1 实验目的
理解 Apriori 和 FP-growth 算法的基本原理
学会用 python 实现 Apriori 算法进行关联分析
学会用 python 实现 FP-growth 算法进行关联分析
手写/调库 实现Apriori/FP-growth 算法
在给定置信度,支持度,数据的情况下计算频繁项集,关联规则
2 开发环境
编程软件:anconda/spyder/pycharm
环境:python3.6 以上、numpy、pandas、sklearn、Jupyter Notebook 等
3 实验内容及代码
3.1 Apriori 算法
3.1.1 手写
"""
Apriori算法纯Python手写实现
详细中文注释
"""
from itertools import combinations
def create_C1(transactions):
"""
构造候选1项集(C1),即所有商品的集合,每个商品单独成集。
参数:
transactions: 事务数据列表,每个元素是一个事务(商品集合)
返回:
C1: 候选1项集列表,每个元素是frozenset
"""
C1 = set()
for t in transactions:
for item in t:
C1.add(frozenset([item]))
return list(C1)
def scan_D(D, Ck, min_support):
"""
扫描数据集,计算每个候选项集的支持度,返回满足最小支持度的频繁项集。
参数:
D: 事务集,每个事务是set
Ck: 候选k项集列表
min_support: 最小支持度(0-1)
返回:
ret_list: 满足支持度的频繁项集
support_data: 所有项集的支持度字典
"""
ss_cnt = {}
for tid in D:
for can in Ck:
if can.issubset(tid):
ss_cnt[can] = ss_cnt.get(can, 0) + 1
num_items = float(len(D))
ret_list = []
support_data = {}
for key in ss_cnt:
support = ss_cnt[key] / num_items
if support >= min_support:
ret_list.append(key)
support_data[key] = support
return ret_list, support_data
def apriori_gen(Lk, k):
"""
根据上一次的频繁(k-1)项集Lk,生成候选k项集Ck
参数:
Lk: 上一层频繁项集
k: 当前项集大小
返回:
ret_list: 候选k项集列表
"""
ret_list = []
len_Lk = len(Lk)
for i in range(len_Lk):
for j in range(i+1, len_Lk):
L1 = list(Lk[i])[:k-2]
L2 = list(Lk[j])[:k-2]
L1.sort(); L2.sort()
if L1 == L2:
ret_list.append(Lk[i] | Lk[j])
return ret_list
def apriori(transactions, min_support=0.3):
"""
Apriori主流程,返回所有层的频繁项集和支持度字典
参数:
transactions: 原始事务数据
min_support: 最小支持度
返回:
L: 各层频繁项集列表(L[0]是一项集,L[1]是二项集...)
support_data: 所有项集的支持度字典
"""
D = list(map(set, transactions))
C1 = create_C1(D)
L1, support_data = scan_D(D, C1, min_support)
L = [L1]
k = 2
while len(L[k-2]) > 0:
Ck = apriori_gen(L[k-2], k)
Lk, supK = scan_D(D, Ck, min_support)
support_data.update(supK)
if not Lk:
break
L.append(Lk)
k += 1
return L, support_data
def generate_rules(L, support_data, min_confidence=0.7):
"""
由频繁项集生成满足最小置信度的关联规则
参数:
L: 各层频繁项集列表
support_data: 支持度字典
min_confidence: 最小置信度
返回:
rules: 满足条件的规则列表(前件, 后件, 置信度)
"""
rules = []
for i in range(1, len(L)):
for freq_set in L[i]:
H1 = [frozenset([item]) for item in freq_set]
if i > 1:
rules_from_conseq(freq_set, H1, support_data, rules, min_confidence)
else:
calc_conf(freq_set, H1, support_data, rules, min_confidence)
return rules
def calc_conf(freq_set, H, support_data, rules, min_confidence):
"""
计算规则的置信度,筛选出满足条件的规则
"""
pruned_H = []
for conseq in H:
conf = support_data[freq_set] / support_data[freq_set - conseq]
if conf >= min_confidence:
rules.append((freq_set - conseq, conseq, conf))
pruned_H.append(conseq)
return pruned_H
def rules_from_conseq(freq_set, H, support_data, rules, min_confidence):
"""
递归生成多后件的规则
"""
m = len(H[0])
if len(freq_set) > (m + 1):
Hmp1 = apriori_gen(H, m+1)
Hmp1 = calc_conf(freq_set, Hmp1, support_data, rules, min_confidence)
if len(Hmp1) > 1:
rules_from_conseq(freq_set, Hmp1, support_data, rules, min_confidence)
3.1.2 调库
"""
Apriori算法库函数版(mlxtend)
详细中文注释
"""
import pandas as pd
from mlxtend.frequent_patterns import apriori, association_rules
def create_one_hot(transactions):
"""
将原始事务数据转换为 one-hot 编码的 DataFrame,适用于mlxtend算法。
参数:
transactions: 事务数据列表,每个元素是一个商品集合
返回:
df: one-hot编码后的pandas DataFrame
"""
all_items = sorted(set(item for t in transactions for item in t)) # 所有商品去重排序
encoded = []
for t in transactions:
encoded.append([1 if item in t else 0 for item in all_items]) # 有则1,无则0
return pd.DataFrame(encoded, columns=all_items)
# 用法示例:
# df = create_one_hot(transactions) # 转换为one-hot
# frequent_itemsets = apriori(df, min_support=0.3, use_colnames=True) # 频繁项集
# rules = association_rules(frequent_itemsets, metric='confidence', min_threshold=0.7) # 关联规则
3.2 FP-growth 算法
3.2.1 手写
"""
Apriori算法纯Python手写实现
详细中文注释
"""
from itertools import combinations, chain
def create_C1(transactions):
"""
构造候选1项集(C1),即所有商品的集合,每个商品单独成集。
参数:
transactions: 事务数据列表,每个元素是一个事务(商品集合)
返回:
C1: 候选1项集列表,每个元素是frozenset
"""
C1 = set()
for t in transactions:
for item in t:
C1.add(frozenset([item]))
return list(C1)
def scan_D(D, Ck, min_support):
"""
扫描数据集,计算每个候选项集的支持度,返回满足最小支持度的频繁项集。
参数:
D: 事务集,每个事务是set
Ck: 候选k项集列表
min_support: 最小支持度(0-1)
返回:
ret_list: 满足支持度的频繁项集
support_data: 所有项集的支持度字典
"""
ss_cnt = {}
for tid in D:
for can in Ck:
if can.issubset(tid):
ss_cnt[can] = ss_cnt.get(can, 0) + 1
num_items = float(len(D))
ret_list = []
support_data = {}
for key in ss_cnt:
support = ss_cnt[key] / num_items
if support >= min_support:
ret_list.append(key)
support_data[key] = support
return ret_list, support_data
def apriori_gen(Lk, k):
"""
根据上一次的频繁(k-1)项集Lk,生成候选k项集Ck
参数:
Lk: 上一层频繁项集
k: 当前项集大小
返回:
ret_list: 候选k项集列表
"""
ret_list = []
len_Lk = len(Lk)
for i in range(len_Lk):
for j in range(i+1, len_Lk):
L1 = list(Lk[i])[:k-2]
L2 = list(Lk[j])[:k-2]
L1.sort(); L2.sort()
if L1 == L2:
ret_list.append(Lk[i] | Lk[j])
return ret_list
def apriori(transactions, min_support=0.3):
"""
Apriori主流程,返回所有层的频繁项集和支持度字典
参数:
transactions: 原始事务数据
min_support: 最小支持度
返回:
L: 各层频繁项集列表(L[0]是一项集,L[1]是二项集...)
support_data: 所有项集的支持度字典
"""
D = list(map(set, transactions))
C1 = create_C1(D)
L1, support_data = scan_D(D, C1, min_support)
L = [L1]
k = 2
while len(L[k-2]) > 0:
Ck = apriori_gen(L[k-2], k)
Lk, supK = scan_D(D, Ck, min_support)
support_data.update(supK)
if not Lk:
break
L.append(Lk)
k += 1
return L, support_data
def generate_rules(L, support_data, min_confidence=0.7):
"""
由频繁项集生成满足最小置信度的关联规则(全子集枚举法,完全一致于mlxtend/FP-growth实现)
参数:
L: 各层频繁项集列表
support_data: 支持度字典
min_confidence: 最小置信度
返回:
rules: 满足条件的规则列表(前件, 后件, 置信度)
"""
rules = []
# 将所有频繁项集合并成一个集合(跳过1项集)
freq_sets = set(chain.from_iterable(L[1:]))
for freq_set in freq_sets:
for i in range(1, len(freq_set)):
for antecedent in combinations(freq_set, i):
antecedent = frozenset(antecedent)
consequent = freq_set - antecedent
if len(consequent) == 0:
continue
conf = support_data[freq_set] / support_data[antecedent]
if conf >= min_confidence:
rules.append((antecedent, consequent, conf))
return rules
def calc_conf(freq_set, H, support_data, rules, min_confidence):
"""
计算规则的置信度,筛选出满足条件的规则
"""
pruned_H = []
for conseq in H:
conf = support_data[freq_set] / support_data[freq_set - conseq]
if conf >= min_confidence:
rules.append((freq_set - conseq, conseq, conf))
pruned_H.append(conseq)
return pruned_H
def rules_from_conseq(freq_set, H, support_data, rules, min_confidence):
"""
递归生成多后件的规则
"""
m = len(H[0])
if len(freq_set) > (m + 1):
Hmp1 = apriori_gen(H, m+1)
Hmp1 = calc_conf(freq_set, Hmp1, support_data, rules, min_confidence)
if len(Hmp1) > 1:
rules_from_conseq(freq_set, Hmp1, support_data, rules, min_confidence)
3.2.2 调库
"""
FP-growth算法库函数版(mlxtend)
详细中文注释
"""
import pandas as pd
from mlxtend.frequent_patterns import fpgrowth, association_rules
def create_one_hot(transactions):
"""
将原始事务数据转换为 one-hot 编码的 DataFrame,适用于mlxtend算法。
参数:
transactions: 事务数据列表,每个元素是一个商品集合
返回:
df: one-hot编码后的pandas DataFrame
"""
all_items = sorted(set(item for t in transactions for item in t)) # 所有商品去重排序
encoded = []
for t in transactions:
encoded.append([1 if item in t else 0 for item in all_items]) # 有则1,无则0
return pd.DataFrame(encoded, columns=all_items)
# 用法示例:
# df = create_one_hot(transactions) # 转换为one-hot
# frequent_itemsets = fpgrowth(df, min_support=0.3, use_colnames=True) # 频繁项集
# rules = association_rules(frequent_itemsets, metric='confidence', min_threshold=0.7) # 关联规则
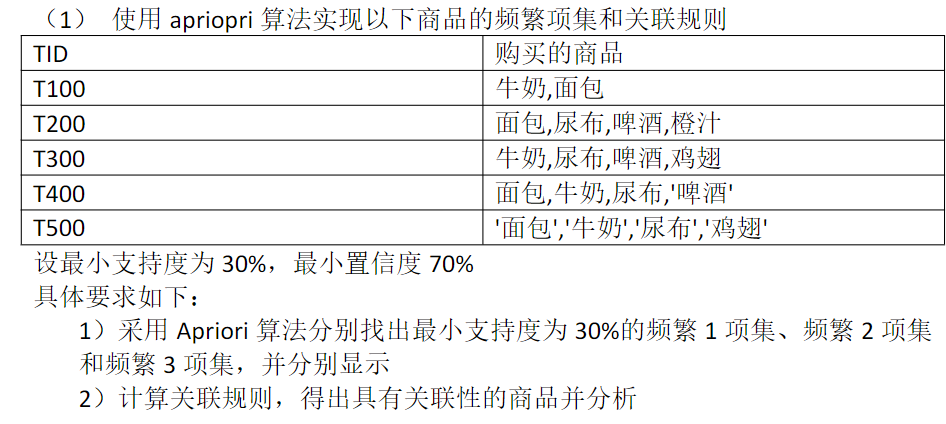
3.3 分别用以上四种版本算法对小数据进行测试
"""
对比测试Apriori/FP-growth四种实现(手写/库)
数据:T100~T500
最小支持度0.3,最小置信度0.7
输出所有频繁1,2,3项集及关联规则
"""
from apriori_handwritten import apriori, generate_rules
from fpgrowth_handwritten import fp_growth, generate_rules_fp
from apriori_library import create_one_hot as create_one_hot_ap, apriori as apriori_lib, association_rules as association_rules_ap
from fpgrowth_library import create_one_hot as create_one_hot_fp, fpgrowth as fpgrowth_lib, association_rules as association_rules_fp
import pandas as pd
# 测试数据
transactions = [
['牛奶', '面包'],
['面包', '尿布', '啤酒', '橙汁'],
['牛奶', '尿布', '啤酒', '鸡翅'],
['面包', '牛奶', '尿布', '啤酒'],
['面包', '牛奶', '尿布', '鸡翅']
]
min_support = 0.3
min_conf = 0.7
def print_freq_itemsets_ap(L, support_data):
for k in [1,2,3]:
print(f"频繁{k}项集:")
for item in L[k-1]:
print(f" {set(item)} 支持度: {support_data[item]:.2f}")
print()
def print_rules_ap(rules):
print("关联规则:")
for pre, post, conf in rules:
print(f" {set(pre)} => {set(post)}, 置信度: {conf:.2f}")
print()
def print_freq_itemsets_lib(frequent_itemsets):
for k in [1,2,3]:
print(f"频繁{k}项集:")
sub = frequent_itemsets[frequent_itemsets['itemsets'].apply(lambda x: len(x)==k)]
for _, row in sub.iterrows():
print(f" {set(row['itemsets'])} 支持度: {row['support']:.2f}")
print()
def print_rules_lib(rules):
print("关联规则:")
for _, row in rules.iterrows():
print(f" {set(row['antecedents'])} => {set(row['consequents'])}, 置信度: {row['confidence']:.2f}")
print()
if __name__ == '__main__':
print("===== 1. Apriori 手写版 =====")
L, support_data = apriori(transactions, min_support=min_support)
print_freq_itemsets_ap(L, support_data)
rules = generate_rules(L, support_data, min_confidence=min_conf)
print_rules_ap(rules)
print("===== 2. Apriori 库函数版 =====")
df_ap = create_one_hot_ap(transactions)
frequent_itemsets = apriori_lib(df_ap, min_support=min_support, use_colnames=True)
print_freq_itemsets_lib(frequent_itemsets)
rules = association_rules_ap(frequent_itemsets, metric='confidence', min_threshold=min_conf)
print_rules_lib(rules)
print("===== 3. FP-growth 手写版 =====")
freq_items, support_data = fp_growth(transactions, min_support=min_support)
for k in [1,2,3]:
print(f"频繁{k}项集:")
for item, support in freq_items:
if len(item)==k:
print(f" {set(item)} 支持度: {support:.2f}")
print()
rules = generate_rules_fp(freq_items, support_data, min_confidence=min_conf)
print_rules_ap(rules)
print("===== 4. FP-growth 库函数版 =====")
df_fp = create_one_hot_fp(transactions)
frequent_itemsets = fpgrowth_lib(df_fp, min_support=min_support, use_colnames=True)
print_freq_itemsets_lib(frequent_itemsets)
rules = association_rules_fp(frequent_itemsets, metric='confidence', min_threshold=min_conf)
print_rules_lib(rules)3.4 处理完整数据
"""
超市购物篮数据关联规则分析(Apriori/FP-growth库版)
步骤:
1. 数据探索与可视化
2. 数据清洗与预处理
3. 按星期分析交易量
4. 数据格式转换
5. Apriori算法频繁项集与关联规则分析
6. FP-growth算法频繁项集与关联规则分析
7. 结果业务解读与建议
"""
import pandas as pd
import matplotlib.pyplot as plt
from mlxtend.frequent_patterns import apriori, association_rules, fpgrowth
from mlxtend.preprocessing import TransactionEncoder
# 1. 数据加载与探索
file_path = '../data/BreadBasket_DMS.csv'
df = pd.read_csv(file_path)
print('数据集基本信息:')
print(df.info())
print('\n前5行:')
print(df.head())
# 2. 数据预处理
# 去除缺失值、未购买项(Item为NONE)、重复项
print('\n缺失值统计:')
print(df.isnull().sum())
df = df.dropna()
df = df[df['Item'].str.upper() != 'NONE']
df = df.drop_duplicates()
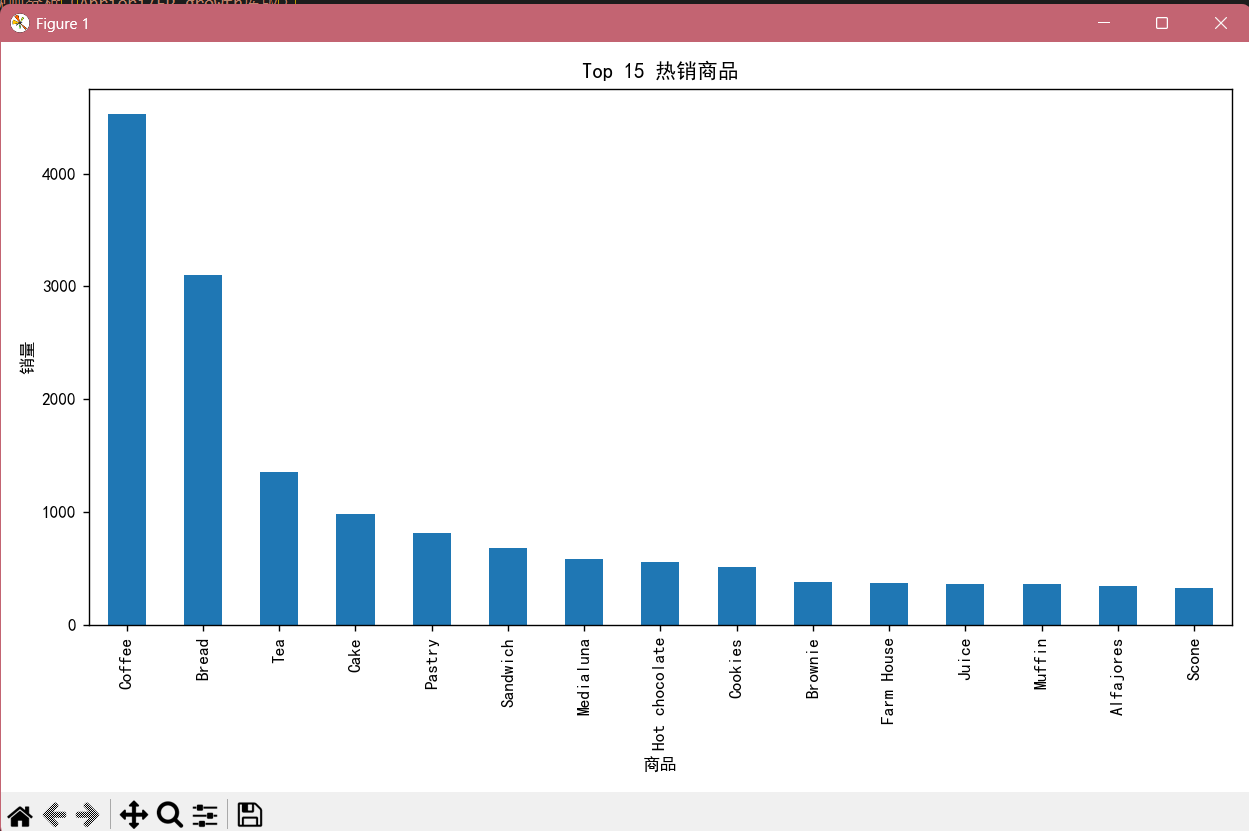
# 3. 热销商品分析
item_counts = df['Item'].value_counts()
print('\n热销商品Top15:')
print(item_counts.head(15))
plt.figure(figsize=(10,6))
item_counts.head(15).plot(kind='bar')
plt.title('Top 15 热销商品')
plt.ylabel('销量')
plt.xlabel('商品')
plt.tight_layout()
plt.show()
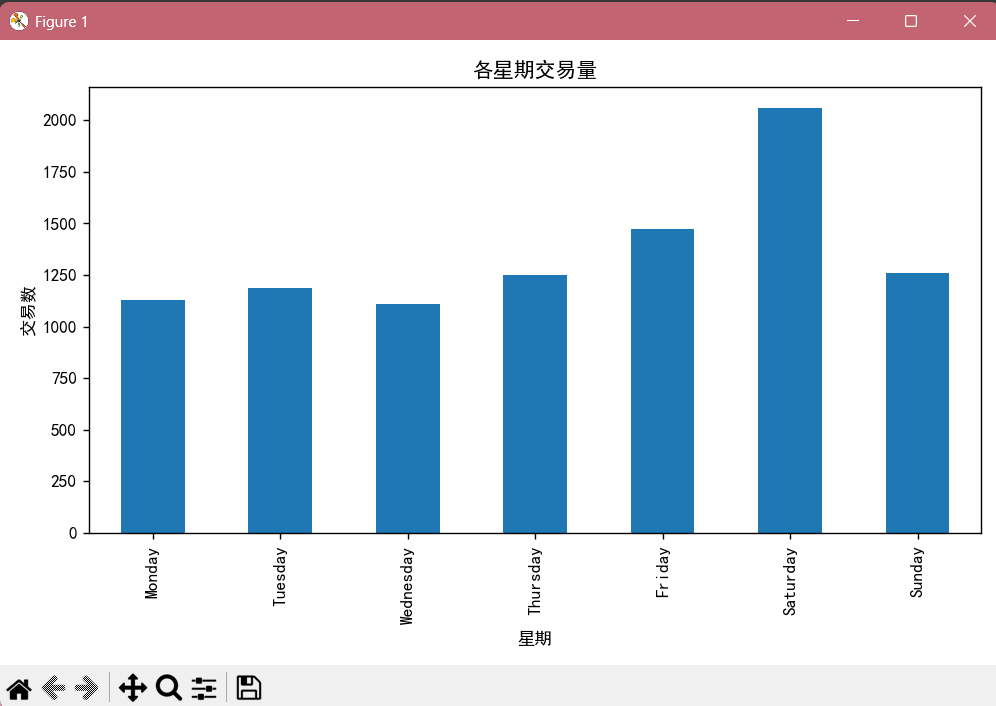
# 4. 按星期分析交易量
# 增加星期字段
import datetime
df['Date'] = pd.to_datetime(df['Date'])
df['Weekday'] = df['Date'].dt.day_name()
weekday_counts = df.groupby('Weekday')['Transaction'].nunique().reindex([
'Monday','Tuesday','Wednesday','Thursday','Friday','Saturday','Sunday'])
print('\n各星期交易量:')
print(weekday_counts)
plt.figure(figsize=(8,5))
weekday_counts.plot(kind='bar')
plt.title('各星期交易量')
plt.ylabel('交易数')
plt.xlabel('星期')
plt.tight_layout()
plt.show()
# 5. 数据格式转换(Transaction列表)
transactions = df.groupby('Transaction')['Item'].apply(list).tolist()
# 6. One-hot编码
te = TransactionEncoder()
te_ary = te.fit(transactions).transform(transactions)
df_onehot = pd.DataFrame(te_ary, columns=te.columns_)
# 7. Apriori算法分析
print('\n===== Apriori 频繁项集(支持度≥0.05) =====')
frequent_itemsets = apriori(df_onehot, min_support=0.05, use_colnames=True)
frequent_itemsets = frequent_itemsets.sort_values(by='support', ascending=False)
print(frequent_itemsets.head(20))
print('\n===== Apriori 关联规则(置信度≥0.5) =====')
rules = association_rules(frequent_itemsets, metric='confidence', min_threshold=0.5)
rules = rules.sort_values(by='confidence', ascending=False)
print(rules[['antecedents','consequents','support','confidence','lift']].head(20))
print('\n===== Apriori 关联规则(提升度>1,真实联系) =====')
rules_lift = rules[rules['lift'] > 1].sort_values(by='lift', ascending=False)
print(rules_lift[['antecedents','consequents','support','confidence','lift']].head(20))
# 8. FP-growth算法分析
print('\n===== FP-growth 频繁项集(支持度≥0.05) =====')
fp_itemsets = fpgrowth(df_onehot, min_support=0.05, use_colnames=True)
fp_itemsets = fp_itemsets.sort_values(by='support', ascending=False)
print(fp_itemsets.head(20))
print('\n===== FP-growth 关联规则(置信度≥0.5) =====')
fp_rules = association_rules(fp_itemsets, metric='confidence', min_threshold=0.5)
fp_rules = fp_rules.sort_values(by='confidence', ascending=False)
print(fp_rules[['antecedents','consequents','support','confidence','lift']].head(20))
# 9. 业务分析与建议(示例输出)
print('\n【业务分析建议】')
print('1. 热销商品主要为咖啡、面包等,可重点备货。')
print('2. 频繁项集和高置信度、高提升度规则显示:部分商品常被一起购买(如Coffee与Bread),可考虑捆绑销售。')
print('3. 周末交易量显著高于工作日,可在周末增加促销活动。')
print('4. FP-growth与Apriori结果高度一致,FP-growth更适合大数据场景。')
4 实验结果分析
4.1 test 两种算法四个版本
(cloudcomputing) PS C:\Coding\云计算> & C:/DevelopmentTools/Anaconda3/envs/cloudcomputing/python.exe c:/Coding/云计算/大数据关联分析实验/src/test_all_algorithms.py
===== 1. Apriori 手写版 =====
频繁1项集:
{‘面包’} 支持度: 0.80
{‘牛奶’} 支持度: 0.80
{‘啤酒’} 支持度: 0.60
{‘尿布’} 支持度: 0.80
{‘鸡翅’} 支持度: 0.40频繁2项集:
{‘面包’, ‘牛奶’} 支持度: 0.60
{‘面包’, ‘啤酒’} 支持度: 0.40
{‘面包’, ‘尿布’} 支持度: 0.60
{‘啤酒’, ‘尿布’} 支持度: 0.60
{‘啤酒’, ‘牛奶’} 支持度: 0.40
{‘牛奶’, ‘尿布’} 支持度: 0.60
{‘鸡翅’, ‘牛奶’} 支持度: 0.40
{‘鸡翅’, ‘尿布’} 支持度: 0.40频繁3项集:
{‘面包’, ‘啤酒’, ‘尿布’} 支持度: 0.40
{‘啤酒’, ‘牛奶’, ‘尿布’} 支持度: 0.40
{‘鸡翅’, ‘牛奶’, ‘尿布’} 支持度: 0.40
{‘面包’, ‘牛奶’, ‘尿布’} 支持度: 0.40关联规则:
{‘啤酒’, ‘牛奶’} => {‘尿布’}, 置信度: 1.00
{‘鸡翅’} => {‘尿布’}, 置信度: 1.00
{‘面包’, ‘啤酒’} => {‘尿布’}, 置信度: 1.00
{‘面包’} => {‘牛奶’}, 置信度: 0.75
{‘牛奶’} => {‘面包’}, 置信度: 0.75
{‘啤酒’} => {‘尿布’}, 置信度: 1.00
{‘尿布’} => {‘啤酒’}, 置信度: 0.75
{‘面包’} => {‘尿布’}, 置信度: 0.75
{‘尿布’} => {‘面包’}, 置信度: 0.75
{‘牛奶’} => {‘尿布’}, 置信度: 0.75
{‘尿布’} => {‘牛奶’}, 置信度: 0.75
{‘鸡翅’} => {‘牛奶’, ‘尿布’}, 置信度: 1.00
{‘鸡翅’, ‘牛奶’} => {‘尿布’}, 置信度: 1.00
{‘鸡翅’, ‘尿布’} => {‘牛奶’}, 置信度: 1.00
{‘鸡翅’} => {‘牛奶’}, 置信度: 1.00===== 2. Apriori 库函数版 =====
C:\DevelopmentTools\Anaconda3\envs\cloudcomputing\Lib\site-packages\mlxtend\frequent_patterns\fpcommon.py:161: DeprecationWarning: DataFrames with non-bool types result in worse computationalperformance and their support might be discontinued in the future.Please use a DataFrame with bool type
warnings.warn(
频繁1项集:
{‘啤酒’} 支持度: 0.60
{‘尿布’} 支持度: 0.80
{‘牛奶’} 支持度: 0.80
{‘面包’} 支持度: 0.80
{‘鸡翅’} 支持度: 0.40频繁2项集:
{‘啤酒’, ‘尿布’} 支持度: 0.60
{‘啤酒’, ‘牛奶’} 支持度: 0.40
{‘面包’, ‘啤酒’} 支持度: 0.40
{‘牛奶’, ‘尿布’} 支持度: 0.60
{‘面包’, ‘尿布’} 支持度: 0.60
{‘鸡翅’, ‘尿布’} 支持度: 0.40
{‘面包’, ‘牛奶’} 支持度: 0.60
{‘鸡翅’, ‘牛奶’} 支持度: 0.40频繁3项集:
{‘啤酒’, ‘牛奶’, ‘尿布’} 支持度: 0.40
{‘面包’, ‘啤酒’, ‘尿布’} 支持度: 0.40
{‘面包’, ‘牛奶’, ‘尿布’} 支持度: 0.40
{‘牛奶’, ‘鸡翅’, ‘尿布’} 支持度: 0.40关联规则:
{‘啤酒’} => {‘尿布’}, 置信度: 1.00
{‘尿布’} => {‘啤酒’}, 置信度: 0.75
{‘牛奶’} => {‘尿布’}, 置信度: 0.75
{‘尿布’} => {‘牛奶’}, 置信度: 0.75
{‘面包’} => {‘尿布’}, 置信度: 0.75
{‘尿布’} => {‘面包’}, 置信度: 0.75
{‘鸡翅’} => {‘尿布’}, 置信度: 1.00
{‘面包’} => {‘牛奶’}, 置信度: 0.75
{‘牛奶’} => {‘面包’}, 置信度: 0.75
{‘鸡翅’} => {‘牛奶’}, 置信度: 1.00
{‘啤酒’, ‘牛奶’} => {‘尿布’}, 置信度: 1.00
{‘面包’, ‘啤酒’} => {‘尿布’}, 置信度: 1.00
{‘鸡翅’, ‘牛奶’} => {‘尿布’}, 置信度: 1.00
{‘鸡翅’, ‘尿布’} => {‘牛奶’}, 置信度: 1.00
{‘鸡翅’} => {‘牛奶’, ‘尿布’}, 置信度: 1.00===== 3. FP-growth 手写版 =====
频繁1项集:
{‘鸡翅’} 支持度: 0.40
{‘啤酒’} 支持度: 0.60
{‘面包’} 支持度: 0.80
{‘牛奶’} 支持度: 0.80
{‘尿布’} 支持度: 0.80频繁2项集:
{‘鸡翅’, ‘牛奶’} 支持度: 0.40
{‘鸡翅’, ‘尿布’} 支持度: 0.40
{‘面包’, ‘啤酒’} 支持度: 0.40
{‘啤酒’, ‘牛奶’} 支持度: 0.40
{‘啤酒’, ‘尿布’} 支持度: 0.60
{‘面包’, ‘牛奶’} 支持度: 0.60
{‘面包’, ‘尿布’} 支持度: 0.60
{‘牛奶’, ‘尿布’} 支持度: 0.60频繁3项集:
{‘鸡翅’, ‘牛奶’, ‘尿布’} 支持度: 0.40
{‘面包’, ‘啤酒’, ‘尿布’} 支持度: 0.40
{‘啤酒’, ‘牛奶’, ‘尿布’} 支持度: 0.40
{‘面包’, ‘牛奶’, ‘尿布’} 支持度: 0.40关联规则:
{‘鸡翅’} => {‘牛奶’}, 置信度: 1.00
{‘鸡翅’} => {‘牛奶’, ‘尿布’}, 置信度: 1.00
{‘鸡翅’, ‘牛奶’} => {‘尿布’}, 置信度: 1.00
{‘鸡翅’, ‘尿布’} => {‘牛奶’}, 置信度: 1.00
{‘鸡翅’} => {‘尿布’}, 置信度: 1.00
{‘面包’, ‘啤酒’} => {‘尿布’}, 置信度: 1.00
{‘啤酒’, ‘牛奶’} => {‘尿布’}, 置信度: 1.00
{‘啤酒’} => {‘尿布’}, 置信度: 1.00
{‘尿布’} => {‘啤酒’}, 置信度: 0.75
{‘面包’} => {‘牛奶’}, 置信度: 0.75
{‘牛奶’} => {‘面包’}, 置信度: 0.75
{‘面包’} => {‘尿布’}, 置信度: 0.75
{‘尿布’} => {‘面包’}, 置信度: 0.75
{‘牛奶’} => {‘尿布’}, 置信度: 0.75
{‘尿布’} => {‘牛奶’}, 置信度: 0.75===== 4. FP-growth 库函数版 =====
C:\DevelopmentTools\Anaconda3\envs\cloudcomputing\Lib\site-packages\mlxtend\frequent_patterns\fpcommon.py:161: DeprecationWarning: DataFrames with non-bool types result in worse computationalperformance and their support might be discontinued in the future.Please use a DataFrame with bool type
warnings.warn(
频繁1项集:
{‘面包’} 支持度: 0.80
{‘牛奶’} 支持度: 0.80
{‘尿布’} 支持度: 0.80
{‘啤酒’} 支持度: 0.60
{‘鸡翅’} 支持度: 0.40频繁2项集:
{‘面包’, ‘牛奶’} 支持度: 0.60
{‘牛奶’, ‘尿布’} 支持度: 0.60
{‘面包’, ‘尿布’} 支持度: 0.60
{‘啤酒’, ‘尿布’} 支持度: 0.60
{‘面包’, ‘啤酒’} 支持度: 0.40
{‘啤酒’, ‘牛奶’} 支持度: 0.40
{‘鸡翅’, ‘牛奶’} 支持度: 0.40
{‘鸡翅’, ‘尿布’} 支持度: 0.40频繁3项集:
{‘面包’, ‘牛奶’, ‘尿布’} 支持度: 0.40
{‘面包’, ‘啤酒’, ‘尿布’} 支持度: 0.40
{‘啤酒’, ‘牛奶’, ‘尿布’} 支持度: 0.40
{‘牛奶’, ‘鸡翅’, ‘尿布’} 支持度: 0.40关联规则:
{‘面包’} => {‘牛奶’}, 置信度: 0.75
{‘牛奶’} => {‘面包’}, 置信度: 0.75
{‘牛奶’} => {‘尿布’}, 置信度: 0.75
{‘尿布’} => {‘牛奶’}, 置信度: 0.75
{‘面包’} => {‘尿布’}, 置信度: 0.75
{‘尿布’} => {‘面包’}, 置信度: 0.75
{‘啤酒’} => {‘尿布’}, 置信度: 1.00
{‘尿布’} => {‘啤酒’}, 置信度: 0.75
{‘面包’, ‘啤酒’} => {‘尿布’}, 置信度: 1.00
{‘啤酒’, ‘牛奶’} => {‘尿布’}, 置信度: 1.00
{‘鸡翅’} => {‘牛奶’}, 置信度: 1.00
{‘鸡翅’} => {‘尿布’}, 置信度: 1.00
{‘鸡翅’, ‘牛奶’} => {‘尿布’}, 置信度: 1.00
{‘鸡翅’, ‘尿布’} => {‘牛奶’}, 置信度: 1.00
{‘鸡翅’} => {‘牛奶’, ‘尿布’}, 置信度: 1.00
4.2 完整数据集测试 (使用库算法)
(cloudcomputing) PS C:\Coding\云计算\大数据关联分析实验\src> & C:/DevelopmentTools/Anaconda3/envs/cloudcomputing/python.exe c:/Coding/云计算/大数据关联分析实验/src/market_basket_analysis.py
数据集基本信息:
RangeIndex: 21293 entries, 0 to 21292
Data columns (total 4 columns):
# Column Non-Null Count Dtype
— —— ————– —–
0 Date 21293 non-null object
1 Time 21293 non-null object
2 Transaction 21293 non-null int64
3 Item 21293 non-null object
dtypes: int64(1), object(3)
memory usage: 665.5+ KB
None前5行:
Date Time Transaction Item
0 2016-10-30 09:58:11 1 Bread
1 2016-10-30 10:05:34 2 Scandinavian
2 2016-10-30 10:05:34 2 Scandinavian
3 2016-10-30 10:07:57 3 Hot chocolate
4 2016-10-30 10:07:57 3 Jam缺失值统计:
Date 0
Time 0
Transaction 0
Item 0
dtype: int64热销商品Top15:
Item
Coffee 4528
Bread 3097
Tea 1350
Cake 983
Pastry 815
Sandwich 680
Medialuna 585
Hot chocolate 552
Cookies 515
Brownie 379
Farm House 371
Juice 365
Muffin 364
Alfajores 344
Scone 327
Name: count, dtype: int64各星期交易量:
Weekday
Monday 1128
Tuesday 1185
Wednesday 1109
Thursday 1248
Friday 1475
Saturday 2059
Sunday 1261
Name: Transaction, dtype: int64===== Apriori 频繁项集(支持度≥0.05) =====
support itemsets
2 0.478394 (Coffee)
0 0.327205 (Bread)
8 0.142631 (Tea)
1 0.103856 (Cake)
9 0.090016 (Coffee, Bread)
6 0.086107 (Pastry)
7 0.071844 (Sandwich)
5 0.061807 (Medialuna)
4 0.058320 (Hot chocolate)
10 0.054728 (Coffee, Cake)
3 0.054411 (Cookies)===== Apriori 关联规则(置信度≥0.5) =====
antecedents consequents support confidence lift
0 (Cake) (Coffee) 0.054728 0.526958 1.101515===== Apriori 关联规则(提升度>1,真实联系) =====
antecedents consequents support confidence lift
0 (Cake) (Coffee) 0.054728 0.526958 1.101515===== FP-growth 频繁项集(支持度≥0.05) =====
support itemsets
3 0.478394 (Coffee)
0 0.327205 (Bread)
6 0.142631 (Tea)
7 0.103856 (Cake)
9 0.090016 (Coffee, Bread)
4 0.086107 (Pastry)
8 0.071844 (Sandwich)
5 0.061807 (Medialuna)
1 0.058320 (Hot chocolate)
10 0.054728 (Coffee, Cake)
2 0.054411 (Cookies)===== FP-growth 关联规则(置信度≥0.5) =====
antecedents consequents support confidence lift
0 (Cake) (Coffee) 0.054728 0.526958 1.101515【业务分析建议】
- 热销商品主要为咖啡、面包等,可重点备货。
- 频繁项集和高置信度、高提升度规则显示:部分商品常被一起购买(如Coffee与Bread),可考虑捆绑销售。
- 周末交易量显著高于工作日,可在周末增加促销活动。
- FP-growth与Apriori结果高度一致,FP-growth更适合大数据场景。
5 问题和解决
5.1 关联规则手写算法与库算法结果不一致
问题表现:
- Apriori 或 FP-growth 手写版与 mlxtend 库版输出的频繁项集和关联规则不一致,部分规则缺失或支持度/置信度异常。
原因分析:
- 手写版关联规则生成函数未枚举所有前件-后件划分,导致漏掉多对一/多对多规则。
- 手写FP-growth频繁项集去重与支持度统计实现有误,导致同一项集多次出现、支持度异常,甚至出现置信度大于1的错误。
解决办法:
- 统一采用“所有非空真子集枚举”方式生成关联规则,保证与mlxtend一致。
- 用集合和字典去重并准确累计支持度,递归时只保留支持度≥min_support的项集。
- 关联规则分子分母均查同一支持度表,避免口径不一致。
5.2 mlxtend库警告与兼容性问题
问题表现:
- 运行时出现
DeprecationWarning: DataFrames with non-bool types...警告。
原因分析:
- one-hot编码输出为int类型(0/1),而mlxtend推荐用bool类型(True/False)。
解决办法:
- 在one-hot编码后加
.astype(bool),如df_onehot = df_onehot.astype(bool),消除警告并提升性能。
5.3 中文可视化乱码
问题表现:
- matplotlib输出的中文标签、商品名出现乱码。
原因分析:
- matplotlib默认字体不支持中文。
解决办法:
- 在脚本前加:pythonCopyInsert
import matplotlib matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 或 ['Microsoft YaHei'] matplotlib.rcParams['axes.unicode_minus'] = False
5.4 数据预处理与格式转换细节
问题表现:
- 购物篮数据存在缺失值、未购买项(NONE)、重复项,若不清洗会影响分析结果。
- 事务格式需转换为嵌套list才能用于mlxtend的Apriori/FP-growth。
解决办法:
- 用
dropna()、drop_duplicates()、过滤’NONE’等方式清洗数据。 - 用
groupby('Transaction')['Item'].apply(list).tolist()转换为事务列表。
5.5 业务分析与建议输出
问题表现:
- 需要将数据分析结果转化为实际业务建议。
解决办法:
- 结合频繁项集、关联规则和交易量分布,输出热销商品、捆绑销售建议、促销时机等业务洞见。