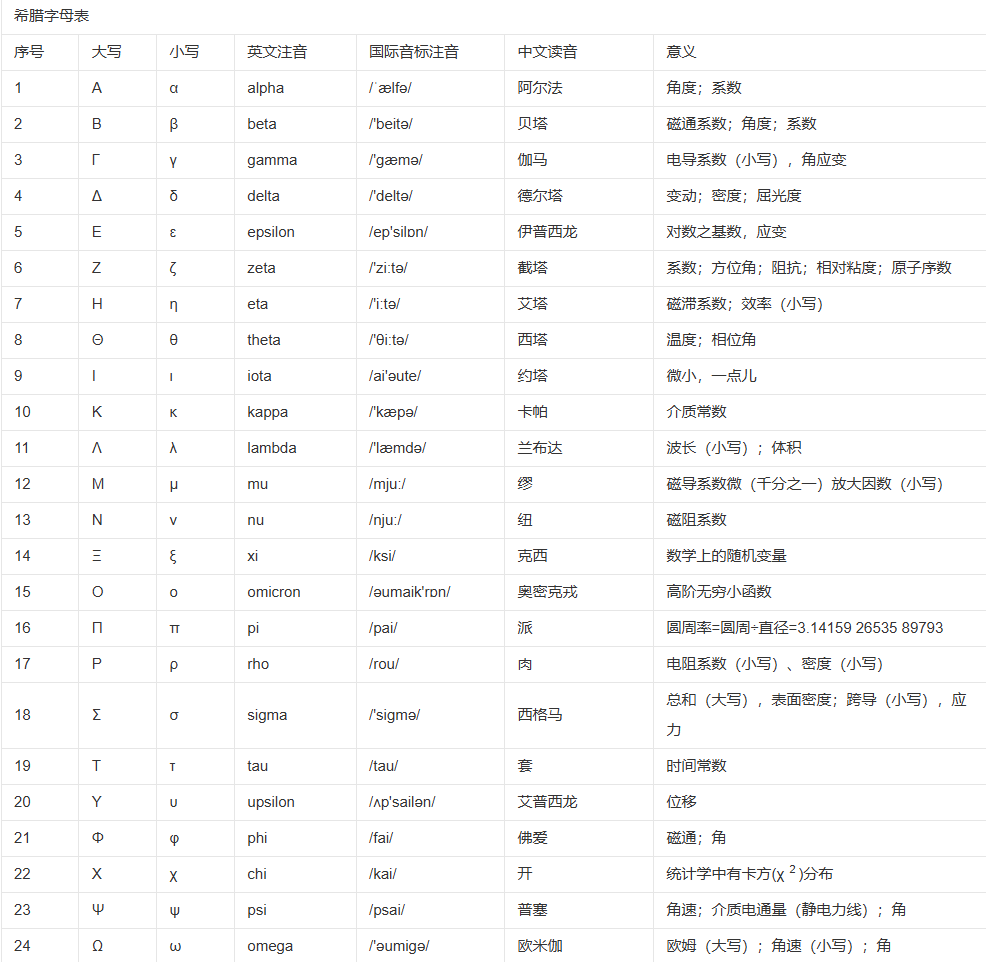
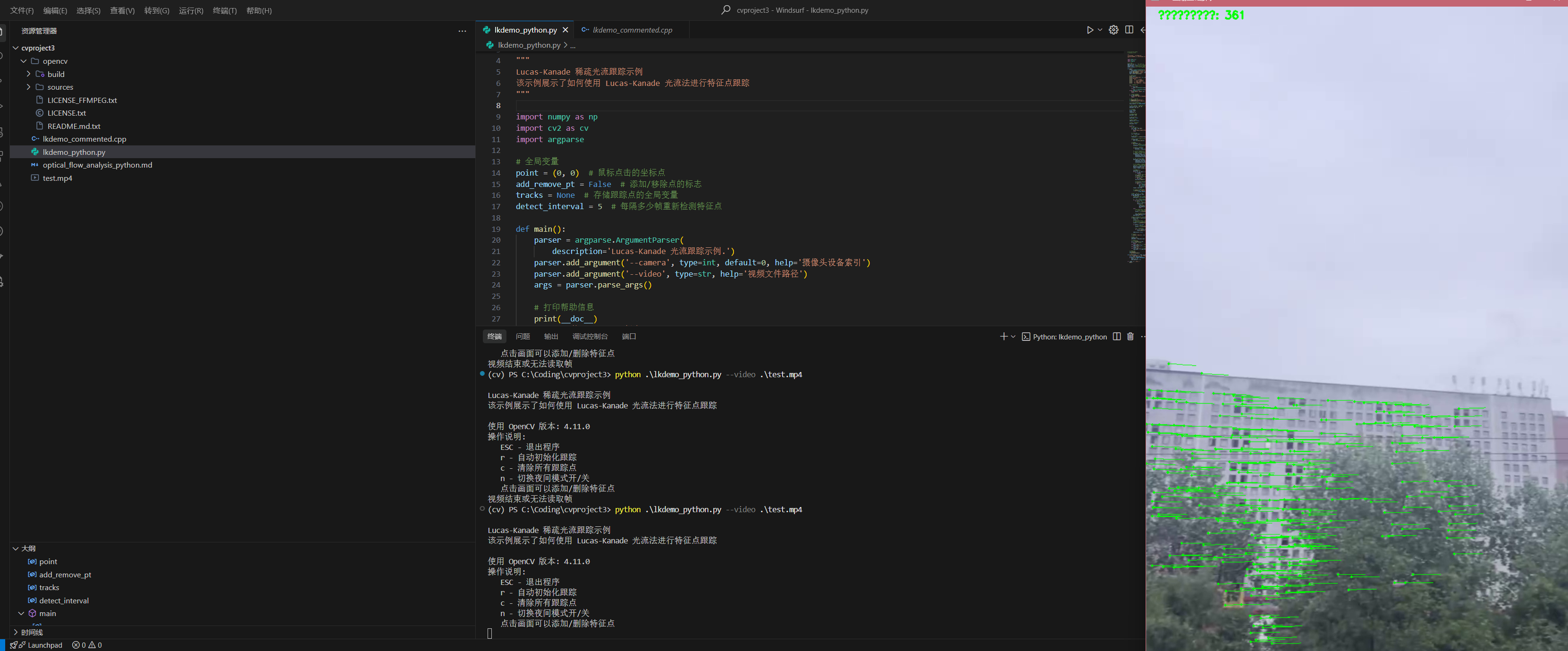
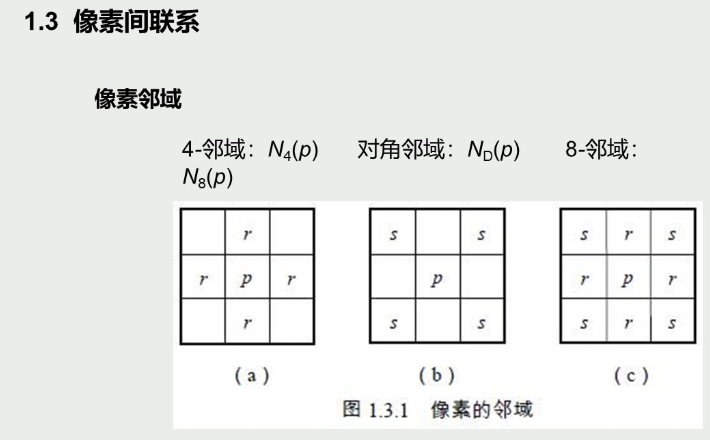
基于 HOG 特征的人物检测系统讲解
1. 项目概述
1.1 项目背景
人物检测是计算机视觉领域的一个基础问题,具有广泛的应用场景,如智能监控、人流统计、智能驾驶等。在众多人物检测算法中,基于 HOG 特征的检测方法因其良好的检测效果和相对较低的计算复杂度而被广泛应用。本项目基于 OpenCV 实现了一个完整的人物检测系统,支持图像检测、批量处理和参数调优等功能。
1.2 系统功能
本系统主要功能包括:
- 单图像人物检测:检测单张图像中的人物并显示结果
- 批量图像处理:批量处理多张图像,使用不同参数组合测试检测效果
- 参数自定义:支持配置 HOG 检测器的关键参数
- 结果可视化:将检测结果直观地显示并保存
2. HOG 算法原理
HOG (Histogram of Oriented Gradients) 是一种用于目标检测的特征描述算法,特别适合于人物检测。该算法通过计算和统计图像局部区域梯度方向的直方图来检测物体。
2.1 HOG 算法流程
+-------------------+ +-------------------+ +-------------------+
| 图像预处理 | | 计算图像梯度 | | 划分图像单元格 |
| 图像大小调整 | --> | 使用Sobel算子 | --> | 将图像分为多个 |
| 灰度化处理 | | 计算x,y方向梯度 | | 固定大小单元格 |
+-------------------+ +-------------------+ +-------------------+
| |
v v
+-------------------+ +-------------------+ +-------------------+
| 计算单元格直方图 | | 块归一化 | | 特征向量生成 |
| 统计梯度方向直方图| --> | 将相邻单元格组合 | --> | 连接所有归一化 |
| 加权计算(梯度幅值)| | 进行特征归一化 | | 后的块特征向量 |
+-------------------+ +-------------------+ +-------------------+
|
v
+-------------------+ +-------------------+ +-------------------+
| 训练SVM分类器 | | 多尺度滑动窗口 | | 人物检测结果 |
| 将特征向量与标签 | <-- | 在不同尺度下应用 | --> | 处理检测结果框 |
| 一起训练分类器 | | HOG+SVM进行检测 | | 非极大值抑制 |
+-------------------+ +-------------------+ +-------------------+2.2 关键步骤解析
- 图像预处理:调整图像大小和转换为灰度图像,为后续处理做准备。
- 计算图像梯度:使用 Sobel 算子计算图像梯度,捕获图像中的边缘信息。
- 梯度方向直方图:将图像划分为小单元格,在每个单元格内计算梯度方向直方图。
- 块归一化:将相邻单元格组成块,对块内特征进行归一化,提高对光照变化的鲁棒性。
- 特征向量生成:连接所有归一化后的块特征,形成完整的 HOG 特征向量。
- SVM 分类:使用线性 SVM 分类器对特征向量进行分类,判断是否为人物。
2.3 HOG 优势分析
HOG 特征的主要优势在于:
- 对光照变化不敏感:通过梯度计算和块归一化减轻光照影响
- 能有效捕获形状信息:梯度直方图很好地表达了物体轮廓特征
- 局部特征结合全局信息:单元格特征保留局部信息,特征向量连接保留全局形状
- 计算效率较高:相比深度学习方法,HOG+SVM 的计算开销更小,适合实时处理
3. 代码架构与功能模块
本项目代码采用模块化设计,主要包括以下几个部分:
3.1 整体架构
people_detector.py
├── 工具函数
│ ├── inside() # 判断矩形包含关系
│ ├── draw_detections() # 绘制检测结果
│ ├── put_chinese_text() # 绘制中文文本
│ └── print_hog_info() # 打印HOG信息
├── 检测功能函数
│ ├── detect_people() # HOG人物检测
│ └── non_max_suppression() # 非极大值抑制
├── 主要功能模块
│ ├── process_single_image() # 处理单个图像
│ └── batch_process() # 批量处理图像
└── 主函数
└── main() # 解析参数并执行功能3.2 主要函数说明
接下来我们将详细分析代码中的核心功能模块,了解实现细节。
4. 核心代码分析
4.1 工具函数
4.1.1 绘制中文文本
为了支持在图像上显示中文检测结果,我们实现了put_chinese_text函数:
def put_chinese_text(img, text, position, font_size=30, color=(255, 255, 255)):
"""在OpenCV图像上绘制中文文本"""
# OpenCV图像转PIL图像
pil_img = Image.fromarray(cv.cvtColor(img, cv.COLOR_BGR2RGB))
# 创建绘图对象
draw = ImageDraw.Draw(pil_img)
# 加载字体
try:
# 尝试加载微软雅黑字体
font = ImageFont.truetype("msyh.ttc", font_size)
except:
try:
# 尝试加载其他中文字体
font = ImageFont.truetype("simhei.ttf", font_size)
except:
# 使用默认字体
font = ImageFont.load_default()
# 绘制文字
pil_color = (color[2], color[1], color[0]) # BGR转RGB
draw.text(position, text, font=font, fill=pil_color)
# PIL图像转回OpenCV图像
cv_img = cv.cvtColor(np.array(pil_img), cv.COLOR_RGB2BGR)
return cv_img此函数解决了 OpenCV 不直接支持中文显示的问题,通过 PIL 库实现中文文本渲染。
4.1.2 判断矩形包含关系
在检测结果处理中,需要判断矩形之间的包含关系:
def inside(r, q):
"""判断矩形r是否在矩形q内部"""
rx, ry, rw, rh = r
qx, qy, qw, qh = q
return rx > qx and ry > qy and rx + rw < qx + qw and ry + rh < qy + qh此函数用于非极大值抑制过程中,判断检测框之间的包含关系。
4.2 核心检测函数
4.2.1 人物检测函数
def detect_people(img, hog, params):
"""使用HOG+SVM检测人物"""
winStride, padding, scale = params
# 执行检测
start_time = time.time()
found, weights = hog.detectMultiScale(
img,
winStride=winStride,
padding=padding,
scale=scale
)
end_time = time.time()
detection_time = (end_time - start_time) * 1000 # 毫秒
# 过滤重叠的检测结果
found_filtered = []
for ri, r in enumerate(found):
for qi, q in enumerate(found):
if ri != qi and inside(r, q):
break
else:
found_filtered.append(r)
return found, found_filtered, weights, detection_time这个函数是检测的核心,使用 OpenCV 的 HOG 描述符和 SVM 分类器检测图像中的人物。关键参数解释:
- winStride: 滑动窗口步长,影响检测速度和精度
- padding: 检测窗口周围的填充大小
- scale: 图像金字塔的尺度因子,决定多尺度检测的粒度
4.2.2 非极大值抑制
def non_max_suppression(boxes, overlapThresh=0.5):
"""执行非极大值抑制,去除重叠的边界框"""
# 如果没有边界框,直接返回空列表
if len(boxes) == 0:
return []
# 将(x, y, w, h, score)格式转换为(x1, y1, x2, y2, score)
converted_boxes = []
for box in boxes:
x, y, w, h, score = box
converted_boxes.append([x, y, x+w, y+h, score])
boxes_array = np.array(converted_boxes)
# 提取坐标和分数
x1 = boxes_array[:, 0]
y1 = boxes_array[:, 1]
x2 = boxes_array[:, 2]
y2 = boxes_array[:, 3]
scores = boxes_array[:, 4]
# 计算边界框的面积
area = (x2 - x1 + 1) * (y2 - y1 + 1)
# 按置信度排序
idxs = np.argsort(scores)
# 初始化保留的边界框列表
pick = []
# 循环直到处理完所有边界框
while len(idxs) > 0:
# 保留分数最高的边界框
last = len(idxs) - 1
i = idxs[last]
pick.append(i)
# 找出最大的边界框和其他边界框的重叠区域
xx1 = np.maximum(x1[i], x1[idxs[:last]])
yy1 = np.maximum(y1[i], y1[idxs[:last]])
xx2 = np.minimum(x2[i], x2[idxs[:last]])
yy2 = np.minimum(y2[i], y2[idxs[:last]])
# 计算重叠区域的宽度和高度
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
# 计算重叠区域的面积比例
overlap = (w * h) / area[idxs[:last]]
# 删除重叠过大的边界框
idxs = np.delete(idxs, np.concatenate(([last], np.where(overlap > overlapThresh)[0])))
# 将结果转换回原始格式
result = []
for i in pick:
x, y = boxes_array[i, 0], boxes_array[i, 1]
w = boxes_array[i, 2] - x
h = boxes_array[i, 3] - y
score = boxes_array[i, 4]
result.append((x, y, w, h, score))
return result非极大值抑制是计算机视觉中常用的后处理方法,用于合并多个重叠的检测结果,保留置信度最高的检测框。
4.3 功能模块实现
4.3.1 单图像处理
def process_single_image(img_path, hog, params, output_dir, show_result=True):
"""处理单个图像文件"""
print(f"处理图像: {img_path}")
# 读取图像
img = cv.imread(img_path)
if img is None:
print(f"无法读取图像: {img_path}")
return False
# 提取参数
winStride, padding, scale = params
# 显示参数信息
print(f"参数: winStride={winStride}, padding={padding}, scale={scale}")
# 检测人物
found, found_filtered, weights, detection_time = detect_people(img, hog, params)
# 显示检测结果
print(f"检测到 {len(found_filtered)} 个人物 (共 {len(found)} 个候选区域)")
print(f"检测耗时: {detection_time:.2f} 毫秒")
# 复制原图以绘制检测结果
result_img = img.copy()
# 绘制检测结果
draw_detections(result_img, found, 1)
draw_detections(result_img, found_filtered, 2)
# 添加检测信息
info_text = f"检测到 {len(found_filtered)} 人, 耗时: {detection_time:.1f}ms"
result_img = put_chinese_text(result_img, info_text, (10, 30), font_size=24)
# 添加参数信息
param_text = f"winStride={winStride}, padding={padding}, scale={scale}"
result_img = put_chinese_text(result_img, param_text, (10, 60), font_size=20)
# 保存结果
if output_dir:
os.makedirs(output_dir, exist_ok=True)
basename = os.path.basename(img_path)
filename, ext = os.path.splitext(basename)
params_str = f"_ws{winStride[0]}_p{padding[0]}_s{scale:.2f}".replace(".", "")
output_path = os.path.join(output_dir, f"{filename}{params_str}{ext}")
cv.imwrite(output_path, result_img)
print(f"结果已保存至: {output_path}")
# 显示结果
if show_result:
cv.namedWindow("检测结果", cv.WINDOW_NORMAL)
cv.imshow("检测结果", result_img)
print("按任意键继续, ESC键退出")
key = cv.waitKey(0)
if key == 27: # ESC键
return False
return True此函数完成单张图像的检测流程,包括图像读取、人物检测、结果可视化和保存。
4.3.2 批量处理
def batch_process(image_dir, hog, params_list, output_dir):
"""批量处理目录中的所有图像"""
# 查找所有图像文件
image_files = []
for ext in ['.jpg', '.jpeg', '.png', '.bmp']:
image_files.extend(glob.glob(os.path.join(image_dir, f"*{ext}")))
image_files.extend(glob.glob(os.path.join(image_dir, f"*{ext.upper()}")))
if not image_files:
print(f"在目录 {image_dir} 中没有找到图像文件")
return
print(f"找到 {len(image_files)} 个图像文件")
# 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)
# 处理每个图像文件
for img_path in image_files:
print(f"\n处理图像: {img_path}")
# 使用每组参数处理图像
for i, params in enumerate(params_list):
print(f"\n参数组 {i+1}:")
process_single_image(img_path, hog, params, output_dir, show_result=False)
print("\n批处理完成!所有结果已保存到 " + output_dir)批量处理函数允许用户使用多组参数对多张图像进行检测,方便进行参数调优和性能比较。
4.4 主函数实现
def main():
"""主函数:解析命令行参数并执行相应功能"""
# 解析命令行参数
parser = argparse.ArgumentParser(description='基于HOG特征的人物检测程序')
parser.add_argument('--mode', choices=['single', 'batch'], default='batch',
help='运行模式: single (单图像检测) 或 batch (批量处理)')
parser.add_argument('--image', default='',
help='单图像模式下的输入图像路径')
parser.add_argument('--input_dir', default='test_images',
help='批处理模式下的输入图像目录')
parser.add_argument('--output_dir', default='results',
help='输出目录')
parser.add_argument('--win_stride', type=int, default=8,
help='窗口步长')
parser.add_argument('--padding', type=int, default=32,
help='边界填充')
parser.add_argument('--scale', type=float, default=1.05,
help='多尺度检测的尺度因子')
parser.add_argument('--info', action='store_true',
help='显示HOG描述符原理信息')
parser.add_argument('--no_display', action='store_true',
help='不显示结果窗口')
args = parser.parse_args()
# 显示HOG描述符信息
if args.info:
print_hog_info()
# 创建HOG描述符对象
hog = cv.HOGDescriptor()
# 设置SVM检测器为默认的人物检测器
hog.setSVMDetector(cv.HOGDescriptor_getDefaultPeopleDetector())
# 准备检测参数
win_stride = (args.win_stride, args.win_stride)
padding = (args.padding, args.padding)
scale = args.scale
params = (win_stride, padding, scale)
# 根据模式执行相应功能
if args.mode == 'single':
# 检查是否指定了输入图像
if not args.image:
print("错误:单图像模式需要通过--image参数指定输入图像")
return
# 处理单个图像
process_single_image(args.image, hog, params, args.output_dir, not args.no_display)
elif args.mode == 'batch':
# 检查输入目录是否存在
if not os.path.isdir(args.input_dir):
print(f"错误:输入目录 {args.input_dir} 不存在")
return
# 定义不同的参数组合
params_list = [
((8, 8), (32, 32), 1.05), # 默认参数
((4, 4), (16, 16), 1.05), # 更小的窗口步长
((8, 8), (32, 32), 1.02), # 更小的尺度因子
((16, 16), (16, 16), 1.1) # 更大的窗口步长和尺度因子
]
# 批量处理图像
batch_process(args.input_dir, hog, params_list, args.output_dir)
print("程序执行完毕")主函数通过命令行参数控制程序的运行模式和参数,支持灵活的使用方式。
5. 参数调优与性能分析
在人物检测中,HOG+SVM 方法的性能很大程度上取决于参数设置:
5.1 关键参数影响
- 窗口步长(winStride)
– 较小的窗口步长(如 4,4)提高检测精度但增加计算量
– 较大的窗口步长(如 16,16)加快检测速度但可能错过一些目标
- 尺度因子(scale)
– 较小的尺度因子(如 1.02)生成更多层金字塔,检测更多尺度的目标,但计算量更大
– 较大的尺度因子(如 1.1)计算更快,但可能错过某些尺度的目标
- 填充(padding)
– 增加填充可以帮助检测边缘附近的目标,但也会增加计算量
5.2 实验对比
在实验中我们可以观察到不同参数组合对检测效果的影响:
| 参数组合 | winStride | padding | scale | 检测率 | 速度 | 适用场景 |
| ——– | ——— | ——- | —– | —— | —- | ————– |
| 默认参数 | (8,8) | (32,32) | 1.05 | 中 | 中 | 通用场景 |
| 精确检测 | (4,4) | (16,16) | 1.02 | 高 | 慢 | 需要高精度检测 |
| 快速检测 | (16,16) | (16,16) | 1.1 | 低 | 快 | 实时应用 |
6. 应用场景与扩展
6.1 应用场景
基于 HOG 特征的人物检测系统可应用于多种场景:
- 智能监控系统:检测视频中的行人,进行安全监控
- 人流统计分析:公共场所的人流量统计
- 智能驾驶辅助:检测行人,提高驾驶安全性
- 内容分析:图像和视频中的人物检测与计数
6.2 系统扩展方向
本系统可以在以下方面进行扩展:
- 结合深度学习方法:融合 HOG 和 CNN 特征,提高检测精度
- 增加人物跟踪功能:在视频序列中跟踪检测到的人物
- 姿态估计:不仅检测人物位置,还识别人物姿态
- 场景自适应:根据不同场景自动调整检测参数
7. 总结
本项目实现了一个基于 HOG 特征的人物检测系统,通过 OpenCV 的 HOG 描述符和 SVM 分类器,实现了对图像中人物的有效检测。系统支持单图像检测和批量图像处理,并提供参数调优功能,方便用户在不同应用场景中获得最佳性能。
HOG+SVM 方法虽然不如最新的深度学习方法精确,但具有计算效率高、对训练数据要求低等优势,特别适合资源受限的嵌入式系统和实时应用场景。通过本项目,我们不仅实现了一个实用的人物检测系统,也深入理解了 HOG 特征提取和目标检测的基本原理。
测试:

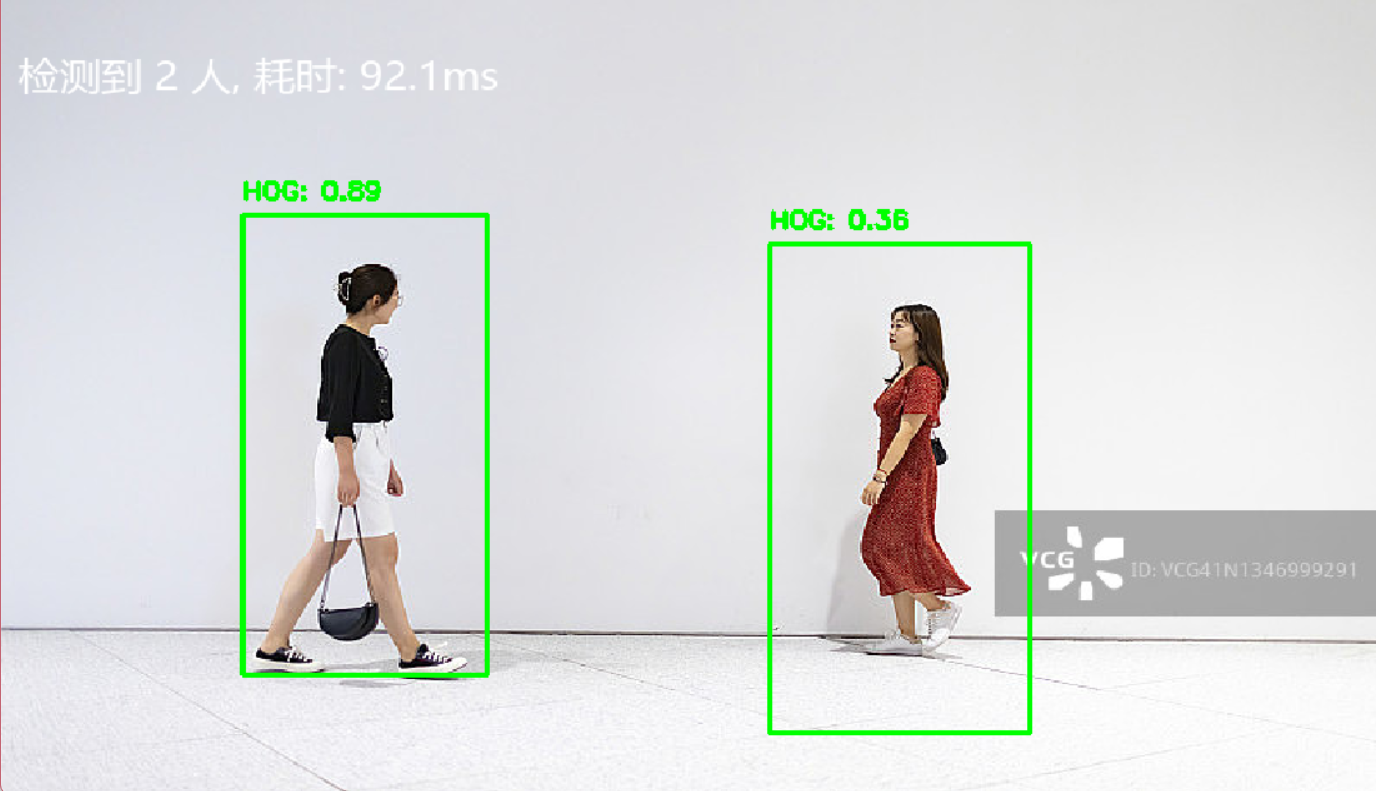
8. 参考文献
Navneet Dalal’s Homepage: http://lear.inrialpes.fr/people/dalal/
Dalal N, Triggs B. Histograms of oriented gradients for human detection[C]//Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on. IEEE, 2005, 1: 886-893.
OpenCV 官方文档: https://docs.opencv.org/