
大数据计算 ppt

1 绪论 1.1 什么是大数据 定义与背景 维基百科:无法用常规软件工具处理的数据集合 《大数据时代》:采用所有数据(非抽样)进行分析 Gartner:需新处理模式的海量、高增长率、多样化信息资产 背景: 数据量迅猛增长(如2001年全年流量在2013年仅需一天) 数据可挖掘的高价值(社会需求驱动精细化管理) 特点(4V) Volume:规模大,资源消耗高 Velocity:产生速度快,实时性要求高 Variety:来源与形式多样 Value:价值密度低但总量大 1.2 哪里有大数据 来源: 互联网(社交网络、日志、富媒体) 事业单位/政府(医疗影像、电网信息) 大型设备(波音787飞行数据、…
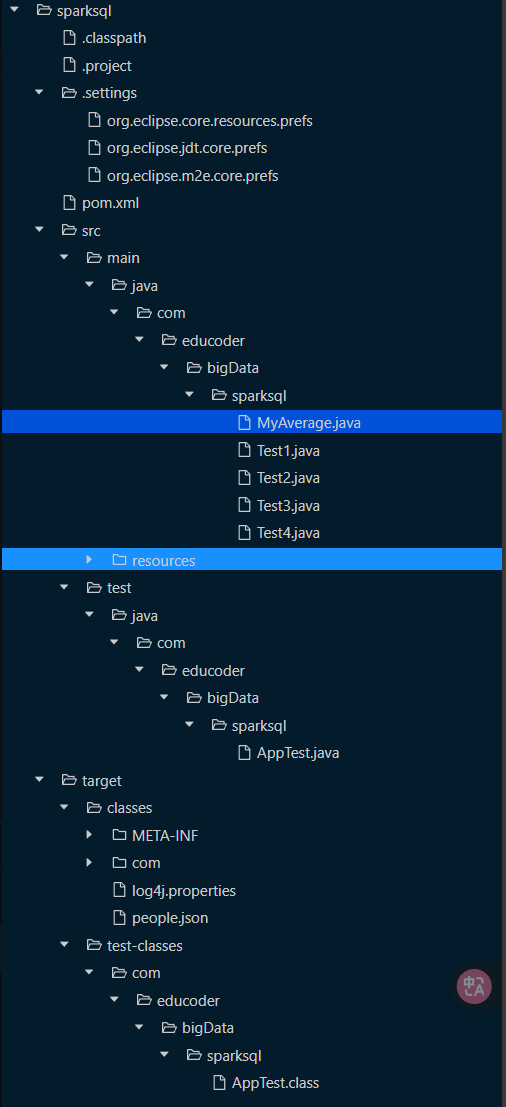
CQU大数据计算 第四次实验 SparkSQL结构化数据分析与处理/Spark 结构化流处理
1 SparkSQL结构化数据分析与处理 1.1 SparkSQL简单使用 1.1.1 第1关:SparkSQL初识 sparksql/src/main/java/com/educoder/bigData/sparksql/Test1.java package com.educoder.bigData.sparksql; import org.apache.spark.sql.AnalysisException; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spa…

大数据计算 实验3 Spark Core 核心 RDD
概述:本次实验中,在搭建Spark Standalone模式分布式集群时花了大量时间,除此之外,按照教程没遇到任何问题,都能成功简单复现. Standalone 分布式集群搭建遇到的麻烦 ulimit -f 1024000 cd /home 注意到wrapdocker会出现iptable相关错误,并且尝试更新,修复模块失败(推测是禁止了外网网络连接)所以采用禁止iptable方式启动docker sudo dockerd --iptables=false > /var/log/docker.log 2>&1 & 加载镜像 docker load -i hbase-ssh2_v1…

云计算实验2 -重庆天气数据爬取与空气质量预测系统实验报告
重庆2022-2024年天气数据分析实验报告 一、实验目的 1.1 技术目标 掌握使用Python进行网络爬虫的技术,从指定网站爬取重庆2022-2024年的天气数据。 学习数据预处理方法,包括处理缺失值、标准化数值特征和编码分类变量。 应用机器学习算法(逻辑回归、随机森林、支持向量机)进行空气质量分类预测。 熟悉模型评估方法,生成混淆矩阵、ROC曲线,并分析模型性能。 1.2 实践目标 提升数据分析能力,整合爬虫、预处理和机器学习的全流程。 通过可视化工具(混淆矩阵、ROC曲线)直观展示模型效果。 总结实验中的问题并提出改进方案,培养解决实际问题的能力。 二、实验要求 2.1 数据采集 从t…
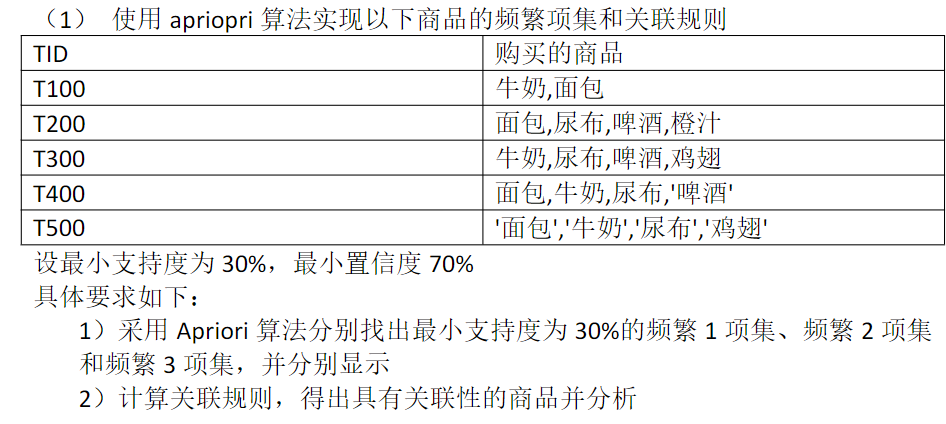
大数据技术计算实验一 (关联分析)
CQU DataMining复习 基于ppt
1 实验目的 理解 Apriori 和 FP-growth 算法的基本原理学会用 python 实现 Apriori 算法进行关联分析学会用 python 实现 FP-growth 算法进行关联分析 手写/调库 实现Apriori/FP-growth 算法 在给定置信度,支持度,数据的情况下计算频繁项集,关联规则 2 开发环境 编程软件:anconda/spyder/pycharm环境:python3.6 以上、numpy、pandas、sklearn、Jupyter Notebook 等 3 实验内容及代码 3.1 Apriori 算法 3.1.1 手写 """ Apriori算法纯Pyth…
1 数据 1. 数据概述 1.1 数据的概念:定义、分类(定性/定量、静态/动态、在线/离线等)P3P4 1.2 数据的分类:根据性质、时间、网络、位置、来源、范围、格式等进行分类P4 2. 数据内容 2.1 实时数据与历史数据:定义、特点、应用P5 2.2 时态数据与事务数据:定义、特点、区别P6P7 2.3 图形数据与图像数据:定义、特点、应用P8P9 2.4 主题数据与全部数据:定义、区别P10 2.5 空间数据:定义、分类(矢量/栅格)P11 2.6 序列数据和数据流:定义、特点P12 2.7 元数据和数据字典:定义、作用P13 3. 数据属性及数据集 3.1 数据属性:定义、分类(标…
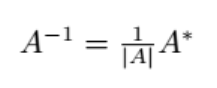
多元统计分析二轮复习 基于ppt
主成分分析 聚类分析 判别分析 H0 多元正态总体的统计推断 T方检验 1 矩阵代数 1.1定义 1.2矩阵运算 1.3行列式 1.4矩阵的逆 矩阵可逆便 行列式不为0 行列式不为0的矩阵叫非奇异矩阵 行列式为0的矩阵叫奇异矩阵 同时不可逆 用化最简行阶梯形也可以做 1.5矩阵的秩 1.6特征值,特征向量,矩阵的迹(这三个概念只有方阵才谈 矩阵的迹 1.7正定矩阵和非负定矩阵 顺序主子式 从矩阵左上角开始,按顺序取1阶、2阶...n阶的行列式 k阶顺序主子式是指:取矩阵左上角的k×k个元素构成的行列式 有趣的性质 主对角线的元素的绝对值 一定比该行 该列 所有其余元素绝对值之和还要大 第一章例…
搜索引擎(vue3+springboot3.4.1+Solr9.7.0+MySQL8.3.0);
数据挖掘DataMining
https://github.com/mozhongzhou/vue-springboot-solr 写于2024-12-29 架构 前端vue3 后端springboot3.4.1 搜索引擎以及分词系统Solr9.7.0 原始数据库MySQL8.3.0 环境(环境变量等问题不解释) Solr9.7.0 MySQL8.3.0 Maven3.9.9 maven源该改就改,不然很慢 Java 操作系统为Windows11家庭版 配置MySQL(导入测试数据) 按理说生产环节这是最后的步骤,本次放在第一步 利用navicat先建表,然后导入sql,本次测试用sql十分复杂.建议测试时选取简单的数据 …
数据挖掘(Data Mining)主要讲述了以下内容: 数据预处理:包括数据清洗、数据集成、数据变换和数据归约等步骤,以确保数据质量和一致性。 模式发现:通过算法和技术从数据中提取有用的模式和知识,如关联规则、频繁模式、序列模式等。 分类和预测:使用分类算法(如决策树、支持向量机、神经网络等)对数据进行分类,并使用回归分析等方法进行预测。 聚类分析:将数据分组,使得同一组内的数据对象相似度高,不同组间的对象相似度低。常用算法有K-means、层次聚类等。 异常检测:识别数据中的异常或异常模式,这在欺诈检测、网络安全等领域非常重要。 数据可视化:通过图形和图表展示数据和挖掘结果,帮助理解和解释数…

多元统计分析
一些废话 涉及线代 矩阵 概率论 多元随机变量 数字特征 期望 相关系数 推荐书目 应用多元统计分析 --王学民 数据统计分析 统计学习方法 李航 1 矩阵代数(基础) 1.1 定义 1.2 矩阵的运算 1.3 行列式 1.4 矩阵的逆 1.5 矩阵的秩 1.6 特征值、特征向量、矩阵的迹 1.7 正定矩阵和非负定矩阵 1.8 特征值的极值问题 2 随机向量 多元分布 数字特征 欧氏距离、马氏距离 随机向量的变换 特征函数 3 多元正态分布 3.1 定义 3.2 性质 3.3 极大似然估计以及估计量的性质 3.4 复相关系数和偏相关系数 3.5 $\overline{x}$和 (n-1)S 的…