统计语言模型,神经网络模型, 预训练模型
1 绪论(了解)
自然语言处理(NLP)的定义是什么?
- 自然语言处理(Natural Language Processing,NLP)是人工智能领域的一个重要分支,专注于通过计算机技术实现人类自然语言的理解、解析、生成和交互。其核心目标是使计算机能够像人类一样处理语言数据,从而支持机器翻译、情感分析、文本摘要、问答系统等实际应用。
NLP发展的四个阶段:
- 初创期
- 理性主义时代
- 经验主义时代
- 深度学习时代
1. 初创期(1950s-1970s)
- 特点:基于规则和符号逻辑,依赖语言学理论。
- 技术:手工编写语法规则(如上下文无关文法)、词典和语义模板。
- 局限:规则覆盖范围有限,难以处理复杂语言现象(如歧义、隐喻)。
- 代表成果:机器翻译(如Georgetown-IBM实验)、ELIZA聊天机器人。
2. 理性主义时代(1980s-1990s)
- 特点:引入统计方法和概率模型,但仍结合语言学知识。
- 技术:隐马尔可夫模型(HMM)、上下文无关文法增强版、词汇化语法。
- 突破:统计机器翻译(如IBM Model系列)、词性标注和句法分析取得进展。
- 局限:依赖专家设计的特征工程,数据稀疏问题突出。
3. 经验主义时代(1990s-2010s)
- 特点:数据驱动,统计学习主导,弱化人工规则。
- 技术:支持向量机(SVM)、最大熵模型、条件随机场(CRF),以及基于大规模语料库的统计方法。
- 突破:搜索引擎、垃圾邮件过滤、浅层语义分析(如情感分类)。
- 关键转变:从“规则编码”转向“从数据中学习”,但特征仍需人工设计。
4. 深度学习时代(2010s至今)
- 特点:端到端学习,自动提取特征,模型复杂度显著提升。
- 技术:神经网络(RNN、LSTM)、注意力机制、Transformer(如BERT、GPT)、预训练-微调范式。
- 突破:机器翻译(如Google Neural MT)、文本生成、问答系统,模型参数量达万亿级(如GPT-3)。
- 挑战:计算资源需求高、可解释性差、伦理与偏见问题。
总结
NLP的发展从规则驱动到数据驱动,再到表示学习驱动,体现了从“人工设计”到“自动学习”的范式迁移。未来可能向多模态、低资源、可解释性等方向演进。
NLP的基本问题:
- 形态学
- 语法学syntax
- 语义学Semantics
- 语音学Phonetics
- 语用学Pragmatics

NLP面临的困难
- 歧义现象:结构歧义 词义歧义 语音歧义 词语切分歧义 指代歧义和省略歧义 语用歧义
- 未知的语音现象:新词汇 新含义 新用法 新句型等层出不穷
自然语言处理(NLP)面临的核心困难可归纳为两大类:语言本身的复杂性和动态变化的挑战。以下是具体分析:
一、歧义现象(Ambiguity)
语言歧义贯穿所有层面,是NLP的最大障碍之一:
- 结构歧义
- 同一句子可能有多种语法解析(如“Flying planes can be dangerous”可理解为“驾驶飞机危险”或“飞行的飞机危险”)。
- 词义歧义
- 多义词依赖上下文消歧(如“苹果”指水果还是公司?)。
- 语音歧义
- 同音词(如“to/two/too”)或口音差异导致语音识别错误。
- 词语切分歧义
- 无空格语言(如中文)的分词难题(如“美国会”可切分为“美/国会”或“美国/会”)。
- 指代歧义与省略
- 代词(如“他”“它”)指代不明,或省略主语(如“看完电影了,[我]觉得不错”)。
- 语用歧义
- 隐含意图或讽刺(如“这主意真棒”可能是褒义或反讽)。
影响:模型需结合上下文、常识和世界知识才能准确理解,但当前系统仍易被歧义误导。
二、未知语言现象(Dynamic Language)
语言是动态演变的,NLP需持续适应:
- 新词汇
- 网络用语(如“绝绝子”)、专业术语、外来词(如“元宇宙/Metaverse”)不断涌现。
- 新含义与新用法
- 旧词新义(如“下头”从动作变为形容失望),或语法变异(如“很男权”)。
- 新句型与表达
- 新兴句式(如“栓Q”表感谢)、缩写(如“yyds”)、混合语言(如“笑skr人”)。
挑战:
- 传统静态语料库和词典难以覆盖新现象。
- 预训练模型(如GPT-4)虽能部分捕捉新词,但依赖实时数据更新,且可能生成错误内容。
三、其他关键挑战
- 数据偏差:训练数据中的文化、性别等偏见会被模型放大。
- 资源稀缺:小语种或领域专用数据不足。
- 常识与推理:语言隐含的常识(如“人用脚走路”)难以系统化建模。
总结:NLP的困难本质是语言的非确定性与人类认知的复杂性的结合。尽管深度学习提升了泛化能力,但彻底解决这些问题仍需突破多模态理解、动态适应和因果推理等方向。
2 数据基础
2.1 概率论基础
条件概率 全概率 贝叶斯 激活函数 最大似然估计 梯度下降
以下是自然语言处理(NLP)和机器学习中几个核心概念的简要说明:
1. 条件概率(Conditional Probability)
定义:事件A在事件B已发生条件下的概率,记为 $P(A|B)$。
公式:
$$ P(A|B) = \frac{P(A \cap B)}{P(B)} \quad (P(B) \neq 0) $$
应用:NLP中的语言模型(如n-gram)、词性标注(根据上下文推测词性)。
2. 全概率公式(Law of Total Probability)
定义:若事件 $B_1, B_2, \dots, B_n$ 互斥且完备(覆盖所有可能),则:
$$ P(A) = \sum_{i=1}^n P(A|B_i)P(B_i) $$
应用:复杂事件的概率分解(如分类任务中计算边缘概率)。
3. 贝叶斯定理(Bayes’ Theorem)
定义:基于条件概率的反向推理:
$$ P(B|A) = \frac{P(A|B)P(B)}{P(A)} $$
应用:
- 垃圾邮件分类(根据词频反推邮件类别)
- 医学诊断(从症状反推疾病概率)
4. 激活函数(Activation Function)
作用:为神经网络引入非线性,决定神经元是否激活。
常见类型:
- Sigmoid:输出范围 $(0,1)$,用于二分类(易梯度消失)
- ReLU:$\max(0,x)$,解决梯度消失,广泛用于隐藏层
- Softmax:多分类输出归一化为概率分布
应用:深度学习模型(如BERT、LSTM)的核心组件。
5. 最大似然估计(MLE)
在所有可能的参数中,选择让当前观测数据出现概率最大的那个参数
定义:通过最大化似然函数 $\mathcal{L}(\theta | X)$ 估计参数 $\theta$(假设数据i.i.d.):
$$ \hat{\theta} = \arg\max_\theta P(X|\theta) $$
应用:统计语言模型训练、逻辑回归参数学习。

6. 梯度下降(Gradient Descent)
目标:最小化损失函数 $J(\theta)$。
更新规则:
$$ \theta_{t+1} = \theta_t – \eta \nabla_\theta J(\theta) $$
其中 $\eta$ 为学习率。
变体:
- SGD:单样本更新,速度快但震荡
- Adam:自适应学习率,结合动量
应用:训练神经网络、优化可微模型(如Word2Vec)。
比如线性回归 要求模型参数theta 和 b
使得损失函数(均方误差)最小化 使用的办法就是梯度下降法

要找二元函数最值(通常是最小值) 为什么可以用梯度下降法? 原理是什么
同样的 对二元函数的梯度下降法可以推广到任意多维 无非是对每个要求的参数求偏导

总结
- 概率基础:条件概率、全概率、贝叶斯是统计NLP的基石
- 优化工具:MLE提供参数估计理论,梯度下降实现实际优化
- 神经网络核心:激活函数决定非线性能力,梯度下降驱动参数学习
这些概念共同支撑了从传统统计方法到现代深度学习的NLP技术演进。
2.2 信息论基础
熵 条件熵 互信息 相对熵 KL散度 交叉熵 困惑度 双字耦合度与互信息
以下是关于信息论中核心概念的详细分述,结合定义、公式、计算示例及NLP应用场景:
1. 熵(Entropy)
定义:
$$H(X) = -\sum_{x \in \mathcal{X}} p(x) \log p(x)$$
示例(公平硬币):
$$H(X) = -[0.5 \log 0.5 + 0.5 \log 0.5] = 1 \text{ bit}$$
2. 条件熵(Conditional Entropy)
定义:
$$H(X|Y) = \sum_{y \in \mathcal{Y}} p(y) H(X|Y=y) = -\sum_{x,y} p(x,y) \log p(x|y)$$
示例(天气影响外出):
$$H(X|Y) = 0.6 \cdot H(0.8) + 0.4 \cdot H(0.1) \approx 0.49 \text{ bit}$$
3. 互信息(Mutual Information, MI)
定义:
$$I(X;Y) = \sum_{x,y} p(x,y) \log \frac{p(x,y)}{p(x)p(y)} = H(X) – H(X|Y)$$
示例(词共现分析):
$$I = 0.008 \log \frac{0.008}{0.01 \times 0.02} \approx 0.263 \text{ bit}$$
4. KL散度(相对熵)
定义:
$$D_{KL}(P | Q) = \sum_{x} p(x) \log \frac{p(x)}{q(x)}$$
示例(分布差异):
$$D_{KL}(P | Q) = 0.9 \log \frac{0.9}{0.8} + 0.1 \log \frac{0.1}{0.2} \approx 0.058$$
5. 交叉熵(Cross-Entropy)
定义:
$$H(P, Q) = -\sum_{x} p(x) \log q(x) = H(P) + D_{KL}(P | Q)$$
示例(分类损失):
$$H(P, Q) = -1 \cdot \log 0.9 – 0 \cdot \log 0.1 \approx 0.105$$
6. 困惑度(Perplexity)
定义:
$$\text{PP}(Q) = 2^{H(P,Q)} = \prod_{i=1}^N \frac{1}{q(x_i)^{1/N}}$$
示例(句子概率):
$$\text{PP} = 0.01^{-1/10} \approx 1.58$$
7. 双字耦合度(Bigram MI)
定义:
$$\text{MI}(w_1, w_2) = \log \frac{p(w_1, w_2)}{p(w_1)p(w_2)}$$
示例(短语提取):
$$\text{MI} = \log \frac{0.0008}{0.001 \times 0.002} \approx 2.0$$
公式关系总结
- 交叉熵与KL散度:
$$H(P, Q) = H(P) + D_{KL}(P | Q)$$ - 互信息与熵:
$$I(X;Y) = H(X) – H(X|Y) = H(Y) – H(Y|X)$$
对比总结
| 概念 | 核心意义 | 对称性 | NLP应用场景 |
|---|---|---|---|
| 熵 | 单变量的不确定性 | – | 词表复杂度评估 |
| 条件熵 | 已知条件下的剩余不确定性 | 非对称 | 上下文相关的词性预测 |
| 互信息 | 变量间的共享信息量 | 对称 | 词对相关性分析 |
| KL散度 | 分布差异 | 非对称 | 模型评估、VAE损失 |
| 交叉熵 | 用错误分布编码真实分布的成本 | 非对称 | 分类任务损失函数 |
| 困惑度 | 模型预测不确定性的直观度量 | – | 语言模型性能比较 |
| 双字耦合度 | 相邻词的共现强度 | 对称 | 短语识别、分词 |
通过理解这些概念的联系与差异,可以更高效地设计NLP特征工程、模型评估和优化策略。
3 语料库和语言知识库
- 语料库语言学研究的内容
- 区分 “平衡语料库” 与 “平行语料库”
- 典型的语料库有哪些
语料库语言学研究内容
语料库语言学(Corpus Linguistics)是基于大规模真实文本数据(语料库)进行语言研究的学科,主要研究内容包括:
- 语言现象统计:词频、搭配、句法模式等定量分析。
- 语言变异研究:不同领域、时期、群体的语言差异(如学术vs.口语)。
- 词典编纂:基于真实用例提取词义和搭配(如COBUILD词典)。
- 自然语言处理(NLP):训练语言模型、词向量、句法分析器等。
- 语言演变分析:历时语料库中的语法或词汇变化(如Google Ngram)。
平衡语料库 vs. 平行语料库
平衡语料库是通过科学抽样方法构建的,旨在覆盖目标语言或领域中的多样性(如文体、主题、时间、地域等),避免数据偏向某一特定类型,从而保证语言模型的泛化能力。
平行语料库由双语或多语对齐的文本组成,通常以句子或段落为单位一一对应,用于机器翻译、跨语言研究等任务
| 类型 | 定义 | 特点 | 用途 |
|---|---|---|---|
| 平衡语料库 | 按比例覆盖不同文体、领域、时间等,代表语言全貌(如新闻、小说、口语等)。 | 强调多样性和代表性 | 语言整体规律研究、词典编纂 |
| 平行语料库 | 同一内容的多语言对照文本(如中英对照的联合国文件)。 | 文本对齐(句子/段落级) | 机器翻译、跨语言研究 |
示例:
- 平衡语料库:BNC(英国国家语料库)包含口语、学术、新闻等多种文体。
- 平行语料库:Europarl(欧洲议会演讲平行文本)含21种语言对齐。
典型语料库举例
1. 通用语料库(平衡性)
- BNC (British National Corpus):1亿词次,英语书面语和口语。
- COCA (Corpus of Contemporary American English):10亿词次,美国英语多领域文本。
- 现代汉语平衡语料库(中国台湾):涵盖文学、新闻、学术等。
2. 平行语料库
- Europarl:欧洲议会多语言平行文本,支持机器翻译研究。
- UN Parallel Corpus:联合国官方文件,中英法等6种语言对齐。
- OPUS:开源多语言平行语料库集合(含电影字幕、圣经等)。
3. 领域专用语料库
- PubMed:生物医学论文摘要,用于术语抽取。
- Twitter语料库:社交媒体语言分析(如情感分析)。
4. 历时语料库
- Google Books Ngram:1800-2019年书籍词频历时数据。
- CLMET (Corpus of Late Modern English Texts):1710-1920年英语演变研究。
应用场景对比
- 平衡语料库:适合研究语言普遍规律(如汉语词频统计)。
- 平行语料库:适合跨语言任务(如训练翻译模型)。
- 领域语料库:优化专业领域NLP模型(如医疗问答系统)。
语料库的选择需根据研究目标(通用性、跨语言、专业性)决定。
4 语言模型
- 统计语言模型的核心目标
- N-gram模型(n元文法模型)
- 最大似然估计Maximun Likelihood Estimation
- 加1平滑,Good-Turing平滑 GT平滑先统计r=1,2,3(出现1次,2次,3次….的bigrams有几个)然后使用公式进行求取 r->r’ 最后能得到平滑后频次.
- 统计语言模型评价指标




统计语言模型的核心目标
考点:
- 核心目标:建模自然语言的概率分布,计算词序列的联合概率(如句子概率)。
- 应用场景:机器翻译、语音识别、拼写纠错等任务中评估句子的合理性。
- 关键问题:数据稀疏性(低频词/长尾词概率估计困难)与计算效率(长序列概率分解)。
N-gram模型(n元文法模型)
考点:
- 基本假设:马尔可夫性(当前词概率仅依赖前
n-1个词)。 - 常见变体:
- Unigram(独立假设)、Bigram(一阶依赖)、Trigram(二阶依赖)。
- 优缺点:
- 优点:简单高效,易于训练。
- 缺点:长距离依赖缺失(n较小时);数据稀疏问题显著。
最大似然估计(MLE) 如果数据已经平滑 或者没有0词频问题 可以用MLE思想
考点:
- 定义:通过频率计数估计概率(如Bigram概率:
P(w_i|w_{i-1}) = \frac{\text{count}(w_{i-1},w_i)}{\text{count}(w_{i-1})})。 - 局限性:
- 未登录词(OOV)概率为0;
- 对低频词过拟合(高频词主导模型)。
平滑技术(加1平滑 & Good-Turing平滑)
考点:
- 加1平滑(Laplace):
- 方法:所有词频+1,避免零概率。
- 问题:高频词概率被过度稀释,实际效果差。

1John 2read 3Moby 4Dick 5Mary 6a 7different 8book 9She 10by 11Cher 一共11个词汇

+1 平滑 前词出现的数量+V
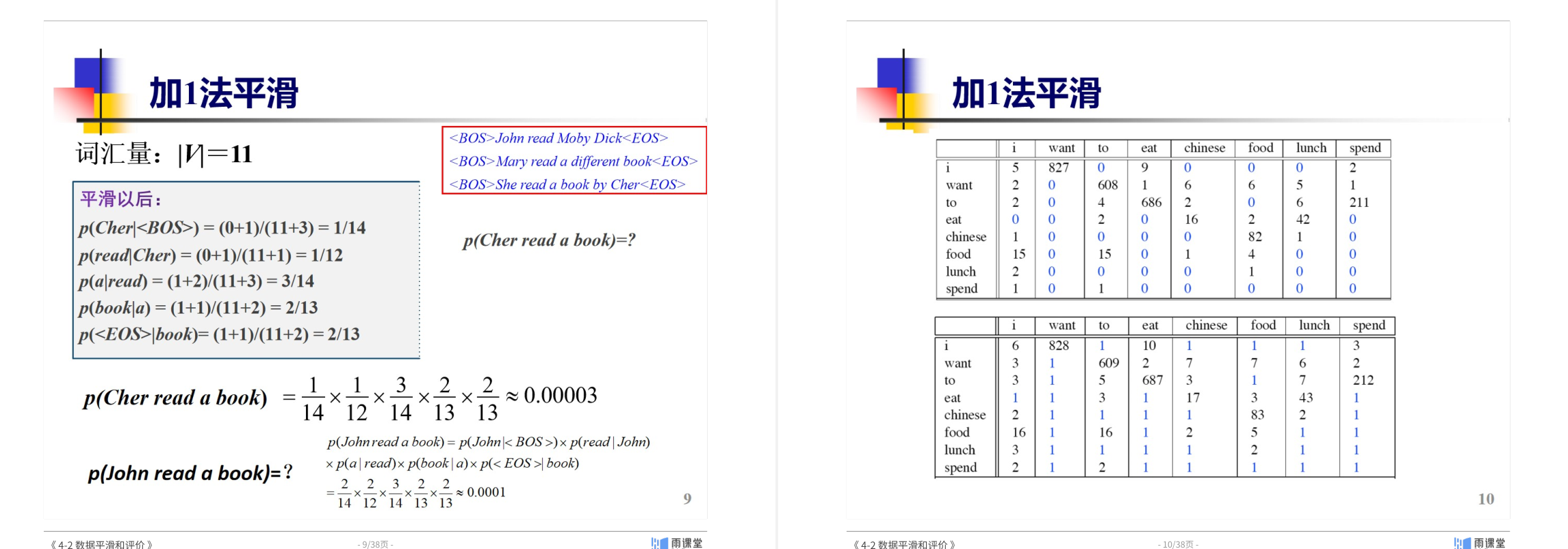
- Good-Turing平滑:
- 核心思想:用低频词的频率重新分配未登录词概率(如“出现1次的词”概率由“出现2次的词”数量估计)。
- 适用场景:处理长尾分布,常用于低资源语料。
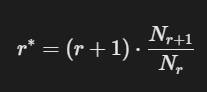

语料库中有大量句子
从数据中统计所有bigrams的频次(Nr = 出现r次的bigrams的数量)
r=0 没有这种bigram出现过 r’=(r+1)N1/N=(0+1)N1/N总
r=1代表这种组合出现过一次(明显感觉得到出现一次的频次是很高的)
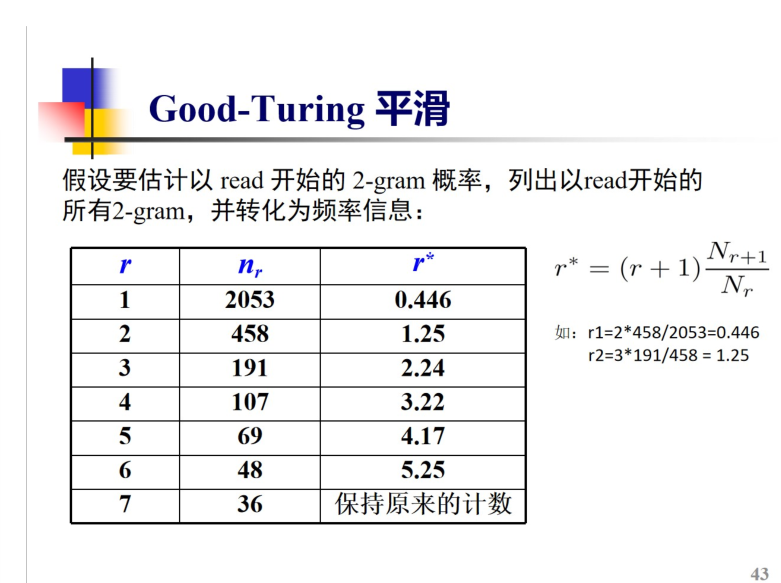
有点贝叶斯的感觉
Good-Turning原理是高频挪用适当的空间给低频词 使得低频词有相比于加一平滑更合理的词频
统计语言模型评价指标
考点:
- 困惑度(Perplexity):
- 定义:模型对测试集的平均逆概率(几何均值),值越小越好。
- 计算:$\exp\left(-\frac{1}{N}\sum_{i=1}^N \log P(w_i|w_{<i})\right)$ 取了个指数
- 其他指标:
- 交叉熵(Cross-Entropy):与困惑度等价,反映信息量。
- 任务相关指标:如拼写纠错的准确率、翻译的BLEU分数(间接评估)。


不好算


5 神经网络语言模型
- 词向量(Word2Vec):CBOW和Skip-grams
- 梯度消失和梯度爆炸
- 预训练语言模型(ELMO GPT和Bert)
- 大语言模型 LLM
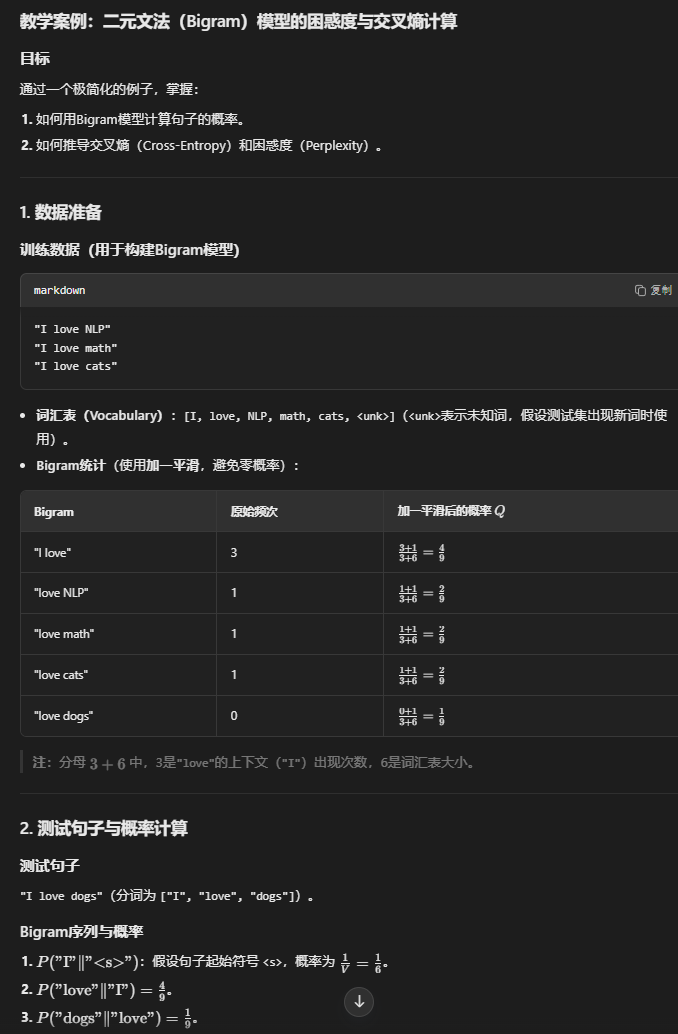
词向量(Word2Vec):CBOW 和 Skip-gram
考点:
- 核心思想:
- CBOW(Continuous Bag-of-Words):用上下文词预测当前词(适合高频词)。
- Skip-gram:用当前词预测上下文词(适合低频词)。
- 训练方式:
- 基于负采样(Negative Sampling)或层次Softmax优化计算效率。
- 优缺点:
- 优点:捕捉语义/语法相似性(如“king – man + woman ≈ queen”)。
- 缺点:无法处理多义词(静态向量);窗口大小固定,无法建模长距离依赖。
梯度消失和梯度爆炸
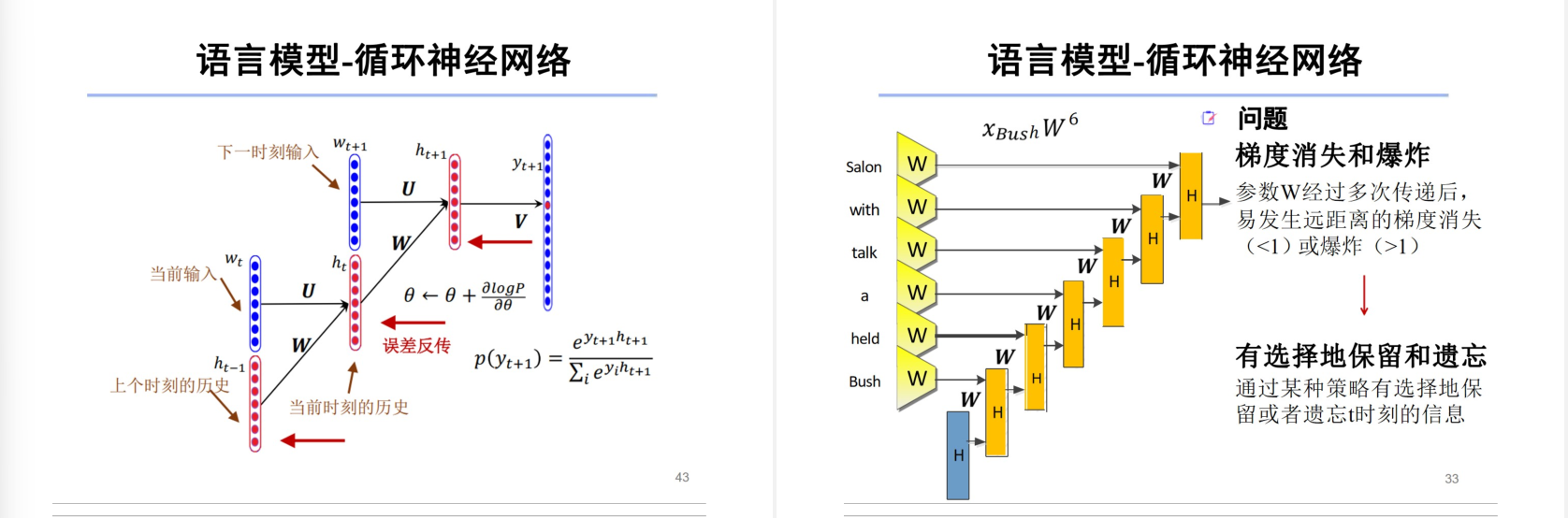
考点:
- 梯度消失:
- 原因:深层网络中,反向传播时梯度连乘(如Sigmoid/Tanh的导数<1),导致浅层参数更新缓慢。
- 影响:RNN/LSTM 难以学习长序列依赖。
梯度趋近于0 无法更新
- 梯度爆炸:
- 原因:梯度连乘过大(如ReLU激活+权重初始化不当)。
- 表现:参数剧烈震荡,模型无法收敛。
梯度太大 来回震荡 无法收敛
梯度消失(Vanishing Gradients)和梯度爆炸(Exploding Gradients)本质上是神经网络模型的固有缺陷,但人为的设计选择(如模型结构、初始化、超参数)会显著影响其严重程度
- 解决方案:
- 梯度裁剪(Gradient Clipping)。
- 改进网络结构(LSTM/GRU、残差连接)。
- 权重初始化(Xavier/He)。
预训练语言模型(ELMo、GPT、BERT)
考点:
- ELMo(2018):
- 特点:双向LSTM,生成上下文相关的词向量。
- 局限:非端到端训练,特征拼接方式低效。
- GPT(2018):
- 特点:单向Transformer(仅左上下文),生成式预训练+微调。
- 应用:文本生成、摘要等单向任务。
- BERT(2018): Bidirectional Encoder Representations from Transformers
- 特点:双向Transformer,MLM(掩码语言模型)+ NSP(下一句预测)任务。
- 优势:上下文双向建模,适用于分类/问答等任务。
- 对比:
- 单向 vs 双向:GPT生成能力强,BERT理解能力强。
- 微调方式:BERT需任务特定结构,GPT可零样本生成。
- ELMo:双向LSTM,动态词向量。
- GPT:单向Transformer,生成任务。
- BERT:双向Transformer,理解任务。
大语言模型(LLM)
考点:
- 核心特点:
- 参数量巨大(百亿至万亿级),基于Transformer架构。
- 训练方式:自监督预训练(如GPT-3的“预测下一个词”)+ 指令微调/RLHF(如ChatGPT)。
- 关键技术:
- 缩放定律(Scaling Laws):模型性能随数据/参数规模提升。
- 上下文学习(In-context Learning):少样本提示即可完成任务。
- 挑战:
- 计算成本高,存在幻觉(生成错误事实)。
- 对齐问题(Alignment):如何使模型符合人类价值观。
总结:
- Word2Vec:静态词向量基础,区分CBOW/Skip-gram目标。
- 梯度问题:理解原因及解决方案(如LSTM/Transformer的改进)。
- 预训练模型:掌握ELMo/GPT/BERT的架构差异与适用场景。
- LLM:关注规模效应、训练范式(自监督+微调)及社会影响。
简洁版回答
- Word2Vec:
- 静态词向量(一词一义),通过CBOW(上下文→目标词)和Skip-gram(目标词→上下文)学习词嵌入。
- 梯度问题:
- 原因:RNN的梯度消失/爆炸(长序列依赖)。
- 解决:LSTM/GRU(门控机制)、Transformer(自注意力+残差连接)。
- 预训练模型:
- ELMo:双向LSTM,动态词向量(上下文相关)。
- GPT:单向Transformer,生成任务(自回归)。
- BERT:双向Transformer,理解任务(MLM+NSP)。
适用场景:
- ELMo:轻量级上下文词向量。
- GPT:文本生成、续写。
- BERT:分类、问答等理解任务。
6 隐马尔可夫模型与条件随机场
- 马尔可夫模型
- 隐马尔可夫模型 (HMM的三个核心问题以及对应算法)
- 条件随机场(比较CRF 与HMM的优缺点)
- 前后向算法
- Viterbi搜索算法
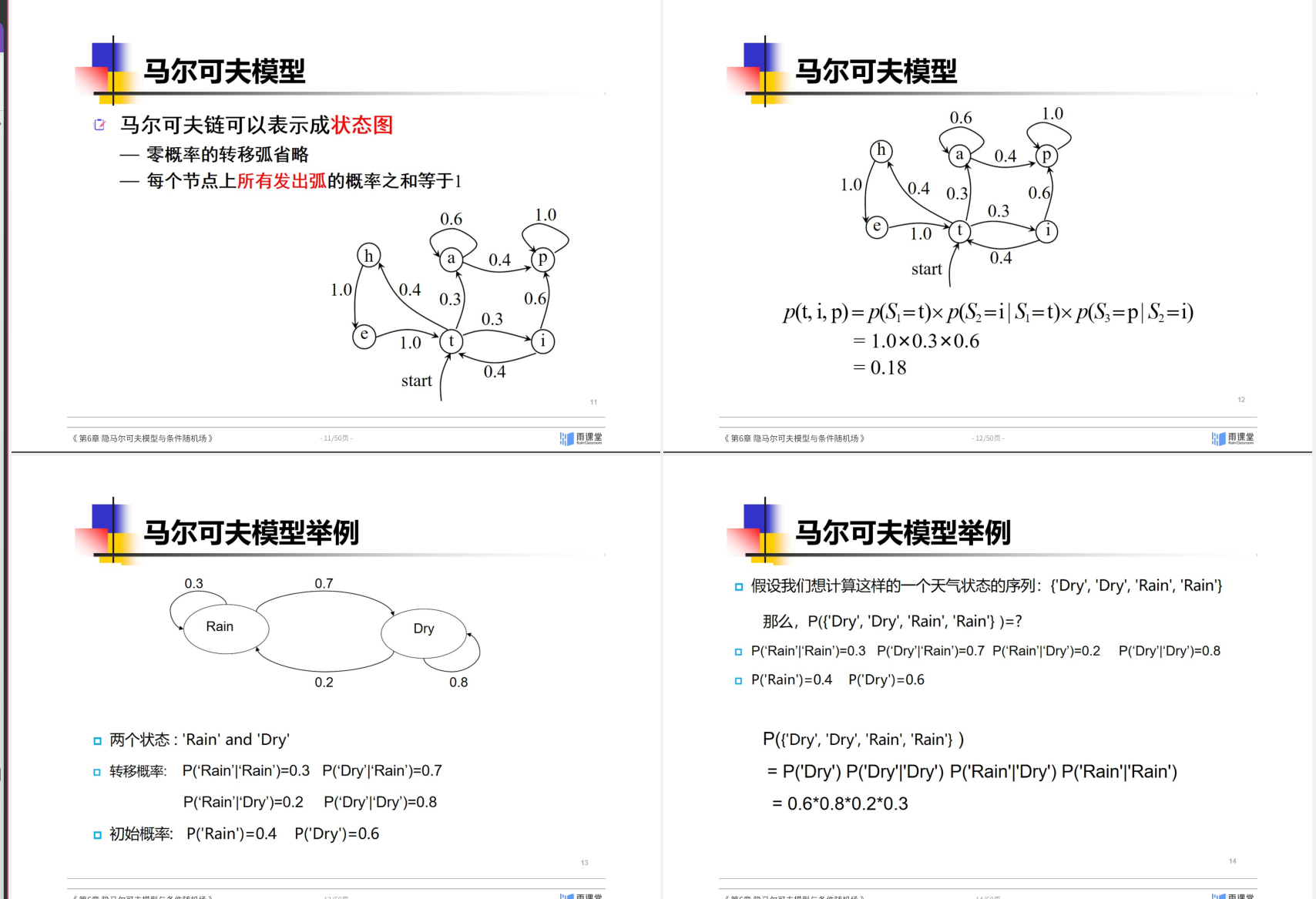
6.1 马尔可夫链

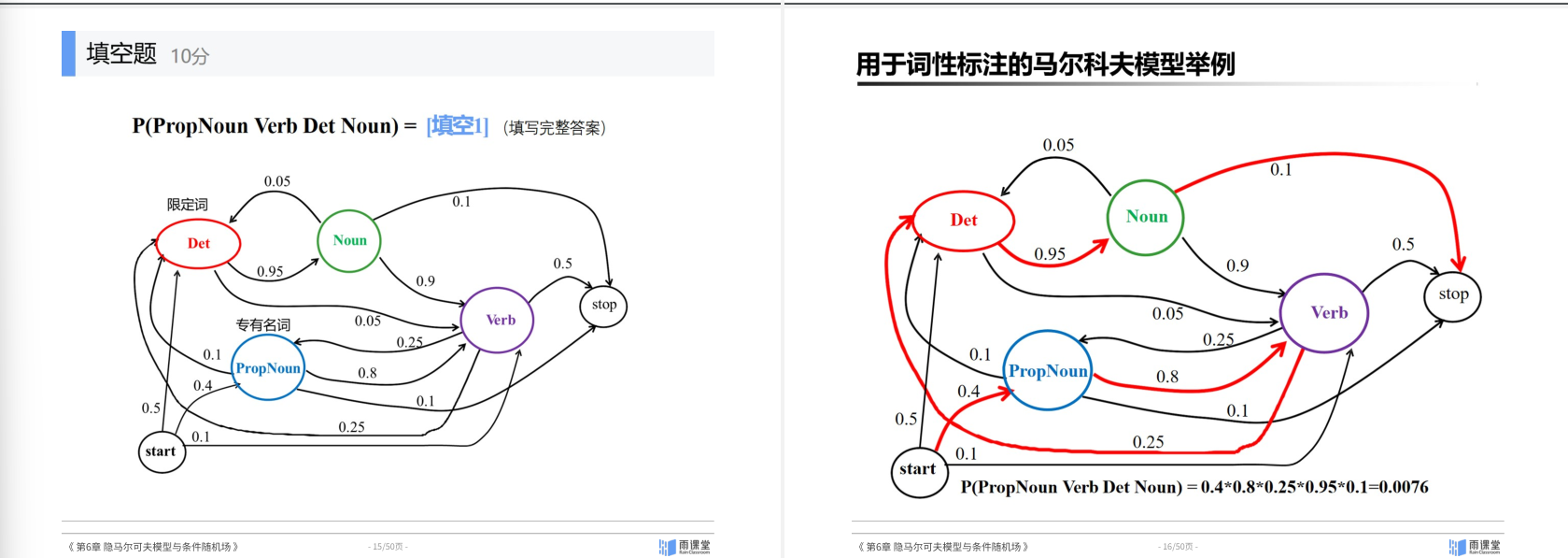
6.2 Hidden Markov Model
HMM教学案例:天气预测与冰淇淋观测
前向传播


隐马尔可夫模型(HMM)的三个核心问题是:
- 评估问题(Evaluation Problem):
给定一个HMM模型(包括状态转移概率、观测概率和初始状态分布)和一个观测序列,计算该观测序列出现的概率。通常使用前向算法(Forward Algorithm)或后向算法(Backward Algorithm)解决。 - 解码问题(Decoding Problem):
给定一个HMM模型和一个观测序列,找出最有可能生成该观测序列的隐藏状态序列。通常使用维特比算法(Viterbi Algorithm)来寻找最优状态序列。 - 学习问题(Learning Problem):
给定一个观测序列(或多个观测序列),估计HMM模型的参数(状态转移概率、观测概率和初始状态分布),使模型最优。通常使用Baum-Welch算法(一种期望最大化算法)来解决。 Expectation-Maximization EM算法
这三个问题是HMM理论和应用的基石,分别对应概率计算、状态推断和模型训练。
第二个后向算法


说实话这个后向算法跟前向算法本质没有区别,而且感觉不过是从前往后推导和从后往前的区别 不用担心,只需搞懂一个即可
如果说前向后向是用来 评估(评估某种序列出现的概率)
那么维特比算法就是用来 解码(找出最优状态序列) 有趣
第三个 维特比算法
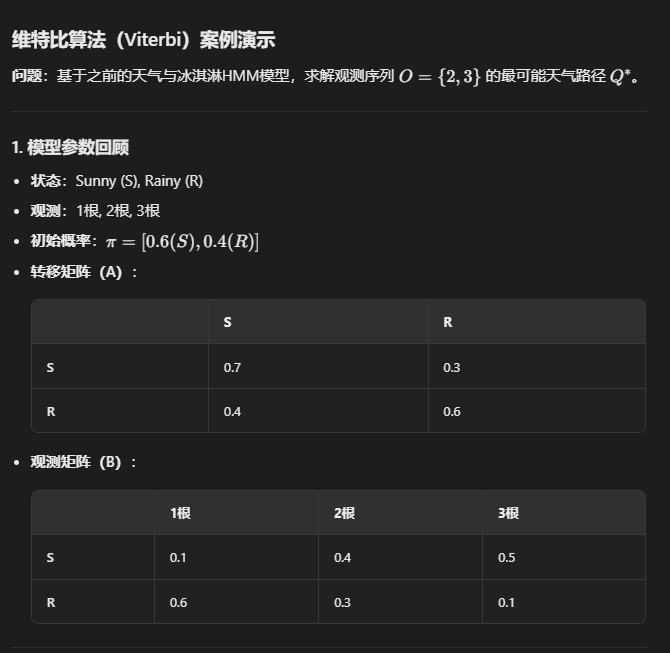
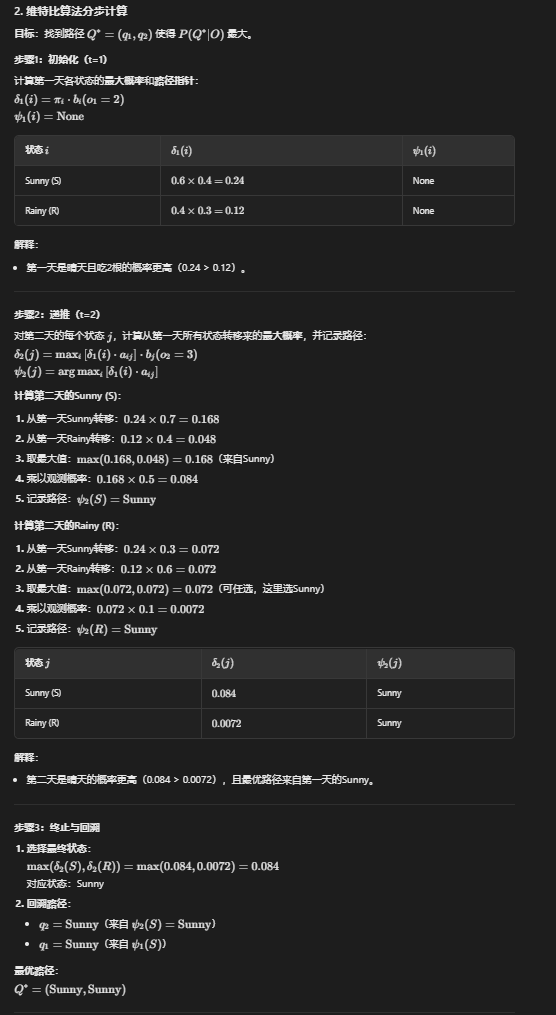
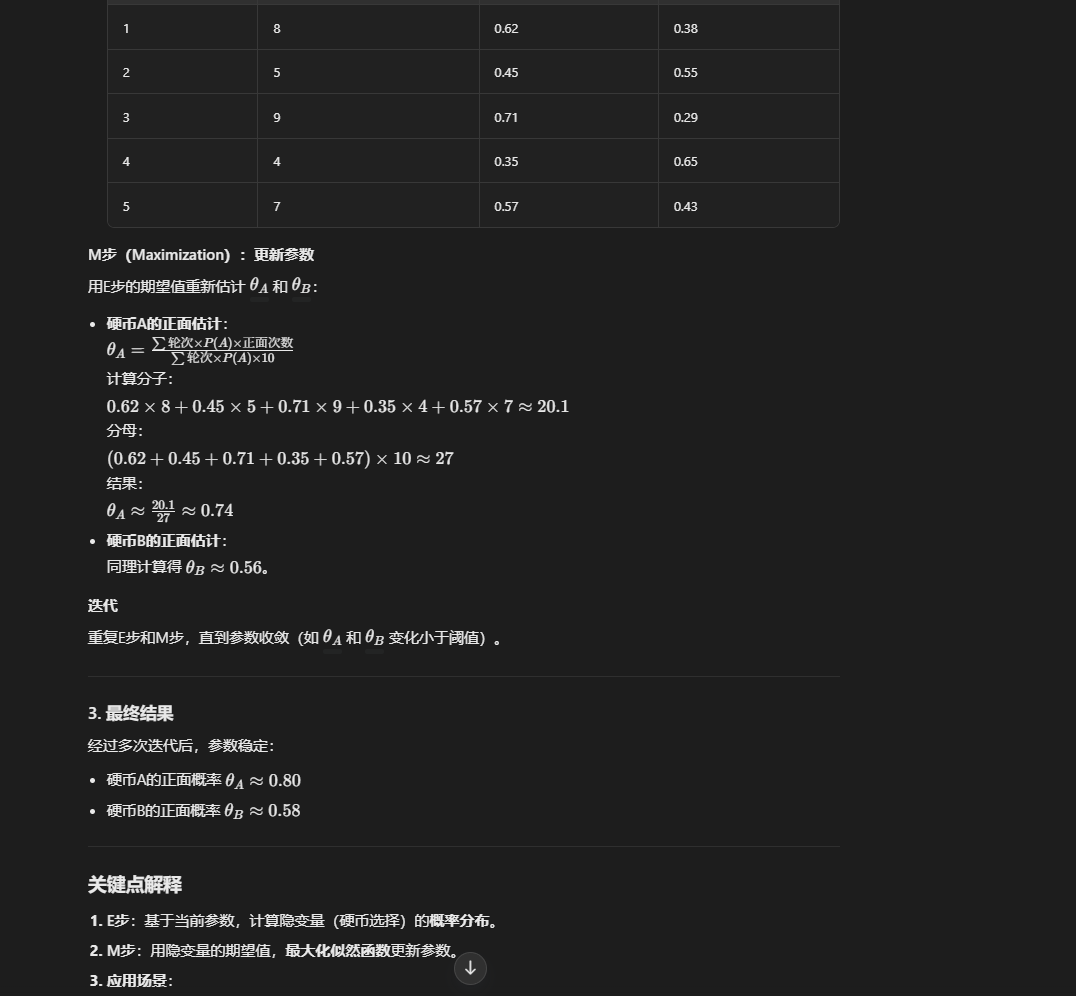
参数学习 EM期望值最大算法
还是要用到最大似然估计 收敛到参数theta

总结

Conditional Random Fields CRFs 条件随机场

自动分词
- 分词面临难点
- 汉语分词中歧义(组合型歧义AB A B和交集型ABC AB BC歧义)
- 分词性能评价 查准率 查全率 以及f1score P和R的调和平均 2xy/(x+y)
- 自动分词的基本算法:FMM BMM MM
- 词性标注
分词考点
1. 分词面临的难点
- 未登录词识别:新词(如网络用语、专有名词)的发现与切分
- 歧义消解:同一字符串存在多种切分方式(核心难点)
2. 汉语分词歧义类型
交集型 结合成分子 合成 成分 ABC AB BC

门 把 手 弄坏了
门把手 弄坏了
3. 分词性能评价指标
- 准确率 (Precision):正确切分词数 / 系统输出总词数
- 召回率 (Recall):正确切分词数 / 标准答案总词数
- F1值:准确率与召回率的调和平均(2×P×R/(P+R))
4. 自动分词基本算法
| 算法 | 全称 | 切分方向 | 特点 |
|---|---|---|---|
| FMM | 正向最大匹配 | 从左到右 | 贪心匹配最长词,可能忽略局部最优 |
| BMM | 反向最大匹配 | 从右到左 | 对右边界歧义处理优于FMM |
| MM | 双向最大匹配 | 结合FMM+BMM | 综合两者结果,按规则选择最优解 |
| 考点:词典大小对效果的影响、时间复杂度分析(O(n)) |
FMM forward maximum match
从前往后,从词典中找最长的匹配的, 如果句子中没有,那么从词典中找第二长的词 以此类推.
例如 中国人民大学 (词典:中国 人民 中国人民 人民大学 大学 )
先找4个字,匹配到中国人民 然后剩大学 得到 中国人民/大学
BMM backword maximum match
类似的 从后往前匹配最大的
中国人民大学
先匹配人民大学 再中国
中国/人民大学
Bi-directional MM 双向匹配算法
若FMM和BMM结果一致则直接输出,否则输出分词少的
(意味着能够先匹配到的 优先匹配)
5. 词性标注
- 任务目标:为分词后的词语标注词性(如动词、名词等)
- 核心方法:
- 基于规则:人工制定词性消歧规则(覆盖有限)
- 基于统计:HMM/CRF(利用上下文词性转移概率)
- 深度学习:BiLSTM+CRF、BERT等端到端模型
- 评价指标:词性标注准确率(与人工标注对比)

8 句法分析
- 形式语言:定义 终结符/非终结符 推导(最左/最右推导) 正则文法与L(G)关系
上下文无关文法(CFG) context free grammars
能够得到L(G)
- 短语结构分析:线图分析法 CYK分析法 概率上下文无关法 概率上下文无关文法(PCFG) 及三个问题 句法分析器性能评估
- 依存句法分析:依存语法公理 依存分析算法(移进-归约,Arc-eager) 依存句法分析器性能评价
- 短语结构与依存结构的关系:中心词提取规则


总结表格
| 符号 | 缩写来源 | 含义 | 示例(数学表达式文法) |
|---|---|---|---|
| G | Grammar | 形式文法本身 | G=(N,Σ,P,S) |
| N | Non-terminal symbols | 非终结符集合 | {E,T,F} |
| Σ | Terminal symbols | 终结符集合 | {a,+,∗,(,)} |
| P | Production rules | 产生式规则集合 | E→E+T∣T |
| S | Start symbol | 开始符号 | E |
句法分析考点详解



看懂了其实也就还好 无非是最左推导和最右推导来推形式语法四元组

A 考虑最左推导会卡壳 所以采用最右推导 并且过程中要考虑n次方问题
有以下文法:G=({S,B,C},{a,b,c},P,S),其中:
P:S→aSBC/abC ;СВ→ВС ; bВ→bb ; bC->bc ;cС→cc
求L(G)=?
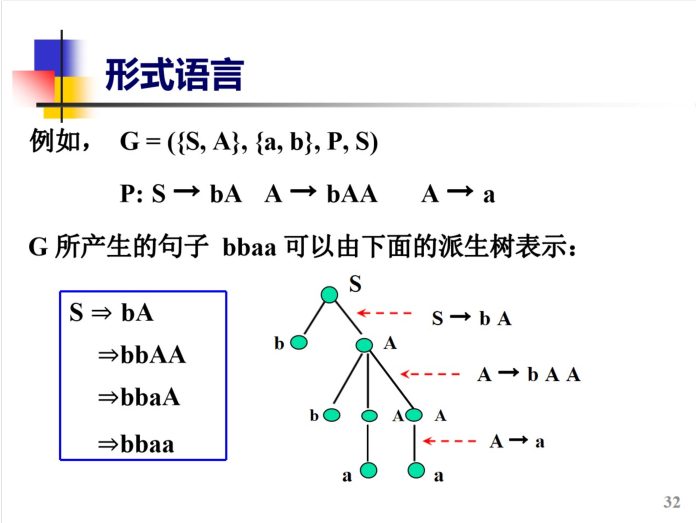
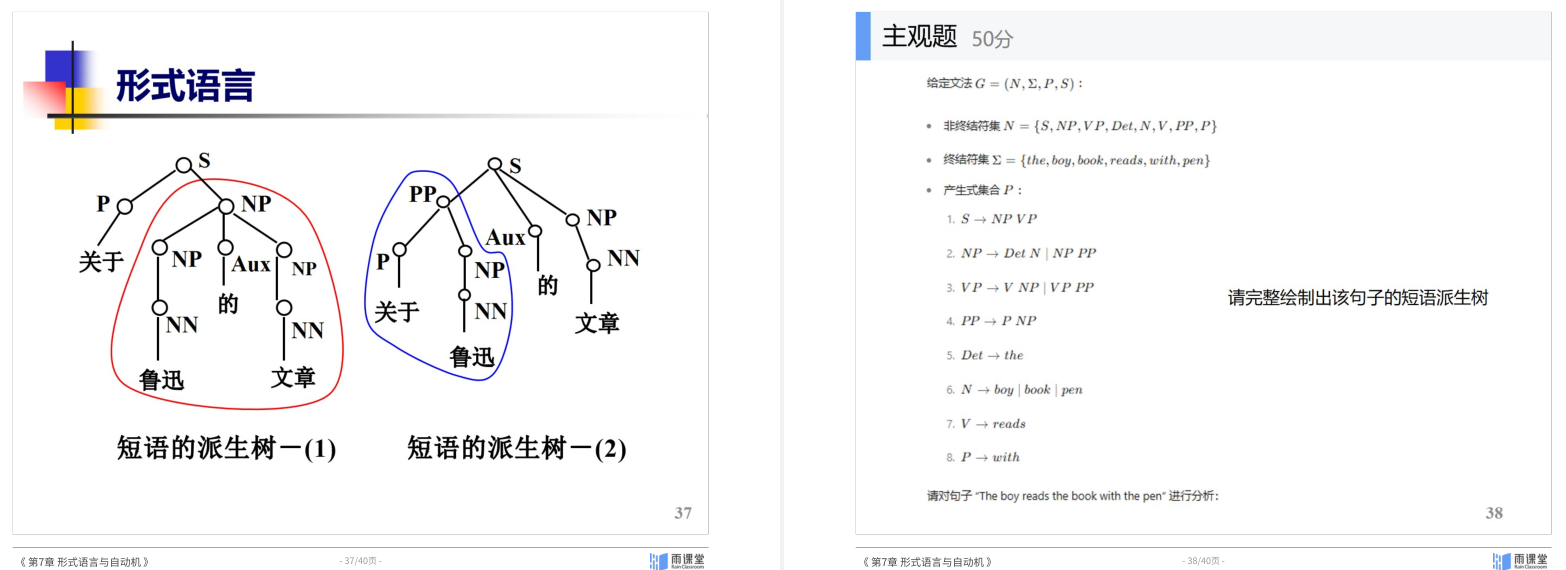

同样有最左推导和最右推导两个方法
- 短语结构分析:线图分析法 CYK分析法 概率上下文无关法 概率上下文无关文法(PCFG) 及三个问题 句法分析器性能评估
线图分析法

CYK
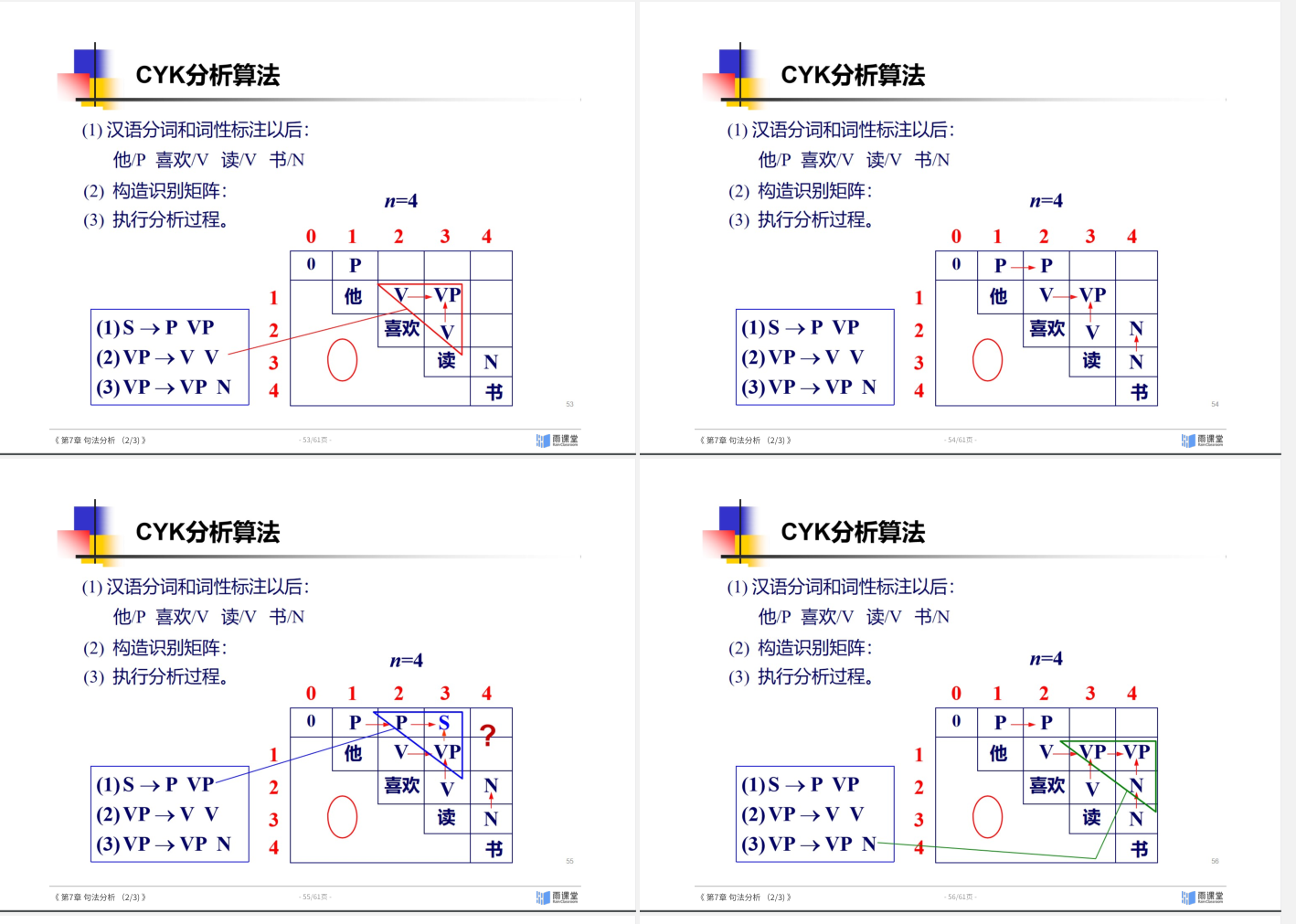

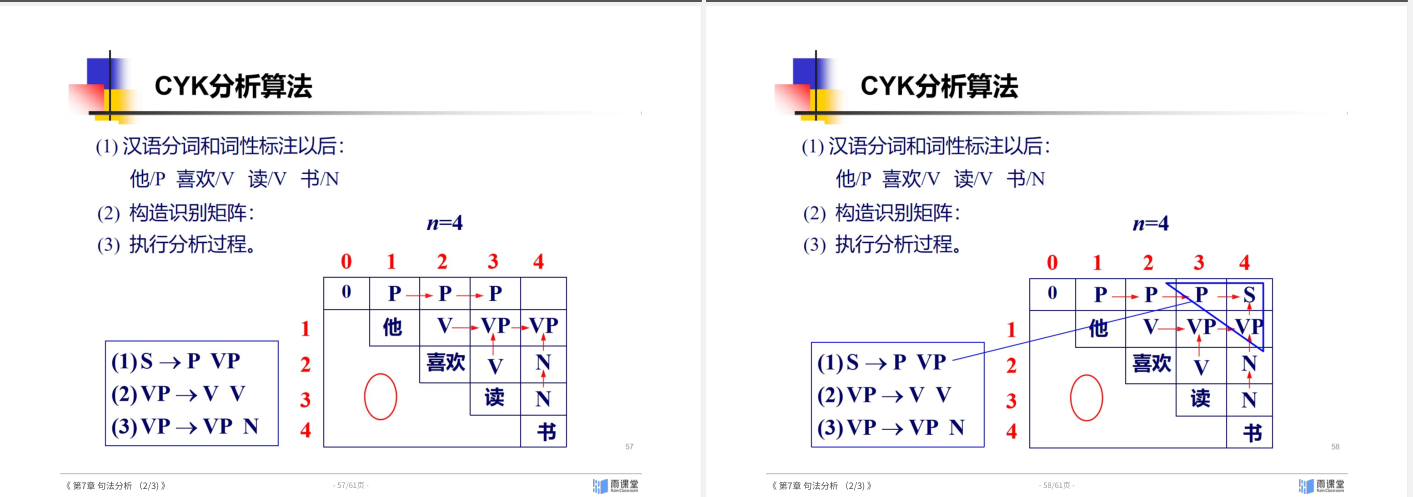
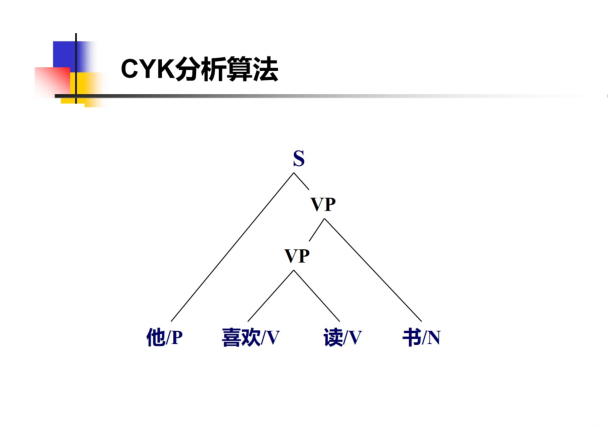




PCFG的三个核心问题:

- 依存句法分析:依存语法公理 依存分析算法(移进-归约,Arc-eager) 依存句法分析器性能评价
- 短语结构与依存结构的关系:中心词提取规则

PCFG
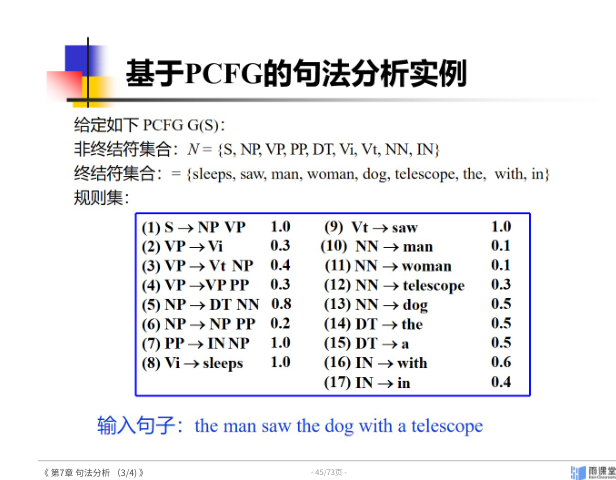
9 语义分析
- 词汇语义理论
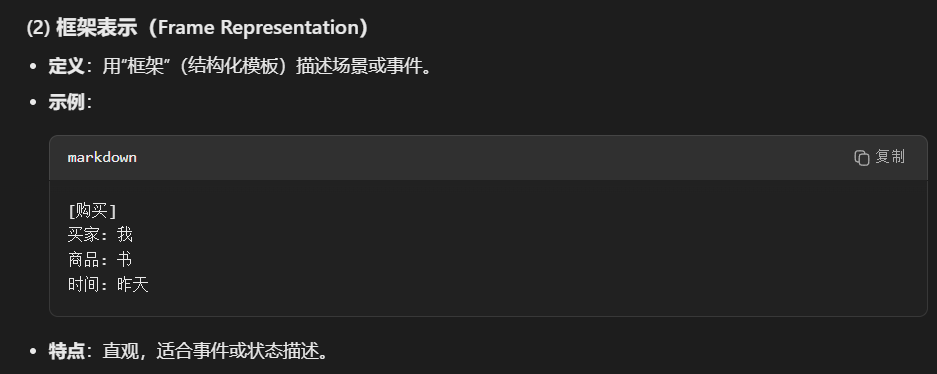
- 语义表示 谓词逻辑表示 框架表示 语义网表示 分布式表示
- 词义消歧
- 语义角色标注