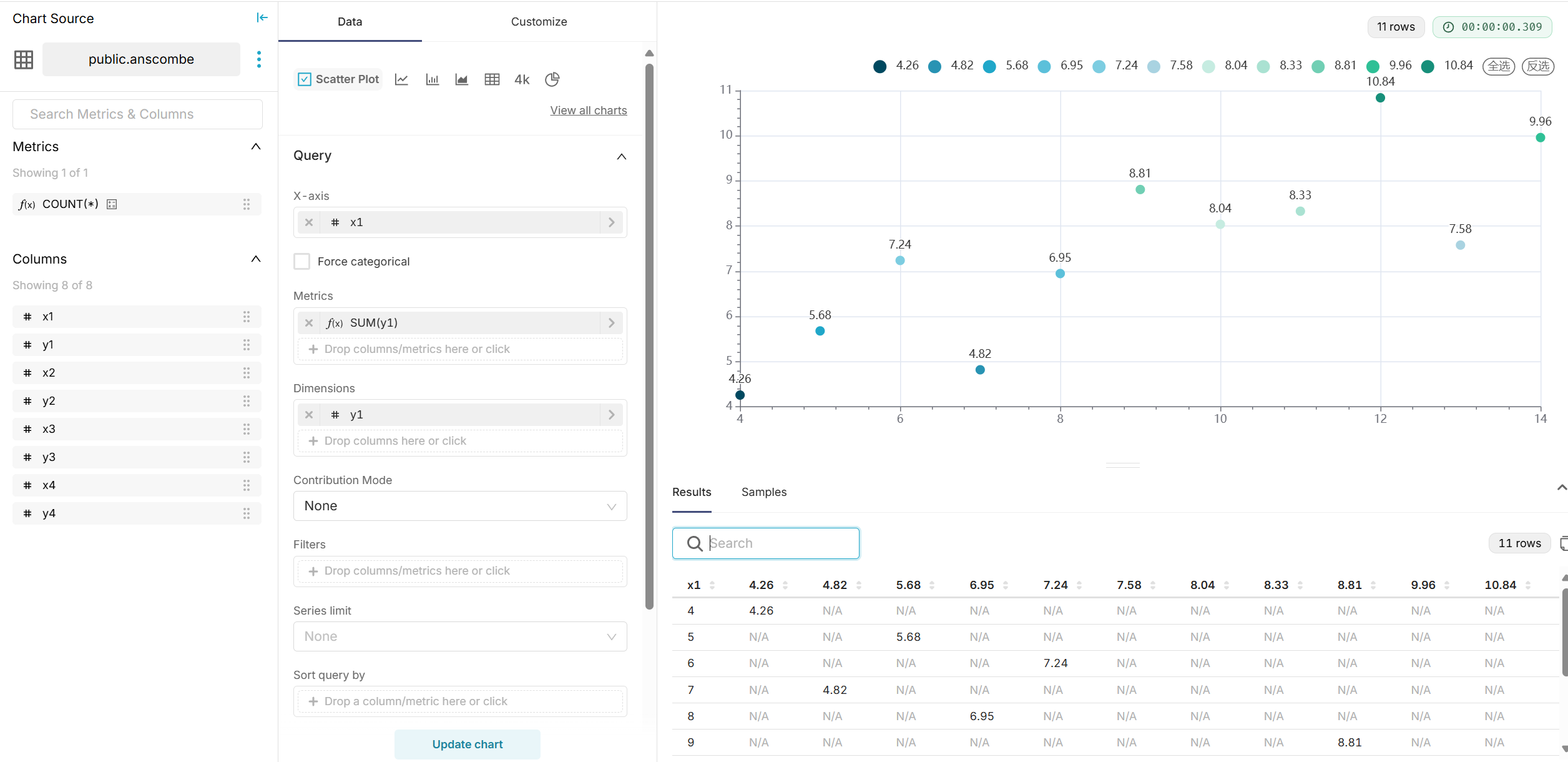
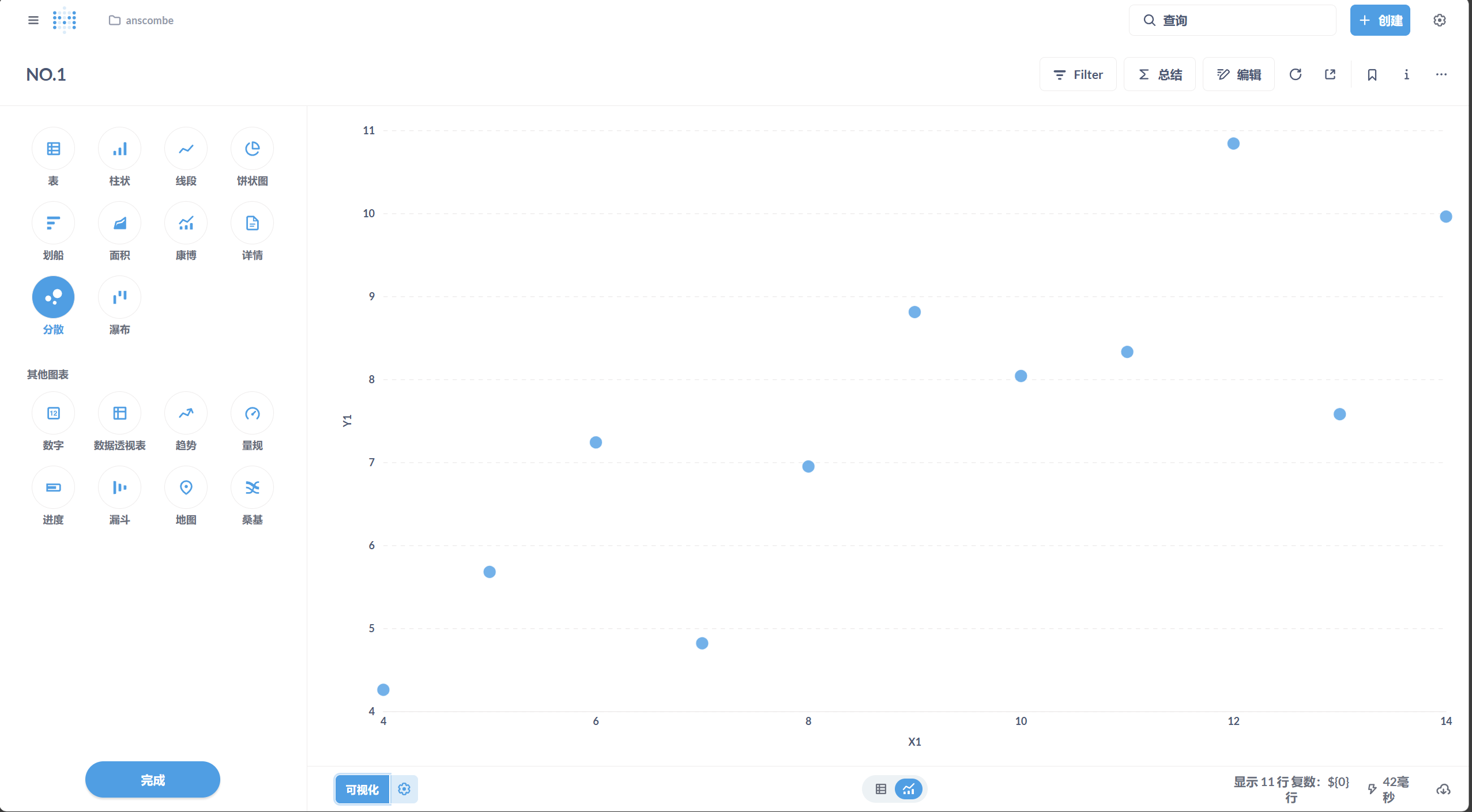
- 在 Superset 中创建数据集,选择四组数据分别绘制散点图。
- 配置图表参数,展示每组数据的分布。(以下是其中一张图片的示例)
4.1.3 回归分析
- 使用 SQL 查询计算最小二乘法回归直线。
- 示例 SQL:
WITH regression_lines AS (
SELECT
'Group 1' AS group_name,
regr_slope(y1, x1) AS slope,
regr_intercept(y1, x1) AS intercept
FROM anscombe
UNION ALL
SELECT
'Group 2' AS group_name,
regr_slope(y2, x2) AS slope,
regr_intercept(y2, x2) AS intercept
FROM anscombe
UNION ALL
SELECT
'Group 3' AS group_name,
regr_slope(y3, x3) AS slope,
regr_intercept(y3, x3) AS intercept
FROM anscombe
UNION ALL
SELECT
'Group 4' AS group_name,
regr_slope(y4, x4) AS slope,
regr_intercept(y4, x4) AS intercept
FROM anscombe
)
SELECT
group_name,
x,
slope * x + intercept AS y_pred
FROM generate_series(1, 20) AS x -- 生成x值范围
JOIN regression_lines
ON group_name = 'Group 1' -- 根据group_name选择正确的斜率和截距
OR group_name = 'Group 2'
OR group_name = 'Group 3'
OR group_name = 'Group 4';
4.1.4 完整结果面板
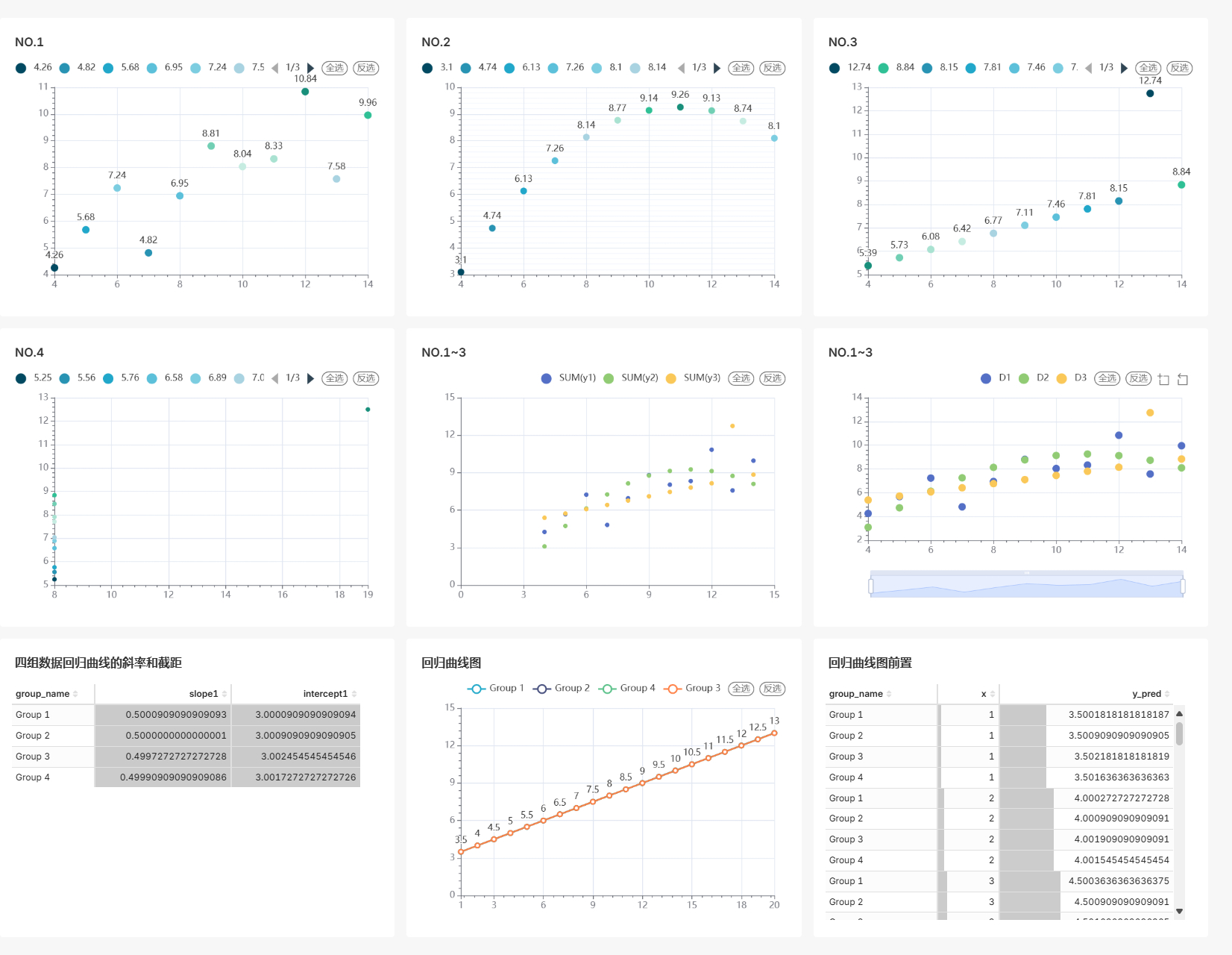
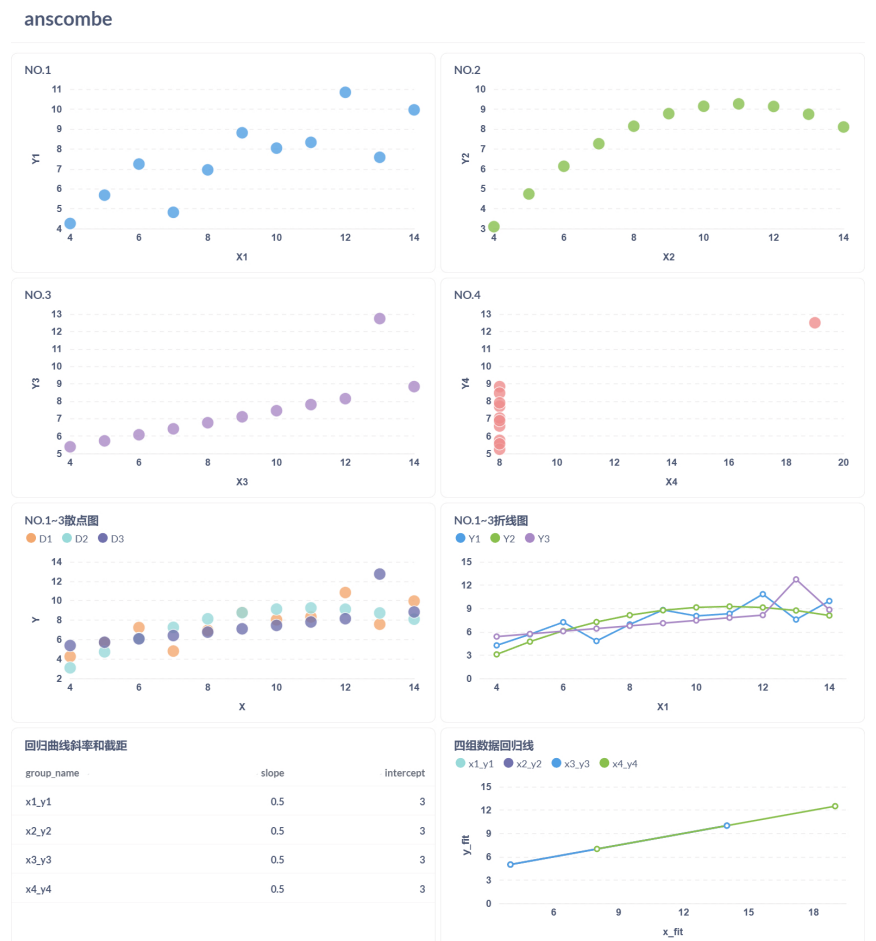
4.2 Metabase
4.2.1 数据导入
- 将 anscombe.csv 文件导入 MySQL 数据库 。
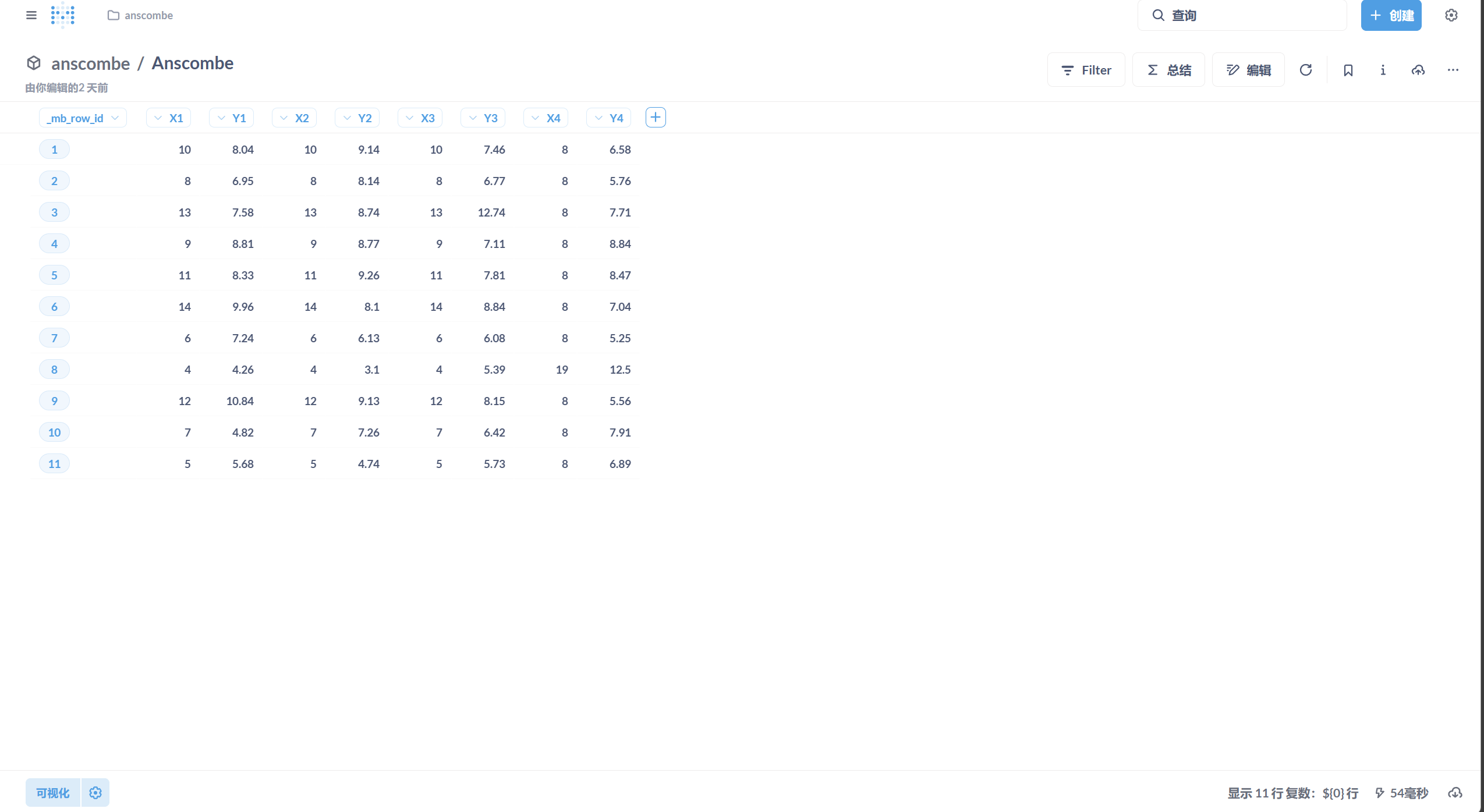
4.2.2 可视化
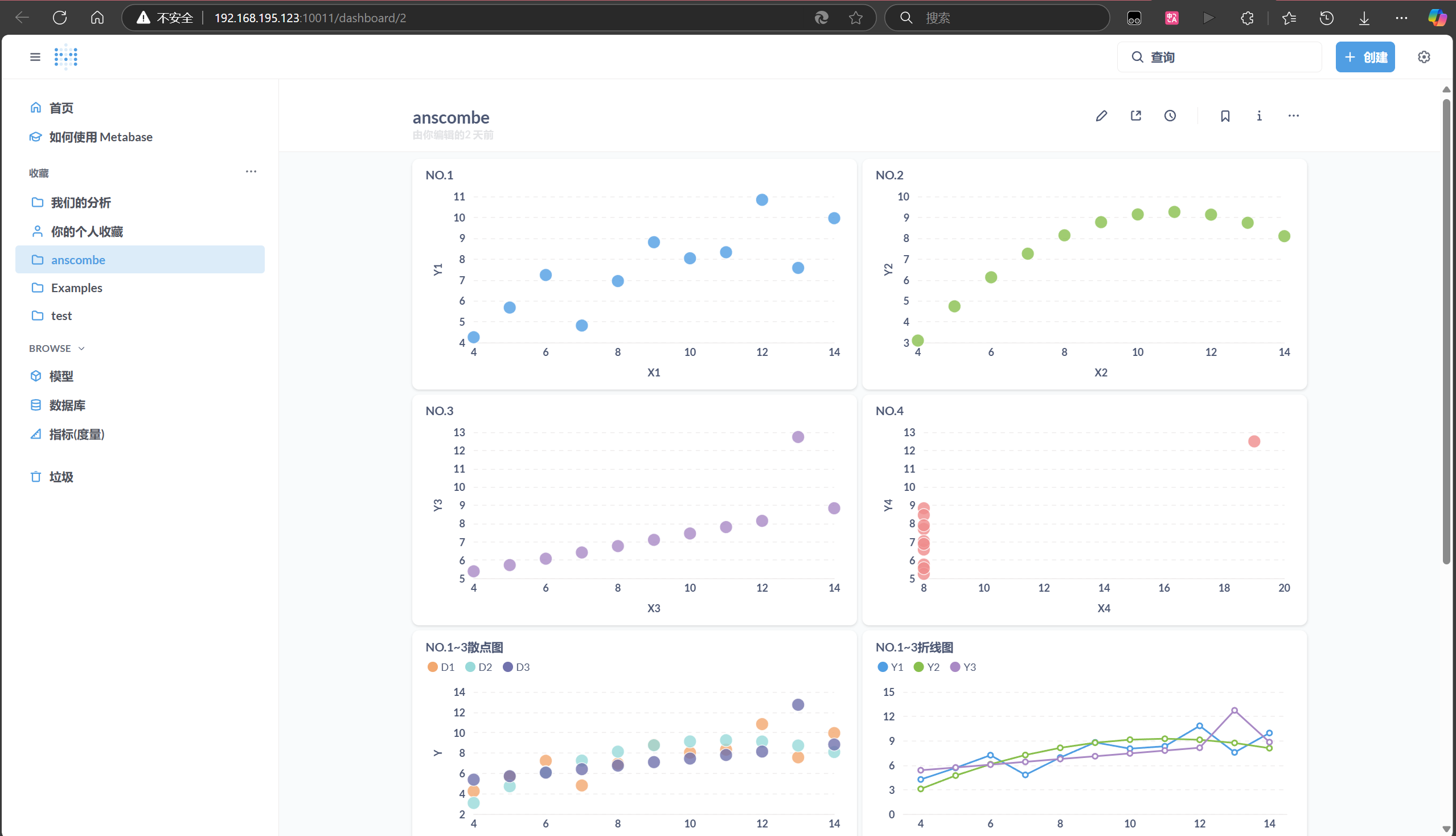
- 在 Metabase 中选择数据表,创建散点图,分别展示四组数据的分布。
4.2.3 回归分析
- 使用 SQL 查询计算最小二乘法回归直线。
- 示例 SQL:
-- x1_y1 回归线
SELECT 'x1_y1' AS group_name, 4.0 AS x_fit, (0.5001 * 4.0 + 3.0001) AS y_fit
UNION ALL
SELECT 'x1_y1' AS group_name, 14.0 AS x_fit, (0.5001 * 14.0 + 3.0001) AS y_fit
UNION ALL
-- x2_y2 回归线
SELECT 'x2_y2' AS group_name, 4.0 AS x_fit, (0.5000 * 4.0 + 3.0025) AS y_fit
UNION ALL
SELECT 'x2_y2' AS group_name, 14.0 AS x_fit, (0.5000 * 14.0 + 3.0025) AS y_fit
UNION ALL
-- x3_y3 回归线
SELECT 'x3_y3' AS group_name, 4.0 AS x_fit, (0.4997 * 4.0 + 3.0017) AS y_fit
UNION ALL
SELECT 'x3_y3' AS group_name, 14.0 AS x_fit, (0.4997 * 14.0 + 3.0017) AS y_fit
UNION ALL
-- x4_y4 回归线
SELECT 'x4_y4' AS group_name, 8.0 AS x_fit, (0.4999 * 8.0 + 3.0027) AS y_fit
UNION ALL
SELECT 'x4_y4' AS group_name, 19.0 AS x_fit, (0.4999 * 19.0 + 3.0027) AS y_fit4.2.4 完整结果面板
4.3 Redash
- 未执行分析
由于无法直接上传 CSV 文件,且手动导入数据过于繁琐,未对 Redash 进行进一步测试。
5 结论
Anscombe 数据集分析报告
5.1 Anscombe 数据集的背景
Anscombe 数据集(Anscombe’s Quartet)由统计学家 Francis Anscombe 于 1973 年创建,包含四组数据(I、II、III、IV),每组有 11 对 $(x, y)$ 数据点。这个数据集的独特之处在于,尽管四组数据的统计特征(如均值、方差、相关系数)几乎相同,但它们的分布形态却截然不同。这强调了数据可视化在统计分析中的重要性。
5.2 统计特征概述
在分析分布特征之前,我们先来看四组数据的统计特征:
- 均值:
- $\bar{x} = 9.0$ (所有四组的 x 均值)
- $\bar{y} = 7.5$ (所有四组的 y 均值)
- 方差:
- $\text{Var}(x) = 11$ (所有四组的 x 方差)
- $\text{Var}(y) = 4.12$ (所有四组的 y 方差)
- 相关系数:
- $r = 0.816$ (所有四组的 x 和 y 之间的相关系数)
- 线性回归:
- 每组的回归直线均为 $y = 3.0 + 0.5x$
这些统计指标表明,如果仅从数值上看,四组数据似乎非常相似。然而,可视化揭示了它们的真实分布差异。
5.3 四组数据的分布特征分析
以下是基于可视化结果对四组数据分布特征的详细描述:
5.3.1 组 I:线性关系
- 分布特征: 数据点大致沿着一条直线分布,呈现出明显的线性关系。没有显著的异常值或非线性模式。
- 统计特征支持: 相关系数 $r = 0.816$ 表明 $x$ 和 $y$ 之间存在较强的正相关,这与可视化中的线性趋势一致。
- 可视化观察: 散点图显示数据点紧密围绕回归直线 $y = 3.0 + 0.5x$,拟合效果良好。
5.3.2 组 II:曲线关系
- 分布特征: 数据点呈现抛物线形态,表明 $x$ 和 $y$ 之间存在非线性关系。
- 统计特征支持: 尽管相关系数 $r = 0.816$ 显示正相关,但线性回归直线 $y = 3.0 + 0.5x$ 无法准确描述这种曲线分布。
- 可视化观察: 散点图显示数据点沿一条曲线排列,回归直线偏离实际分布,提示需要非线性模型。
5.3.3 组 III:异常值影响的线性关系
- 分布特征: 大多数数据点呈线性分布,但存在一个显著的异常值(离群点),该点对回归直线产生了较大影响。
- 统计特征支持: 均值和方差受异常值影响较小,但回归直线的斜率和截距被异常值拉偏,仍保持 $y = 3.0 + 0.5x$。
- 可视化观察: 散点图显示除一个离群点外,其余点接近直线分布,异常值使回归直线偏离大多数数据点的趋势。
5.3.4 组 IV:垂直分布
- 分布特征: 大多数 $x$ 值相同(集中在 $x = 8$),只有一个异常点($x = 19$),数据点几乎呈垂直分布。
- 统计特征支持: 相关系数 $r = 0.816$ 和回归直线 $y = 3.0 + 0.5x$ 在此分布下失去意义,因为 $x$ 的变化极小。
- 可视化观察: 散点图显示数据点集中在一条垂直线上,回归直线无法有效描述这种分布。
通过 Superset 和 Metabase 的分析,Anscombe 数据集的四组数据差异通过散点图一目了然,回归直线进一步验证了统计指标的局限性。Superset 适合需要复杂分析的大型项目,而 Metabase 更适合快速部署和简单可视化。Redash 因数据导入问题未被采用,但可能在已有数据库的场景中更有优势。引用 Anscombe 的原始论文,这一实验再次强调了数据可视化的重要性。未来可根据需求选择合适的工具进行数据探索。
5.4 统计公式
以下是分析中用到的关键统计公式的定义:
- 均值: $\bar{x} = \frac{1}{n} \sum_{i=1}^{n} x_i,\quad \bar{y} = \frac{1}{n} \sum_{i=1}^{n} y_i$
- 方差: $\text{Var}(x) = \frac{1}{n-1} \sum_{i=1}^{n} (x_i – \bar{x})^2,\quad \text{Var}(y) = \frac{1}{n-1} \sum_{i=1}^{n} (y_i – \bar{y})^2$
- 相关系数: $r = \frac{\sum_{i=1}^{n} (x_i – \bar{x})(y_i – \bar{y})}{\sqrt{\sum_{i=1}^{n} (x_i – \bar{x})^2 \sum_{i=1}^{n} (y_i – \bar{y})^2}}$
- 线性回归:$y = \beta_0 + \beta_1 x 其中, \beta_1 = \frac{\sum_{i=1}^{n} (x_i – \bar{x})(y_i – \bar{y})}{\sum_{i=1}^{n} (x_i – \bar{x})^2},\quad \beta_0 = \bar{y} – \beta_1 \bar{x}$
这些公式帮助我们计算统计特征,但无法完全揭示分布形态,这正是可视化的价值所在。
参考文献
- Anscombe, F. J. (1973). “Graphs in Statistical Analysis”. The American Statistician.
- Apache Superset 官方文档:https://superset.apache.org/docs/
- Metabase 官方文档:https://www.metabase.com/docs/latest/
- Redash 官方文档:https://redash.io/help/
- Anscombe’s quartet WikiAnscombe’s quartet – Wikipedia