
云计算实验2 -重庆天气数据爬取与空气质量预测系统实验报告

重庆2022-2024年天气数据分析实验报告 一、实验目的 1.1 技术目标 掌握使用Python进行网络爬虫的技术,从指定网站爬取重庆2022-2024年的天气数据。 学习数据预处理方法,包括处理缺失值、标准化数值特征和编码分类变量。 应用机器学习算法(逻辑回归、随机森林、支持向量机)进行空气质量分类预测。 熟悉模型评估方法,生成混淆矩阵、ROC曲线,并分析模型性能。 1.2 实践目标 提升数据分析能力,整合爬虫、预处理和机器学习的全流程。 通过可视化工具(混淆矩阵、ROC曲线)直观展示模型效果。 总结实验中的问题并提出改进方案,培养解决实际问题的能力。 二、实验要求 2.1 数据采集 从t…

CQU CV Project4 人物检测
基于 HOG 特征的人物检测系统讲解 1. 项目概述 1.1 项目背景 人物检测是计算机视觉领域的一个基础问题,具有广泛的应用场景,如智能监控、人流统计、智能驾驶等。在众多人物检测算法中,基于 HOG 特征的检测方法因其良好的检测效果和相对较低的计算复杂度而被广泛应用。本项目基于 OpenCV 实现了一个完整的人物检测系统,支持图像检测、批量处理和参数调优等功能。 1.2 系统功能 本系统主要功能包括: 单图像人物检测:检测单张图像中的人物并显示结果 批量图像处理:批量处理多张图像,使用不同参数组合测试检测效果 参数自定义:支持配置 HOG 检测器的关键参数 结果可视化:将检测结果直观地显示并…
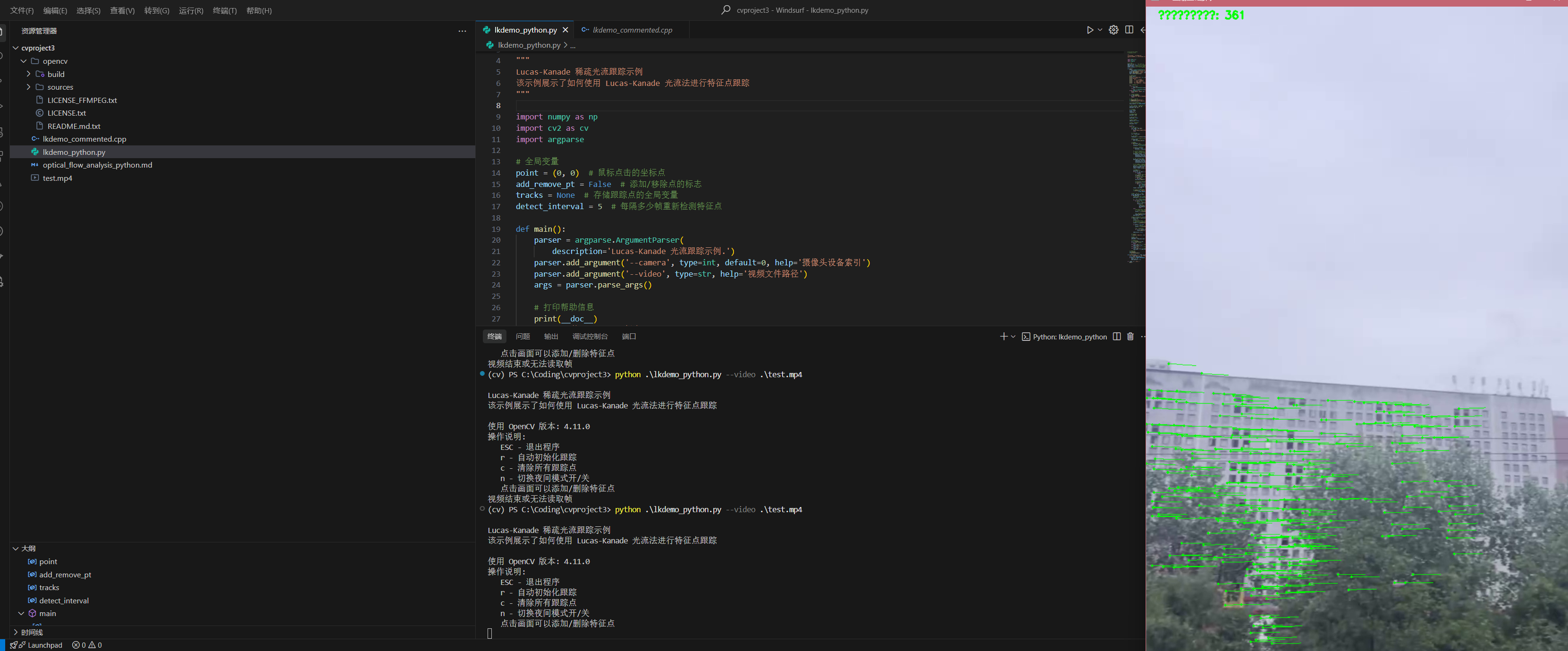
CQU CV Projects3 基于LK光流法的目标追踪
TO DO opencv\samples\cpp\lkdemo.cpp 代码加注释 目标跟踪示例的算法流程图 光流法目标跟踪的基本原理 用不同的测试数据进行实验,分析结果的性能(对光照,仿射,遮挡的鲁棒性);并指出结果中的不足与处理流程中的算法有何关系;若能力优秀尝试进行改进 注释 lkdemo_commented.cpp Lucas-Kanade 光流法目标跟踪分析 1. 算法流程图 +---------------------+ | 开始 | +----------+-------…
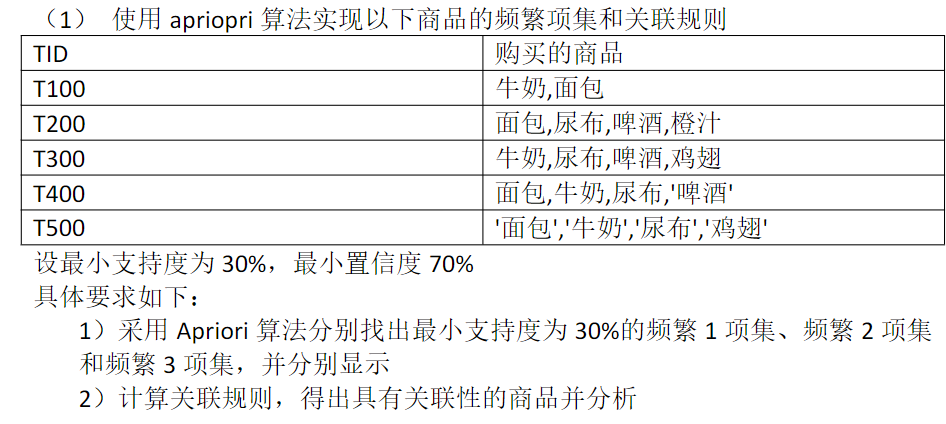
大数据技术计算实验一 (关联分析)
1 实验目的 理解 Apriori 和 FP-growth 算法的基本原理学会用 python 实现 Apriori 算法进行关联分析学会用 python 实现 FP-growth 算法进行关联分析 手写/调库 实现Apriori/FP-growth 算法 在给定置信度,支持度,数据的情况下计算频繁项集,关联规则 2 开发环境 编程软件:anconda/spyder/pycharm环境:python3.6 以上、numpy、pandas、sklearn、Jupyter Notebook 等 3 实验内容及代码 3.1 Apriori 算法 3.1.1 手写 """ Apriori算法纯Pyth…

CQU CV Project2 特征点匹配 基于opencv
opencv/samples/cpp/generic_descriptor_match.cpp at 2.4 · opencv/opencv samples\cpp\generic_descriptor_match.cpp 多种描述符匹配算法,提取图像特征点 #include "opencv2/opencv_modules.hpp" #include <cstdio> // 检查是否包含OpenCV的非自由模块,如果没有则输出错误信息 #ifndef HAVE_OPENCV_NONFREE int main(int, char**) { printf("The sample r…
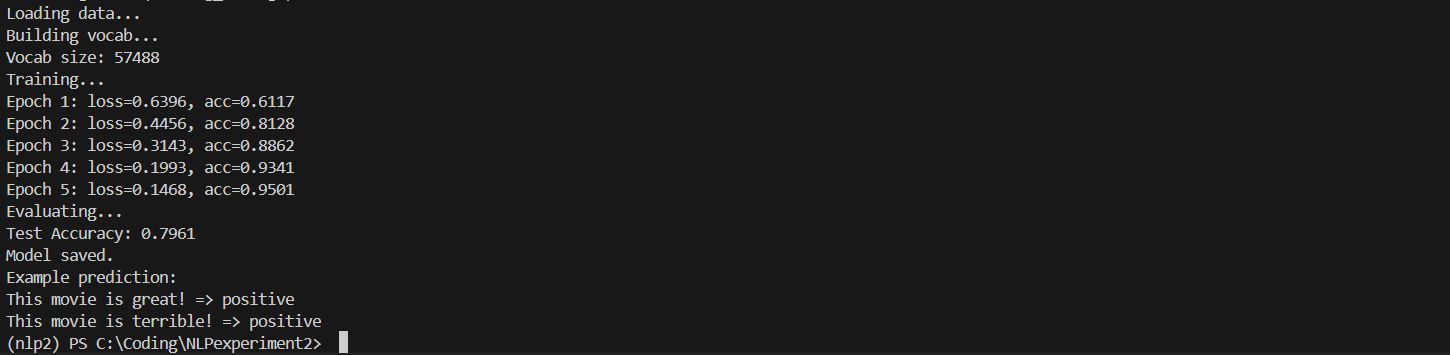
NLP experiment2
正在收集工作区信息# 基于LSTM实现电影评论的情感分析实验报告 1. 项目概述 本项目实现了一个基于长短期记忆网络(LSTM)的电影评论情感分析模型,使用了IMDb电影评论数据集进行训练和测试。模型能够对电影评论文本进行二分类,判断评论情感是正面还是负面。 2. 实验环境 2.1 硬件环境 CPU/GPU配置 内存配置 存储配置 2.2 软件环境 操作系统:Windows/Linux/MacOS Python版本:3.7+ 深度学习框架:PaddlePaddle 依赖包: # requirements.txt中的依赖 paddlepaddle==2.3.0 numpy pandas matp…
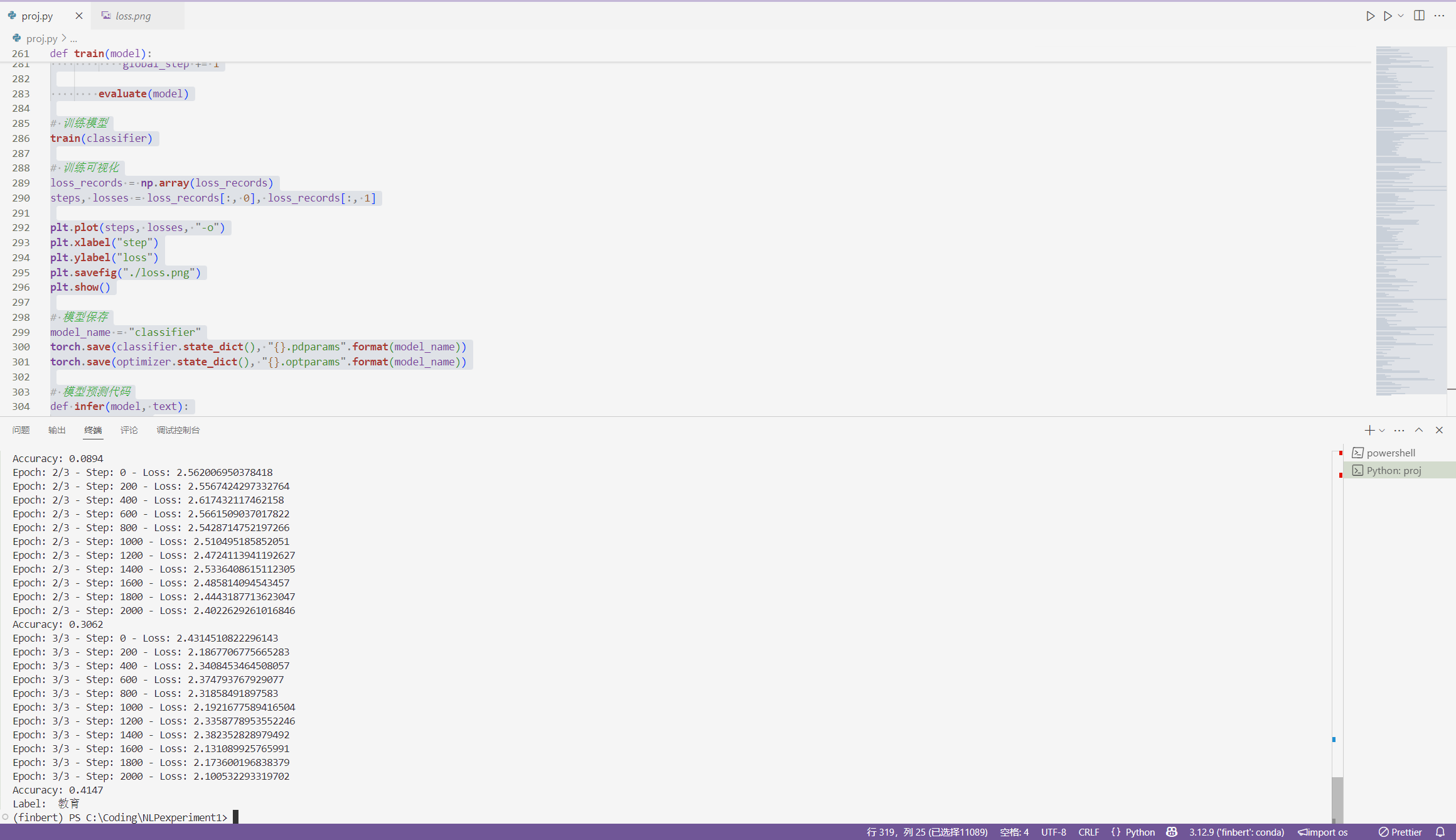
NLPexperiment1 新闻标题分类
NLP文本分类实验报告 1. 引言 1.1 实验背景 本实验实现了一个基于PyTorch的自然语言处理文本分类系统,使用双向LSTM结合注意力机制对中文文本进行多分类任务。实验采用了现代深度学习架构,旨在准确分类新闻文本的类别。 1.2 实验目标 实现一个端到端的文本分类系统 利用深度学习技术提高分类准确率 探索注意力机制在文本分类中的应用 实现GPU加速训练 2. 实验环境 2.1 技术栈 Python 3.x PyTorch - 深度学习框架 jieba - 中文分词库 NumPy - 数值计算库 Matplotlib - 可视化库 2.2 硬件环境 GPU加速支持(CUDA) CPU备选…