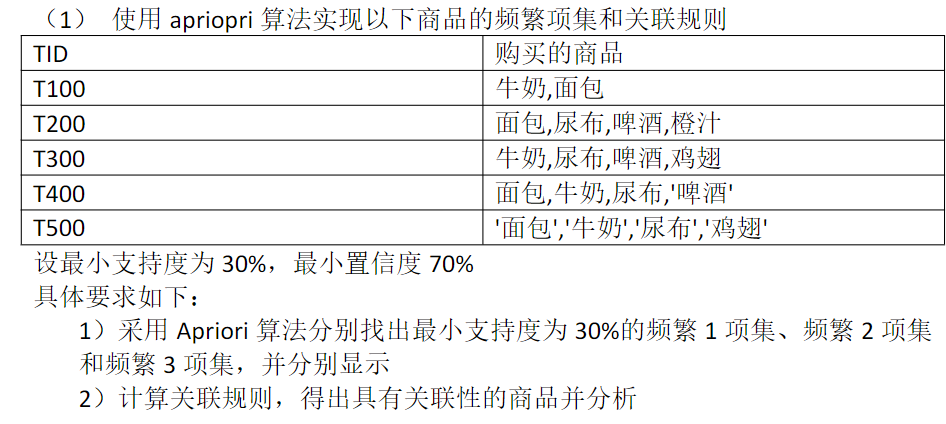
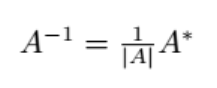1 SparkSQL结构化数据分析与处理
1.1 SparkSQL简单使用
1.1.1 第1关:SparkSQL初识
sparksql/src/main/java/com/educoder/bigData/sparksql/Test1.java
package com.educoder.bigData.sparksql;
import org.apache.spark.sql.AnalysisException;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class Test1 {
public static void main(String[] args) throws AnalysisException {
/********* Begin *********/
SparkSession spark = SparkSession
.builder()
.appName("Java Spark SQL基本示例")
.master("local")
.config("spark.some.config.option" , "some-value")
.getOrCreate();
//打印spark版本号
System.out.println(spark.version());
/********* End *********/
}
}
1.1.2 第2关:Dataset创建及使用

sparksql/src/main/java/com/educoder/bigData/sparksql/Test2.java
package com.educoder.bigData.sparksql;
import org.apache.spark.sql.AnalysisException;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import static org.apache.spark.sql.functions.col;
public class Test2 {
public static void main(String[] args) throws AnalysisException {
SparkSession spark = SparkSession
.builder()
.appName("test1")
.master("local")
.config("spark.some.config.option" , "some-value")
.getOrCreate();
/********* Begin *********/
// 读取people.json文件创建Dataset
Dataset<Row> df = spark.read().json("people.json");
// 过滤age为23的数据
Dataset<Row> filteredDF = df.filter(col("age").notEqual(23));
// 显示前20行结果
filteredDF.show();
/********* End *********/
}
}
1.1.3 第3关:Dataset自定义函数
sparksql/src/main/java/com/educoder/bigData/sparksql/MyAverage.java
package com.educoder.bigData.sparksql;
import java.util.ArrayList;
import java.util.List;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.expressions.MutableAggregationBuffer;
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction;
import org.apache.spark.sql.types.DataType;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
public class MyAverage extends UserDefinedAggregateFunction {
private static final long serialVersionUID = 1L;
private StructType inputSchema;
private StructType bufferSchema;
public MyAverage() {
/********* Begin *********/
// 定义输入参数的数据类型
List<StructField> inputFields = new ArrayList<>();
inputFields.add(DataTypes.createStructField("inputColumn", DataTypes.LongType, true));
inputSchema = DataTypes.createStructType(inputFields);
// 定义聚合缓冲区的数据类型
List<StructField> bufferFields = new ArrayList<>();
bufferFields.add(DataTypes.createStructField("sum", DataTypes.LongType, true));
bufferFields.add(DataTypes.createStructField("count", DataTypes.LongType, true));
bufferSchema = DataTypes.createStructType(bufferFields);
/********* End *********/
}
@Override
public StructType bufferSchema() {
/********* Begin *********/
return bufferSchema;
/********* End *********/
}
@Override
public DataType dataType() {
/********* Begin *********/
return DataTypes.DoubleType;
/********* End *********/
}
@Override
public boolean deterministic() {
return true;
}
@Override
public Object evaluate(Row buffer) {
/********* Begin *********/
if (buffer.getLong(1) == 0) {
return null;
}
return ((double) buffer.getLong(0)) / buffer.getLong(1);
/********* End *********/
}
@Override
public void initialize(MutableAggregationBuffer buffer) {
/********* Begin *********/
buffer.update(0, 0L); // 初始化sum为0
buffer.update(1, 0L); // 初始化count为0
/********* End *********/
}
@Override
public StructType inputSchema() {
/********* Begin *********/
return inputSchema;
/********* End *********/
}
@Override
public void merge(MutableAggregationBuffer buffer1, Row buffer2) {
/********* Begin *********/
long mergedSum = buffer1.getLong(0) + buffer2.getLong(0);
long mergedCount = buffer1.getLong(1) + buffer2.getLong(1);
buffer1.update(0, mergedSum);
buffer1.update(1, mergedCount);
/********* End *********/
}
@Override
public void update(MutableAggregationBuffer buffer, Row input) {
/********* Begin *********/
if (!input.isNullAt(0)) {
long updatedSum = buffer.getLong(0) + input.getLong(0);
long updatedCount = buffer.getLong(1) + 1;
buffer.update(0, updatedSum);
buffer.update(1, updatedCount);
}
/********* End *********/
}
}1.2 SparkSQL数据源
1.2.1 第1关:SparkSQL加载和保存
sparksql/src/main/java/com/educoder/bigData/sparksql2/Test1.java
package com.educoder.bigData.sparksql2;
import org.apache.spark.sql.AnalysisException;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
public class Test1 {
public static void main(String[] args) throws AnalysisException {
SparkSession spark = SparkSession
.builder()
.appName("test1")
.master("local")
.getOrCreate();
/********* Begin *********/
// 1. 加载people.json文件并以覆盖方式保存到people路径
Dataset<Row> peopleDF = spark.read().json("people.json");
peopleDF.write().mode(SaveMode.Overwrite).save("people");
// 2. 加载people1.json文件并以附加方式保存到people路径
Dataset<Row> people1DF = spark.read().json("people1.json");
people1DF.write().mode(SaveMode.Append).save("people");
// 3. 读取people路径中的数据并显示前20行
Dataset<Row> combinedDF = spark.read().load("people");
combinedDF.show();
/********* End *********/
}
}1.2.2 第2关:Parquet文件介绍
sparksql/src/main/java/com/educoder/bigData/sparksql2/Test2.java
package com.educoder.bigData.sparksql2;
import org.apache.spark.sql.AnalysisException;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.SaveMode;
public class Test2 {
public static void main(String[] args) throws AnalysisException {
SparkSession spark = SparkSession
.builder()
.appName("test1")
.master("local")
.getOrCreate();
/********* Begin *********/
// 1. 读取people.json并保存到id=1分区
Dataset<Row> peopleDF = spark.read().json("people.json");
peopleDF.withColumn("id", org.apache.spark.sql.functions.lit(1))
.write()
.mode(SaveMode.Overwrite)
.partitionBy("id")
.save("people");
// 2. 读取people1.json并保存到id=2分区
Dataset<Row> people1DF = spark.read().json("people1.json");
people1DF.withColumn("id", org.apache.spark.sql.functions.lit(2))
.write()
.mode(SaveMode.Append)
.partitionBy("id")
.save("people");
// 3. 读取合并后的分区数据并显示
Dataset<Row> mergedDF = spark.read().load("people");
mergedDF.show();
/********* End *********/
}
}1.2.3 第3关:json文件介绍
sparksql/src/main/java/com/educoder/bigData/sparksql2/Test3.java
package com.educoder.bigData.sparksql2;
import org.apache.spark.sql.AnalysisException;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class Test3 {
public static void main(String[] args) throws AnalysisException {
SparkSession spark = SparkSession
.builder()
.appName("test1")
.master("local")
.getOrCreate();
/********* Begin *********/
// 1. 读取people.json文件
Dataset<Row> peopleDF = spark.read().json("people.json");
// 2. 读取people1.json文件
Dataset<Row> people1DF = spark.read().json("people1.json");
// 3. 合并两个Dataset
Dataset<Row> combinedDF = peopleDF.union(people1DF);
// 4. 创建临时视图以便使用SQL查询
combinedDF.createOrReplaceTempView("people");
// 5. 计算平均薪水并显示结果
Dataset<Row> avgSalaryDF = spark.sql("SELECT AVG(CAST(salary AS DOUBLE)) FROM people");
avgSalaryDF.show();
/********* End *********/
}
}1.2.4 第4关:JDBC读取数据源
sparksql/src/main/java/com/educoder/bigData/sparksql2/Test4.java
package com.educoder.bigData.sparksql2;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
import java.util.Properties;
public class Test4 {
public static void case4(SparkSession spark) {
/********* Begin *********/
// 1. 读取people.json文件
Dataset<Row> peopleDF = spark.read().json("people.json");
// 2. 读取people1.json文件
Dataset<Row> people1DF = spark.read().json("people1.json");
// 3. 合并两个Dataset
Dataset<Row> combinedDF = peopleDF.union(people1DF);
// 4. 配置MySQL连接属性
Properties connectionProperties = new Properties();
connectionProperties.put("user", "root");
connectionProperties.put("password", "123123");
connectionProperties.put("driver", "com.mysql.jdbc.Driver");
// 5. 将数据保存到MySQL的people表中
combinedDF.write()
.mode(SaveMode.Overwrite)
.jdbc("jdbc:mysql://localhost:3306/test", "people", connectionProperties);
// 6. 从MySQL的people表中读取数据
Dataset<Row> jdbcDF = spark.read()
.jdbc("jdbc:mysql://localhost:3306/test", "people", connectionProperties);
// 7. 显示前20行数据
jdbcDF.show();
/********* End *********/
}
}2 Spark 结构化流处理
2.1 SparkStreaming
2.1.1 第1关:QueueStream
App/src/main/java/net/educoder/Step1.java
package net.educoder;
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.api.java.JavaRDD;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.LinkedBlockingQueue;
public class Step1 {
private static SparkConf conf;
static {
conf = new SparkConf().setMaster("local[*]").setAppName("Step1");
conf.set("spark.streaming.stopGracefullyOnShutdown", "true");
}
public static void main(String[] args) throws InterruptedException {
/********** Begin ***********/
//1.初始化JavaStreamingContext并设置处理批次的时间间隔,Durations.seconds(1) --> 1秒一个批次
JavaStreamingContext ssc = new JavaStreamingContext(conf, Durations.seconds(1));
//2.获取QueueStream流
LinkedBlockingQueue<JavaRDD<String>> queue = QueueStream.queueStream(ssc);
JavaDStream<String> lines = ssc.queueStream(queue);
//3.获取队列流中的数据,进行清洗、转换(按照上面的需求)
JavaDStream<String> processedData = lines.map(line -> {
// 按逗号分割,但需要注意单引号内的内容
String[] parts = line.split(",");
// 解析各字段
String ip = parts[0];
long timestamp = Long.parseLong(parts[1]);
// 处理URL部分(去除单引号)
String urlInfo = parts[2].replace("'", "");
// 目标URL和状态码
String targetUrl = parts[3];
String statusCode = parts[4];
// 1. 将时间戳转换成规定格式
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String formattedDate = sdf.format(new Date(timestamp));
// 2. 提取起始URL(按空格分割)
String startUrl = urlInfo.split(" ")[1];
// 3. 拼接结果数据
return "Ip:" + ip + ",visitTime:" + formattedDate +
",startUrl:" + startUrl + ",targetUrl:" + targetUrl +
",statusCode:" + statusCode;
});
//4.判断rdd是否为空,如果为空,调用ssc.stop(false, false)与sys.exit(0)两个方法,反之将结果数据存储到mysql数据库中
processedData.foreachRDD(rdd -> {
if (rdd.isEmpty()) {
ssc.stop(false, false);
System.exit(0);
} else {
JdbcTools.saveData(rdd.toLocalIterator());
}
});
//5.启动SparkStreaming
ssc.start();
//6.等待计算结束
ssc.awaitTermination();
/********** End **********/
}
}2.1.2 第2关:File Streams
Spark/src/main/java/SparkStreaming.java
package com.educoder;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.io.Serializable;
import java.sql.*;
import java.util.Arrays;
import java.util.Iterator;
public class SparkStreaming {
public static void main(String[] args) throws Exception {
SparkConf conf=new SparkConf().setAppName("edu").setMaster("local");
/********** Begin **********/
//1.初始化StreamingContext,设置时间间隔为1s
JavaStreamingContext ssc = new JavaStreamingContext(conf, Durations.seconds(1));
//2.设置文件流,监控目录/root/step11_fils
JavaDStream<String> lines = ssc.textFileStream("/root/step11_fils");
/* *数据格式如下:hadoop hadoop spark spark
*切割符为空格
*需求:
*累加各个批次单词出现的次数
*将结果导入Mysql
*判断MySQL表中是否存在即将要插入的单词,不存在就直接插入,存在则把先前出现的次数与本次出现的次数相加后插入
*库名用educoder,表名用step,单词字段名用word,出现次数字段用count
*/
//3.对数据进行清洗转换
JavaDStream<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
JavaPairDStream<String, Integer> wordcount = words.mapToPair(word -> new Tuple2<>(word, 1))
.reduceByKey((a, b) -> a + b);
//4.将结果导入MySQL
wordcount.foreachRDD(rdd->{
rdd.foreachPartition(new VoidFunction<Iterator<Tuple2<String, Integer>>>() {
@Override
public void call(Iterator<Tuple2<String, Integer>> iterator) throws Exception {
Connection connection = myconn();
Statement stmt = connection.createStatement();
// Create table if not exists
stmt.execute("CREATE TABLE IF NOT EXISTS educoder.step (word VARCHAR(255) PRIMARY KEY, count INT)");
while (iterator.hasNext()) {
Tuple2<String, Integer> record = iterator.next();
String word = record._1();
int count = record._2();
// Check if word exists
ResultSet rs = stmt.executeQuery("SELECT count FROM educoder.step WHERE word = '" + word + "'");
if (rs.next()) {
// Update existing record
int existingCount = rs.getInt("count");
stmt.executeUpdate("UPDATE educoder.step SET count = " + (existingCount + count) +
" WHERE word = '" + word + "'");
} else {
// Insert new record
stmt.executeUpdate("INSERT INTO educoder.step VALUES('" + word + "', " + count + ")");
}
rs.close();
}
stmt.close();
connection.close();
}
});
});
//5.启动SparkStreaming
ssc.start();
ssc.awaitTermination();
/********** End **********/
Thread.sleep(15000);
ssc.stop();
ssc.awaitTermination();
}
/**
*获取mysql连接
*@return
*/
public static Connection myconn()throws SQLException,Exception{
Class.forName("com.mysql.jdbc.Driver");
Connection conn= DriverManager.getConnection("jdbc:mysql://localhost:3306/educoder","root","123123");
return conn;
}
}2.1.3 第3关:socketTextStream
SparkStreaming/src/main/java/JSocketSpark.java
package com;
import java.util.Arrays;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.sql.Connection;
import java.sql.DriverManager;
public class JSocketSpark {
public static void main(String[] args) throws InterruptedException{
SparkConf conf = new SparkConf().setAppName("socketSparkStreaming").setMaster("local[*]");
conf.set("spark.streaming.stopGracefullyOnShutdown", "true");
JavaStreamingContext ssc = new JavaStreamingContext(conf, Durations.seconds(2));
/**********begin**********/
//1.连接socket流 主机名:localhost 端口:5566
JavaReceiverInputDStream<String> lines = ssc.socketTextStream("localhost", 5566);
//2.切分压平
JavaDStream<String> words = lines.flatMap(line -> {
String cleanedLine = line.toLowerCase().replaceAll("[^a-zA-Z\\s]", "");
return Arrays.stream(cleanedLine.split("\\s+"))
.filter(word -> !word.isEmpty())
.iterator();
});
//3.组装
JavaPairDStream<String, Integer> pairs = words.mapToPair(word -> new Tuple2<>(word, 1));
//4.设置检查点
ssc.checkpoint("/root/check");
//5.每个时间窗口内得到的统计值都累加到上个时间窗口得到的值,将返回结果命名为reduced
Function2<List<Integer>, Optional<Integer>, Optional<Integer>> updateFunc =
(values, state) -> {
int currentSum = values.stream().mapToInt(Integer::intValue).sum();
int previousSum = state.orElse(0);
return Optional.of(currentSum + previousSum);
};
JavaPairDStream<String, Integer> reduced = pairs.updateStateByKey(updateFunc);
//6.将结果写入MySQL
// 语法:如果存在这个单词就更新它所对应的次数
// 如果不存在将其添加
reduced.foreachRDD(rdd -> {
rdd.foreachPartition(partition -> {
Connection conn = null;
try {
conn = myconn();
conn.setAutoCommit(false); // Use transactions
String sql = "INSERT INTO wordcount (word, wordcount) VALUES (?, ?) " +
"ON DUPLICATE KEY UPDATE wordcount = VALUES(wordcount)";
try (java.sql.PreparedStatement pstmt = conn.prepareStatement(sql)) {
while (partition.hasNext()) {
Tuple2<String, Integer> tuple = partition.next();
pstmt.setString(1, tuple._1());
pstmt.setInt(2, tuple._2());
pstmt.addBatch();
}
pstmt.executeBatch();
conn.commit();
}
} catch (Exception e) {
if (conn != null) {
try {
conn.rollback();
} catch (Exception re) {
// Suppress rollback errors
}
}
} finally {
if (conn != null) {
try {
conn.close();
} catch (Exception e) {
// Suppress close errors
}
}
}
});
});
/********** End **********/
ssc.start();
ssc.awaitTermination();
}
public static Connection myconn()throws Exception{
Class.forName("com.mysql.jdbc.Driver");
Connection conn= DriverManager.getConnection("jdbc:mysql://localhost:3306/edu","root","123123");
return conn;
}
}2.1.4 第4关:KafkaStreaming
App/src/main/java/net/educoder/Step2.java
package net.educoder;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import java.text.SimpleDateFormat;
import java.util.*;
public class Step2 {
private static SparkConf conf;
static {
conf = new SparkConf().setMaster("local[*]").setAppName("Step2");
conf.set("spark.streaming.stopGracefullyOnShutdown", "true");
}
public static void main(String[] args) throws InterruptedException {
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "127.0.0.1:9092");
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("group.id", "sparkStreaming");
kafkaParams.put("enable.auto.commit", "false");
TopicPartition topicPartition = new TopicPartition("test", 0);
List<TopicPartition> topicPartitions = Arrays.asList(topicPartition);
HashMap<TopicPartition, Long> offsets = new HashMap<>();
offsets.put(topicPartition, 0l);
/********** Begin **********/
// 初始化JavaStreamingContext
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
// 创建Kafka Direct Stream
JavaInputDStream<ConsumerRecord<String, String>> directStream = KafkaUtils.createDirectStream(
jssc,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String>Assign(topicPartitions, kafkaParams, offsets)
);
// 数据转换
JavaDStream<String> processed = directStream.map(record -> {
String line = record.value();
String[] parts = line.split(",");
String ip = parts[0].trim();
long timestamp = Long.parseLong(parts[1].trim());
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String visitTime = sdf.format(new Date(timestamp));
String thirdField = parts[2].replaceAll("'", "").trim();
String[] urlParts = thirdField.split("\\s+");
String startUrl = urlParts.length >= 2 ? urlParts[1] : "";
String targetUrl = parts[3].trim();
String statusCode = parts[4].trim();
return String.format("Ip:%s,visitTime:%s,startUrl:%s,targetUrl:%s,statusCode:%s",
ip, visitTime, startUrl, targetUrl, statusCode);
});
// 处理RDD
processed.foreachRDD(rdd -> {
if (rdd.isEmpty()) {
jssc.stop(false, false);
System.exit(0);
} else {
rdd.foreachPartition(partition -> {
JdbcTools.saveData2(partition);
});
}
});
// 启动并等待
jssc.start();
jssc.awaitTermination();
/********** End **********/
}
}
难点解决方案
在2.1.3 2.1.4这两个问题花了大量时间
OJ平台难免遇到奇怪的问题,要想顺利完整理解并实现要求,需要看明白程序执行方式
例如 SparkStreaming
1.sh
#!/bin/bash
cd SparkStreaming
mysql -uroot -p123123 -e'DROP database IF EXISTS `edu`'
mysql -uroot -p123123 < wordcount.sql
rm -rf /root/files
rm -rf /root/SparkStreaming-1.0-SNAPSHOT.jar
rm -rf /root/socket.jar
rm -rf /root/check
mkdir /root/check
mvn clean package -o >/dev/null 2>&1
cp target/SparkStreaming-1.0-SNAPSHOT.jar /root
cp ./socket.jar /root
mkdir /root/files
cp files/wordcount.txt /root/files/
nohup java -jar /root/socket.jar >/dev/null 2>&1 &
sleep 3s
nohup /opt/spark/dist/bin/spark-submit --class com.JSocketSpark /root/SparkStreaming-1.0-SNAPSHOT.jar >/dev/null 2>&1 &
sleep 15s
mysql -uroot -p123123 -e'select * from edu.wordcount order by wordcount desc' | sed -n '2,6p'
ps -ef | grep SparkSubmit | grep -v grep | awk '{print $2}' | xargs kill -9 >/dev/null 2>&1
可以通过脚本推测文件和参数 基于此进行开发